 Java8流式编程详解
Java8流式编程详解
# 简介
java8提供的流式编程使得我们对于集合的处理不再是临时集合加上各种还能for循环,取而代之的是更加简洁高效的流水线操作,所以笔者就以这篇文章总结一下流式编程中常见的操作。
# 前置铺垫
后文示例操作中,我们都会基于这个菜肴类的集合展开,对于菜肴类的代码如下:
public class Dish {
/**
* 名称
*/
private final String name;
/**
* 是否是素食
*/
private final boolean vegetarian;
/**
* 卡路里
*/
private final int calories;
/**
* 类型
*/
private final Type type;
//类型枚举 分别是是:肉类 鱼类 其他
public enum Type {MEAT, FISH, OTHER}
public Dish(String name, boolean vegetarian, int calories, Type type) {
this.name = name;
this.vegetarian = vegetarian;
this.calories = calories;
this.type = type;
}
public String getName() {
return name;
}
public boolean isVegetarian() {
return vegetarian;
}
public int getCalories() {
return calories;
}
public Type getType() {
return type;
}
@Override
public String toString() {
return name;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
同理我们也给出集合声明和初始化代码段:
public static final List<Dish> menu =
Arrays.asList(new Dish("pork", false, 800, Dish.Type.MEAT),
new Dish("beef", false, 700, Dish.Type.MEAT),
new Dish("chicken", false, 400, Dish.Type.MEAT),
new Dish("french fries", true, 530, Dish.Type.OTHER),
new Dish("rice", true, 350, Dish.Type.OTHER),
new Dish("season fruit", true, 120, Dish.Type.OTHER),
new Dish("pizza", true, 550, Dish.Type.OTHER),
new Dish("prawns", false, 400, Dish.Type.FISH),
new Dish("salmon", false, 450, Dish.Type.FISH));
2
3
4
5
6
7
8
9
10
# 元素的筛选
# 常规过滤筛选
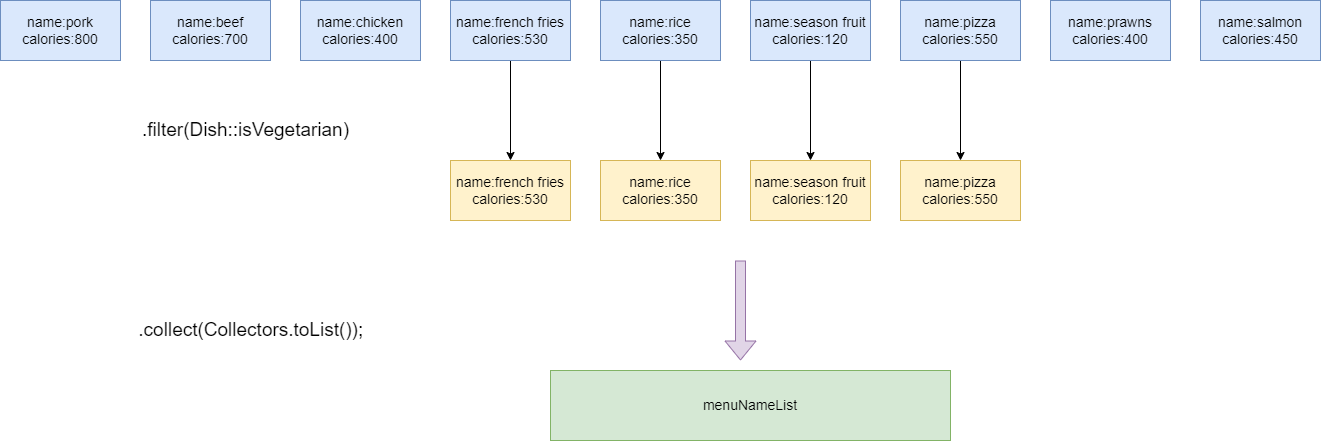
菜肴类的vegetarian这个布尔值决定了菜肴是否为蔬菜,我们希望从这个集合中找到所有的蔬菜并返回一个list。
此时,我们就可以使用filter,它要求传入一个表达式,最终返回一个布尔值,所以我们直接将Dish的isVegetarian传入,如果是蔬菜则返回true,进入下一个流水线操作,反之则直接淘汰这个元素:
public static void main(String[] args) {
List<Dish> vegetarianMenu =
menu.stream()
//使用filter 结合函数式编程筛选出vegetarian 为true的菜肴
.filter(Dish::isVegetarian)
//将这些流组成一个list数组
.collect(toList());
//遍历vegetarianMenu
vegetarianMenu.forEach(System.out::println);
}
2
3
4
5
6
7
8
9
10
11
最终输出结果如下,符合预期:
french fries
rice
season fruit
pizza
2
3
4
这种写法写起来就像SQL语句一样,我们无需各种for循环的声明指令,而是像是一种声明式的操作,而流的工作原理也如下图所示,将每一个元素放到流式操作的流水线上,符合预期的存入list,不符合预期的淘汰:
# 找出不重复元素
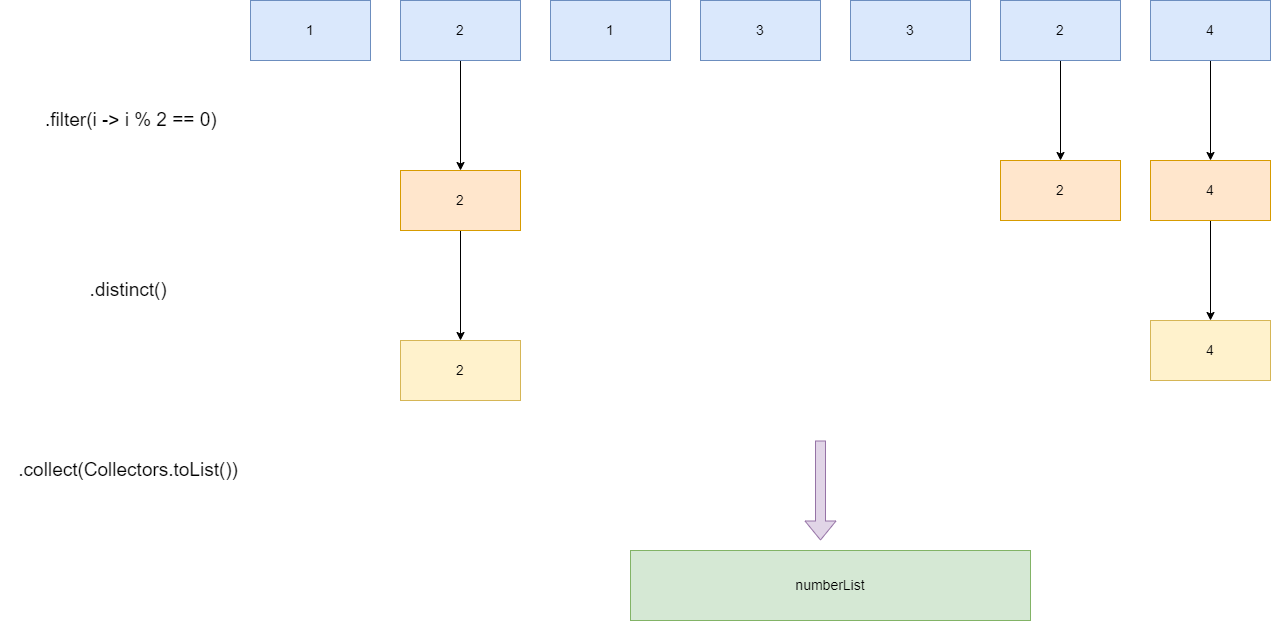
我们现在有一个无序且包含重复元素的整型数组,代码如下所示,希望能从中筛选出能够被2整除的数字并构成一个list集合:
List<Integer> numbers = Arrays.asList(1, 2, 1, 3, 3, 2, 4);
在java8之前,你的编码思路可能会是:
- for循环找到被2整除的元素。
- 将该元素存到set中。
- 将set转转为list。
java8之后我们无需这么繁琐,我们只需针对流进行如下操作:
- 拿到集合流。
- 使用filter过滤出被2整除的元素,传到流水线下一步工序。
- 使用distinct判断是否重复。
- 存入list中。
对应代码如下:
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(1, 2, 1, 3, 3, 2, 4);
List<Integer> integerList = numbers.stream()
//过滤出能够被2整除的数字
.filter(i -> i % 2 == 0)
//去重
.distinct()
//循环遍历
.collect(Collectors.toList());
//遍历输出结果
for (Integer integer : integerList) {
System.out.println(integer);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
查看其输出结果,也是符合预期的:
2
4
2
再来看看流的工作图,他的操作也同样如流水线一般,我们这里就以数字1和数字2为例讲解一下流的工作过程:
- 流拿到数字1,走到
filter表达式,返回false,直接淘汰。 - 流拿到数字2,走到
filter表达式,返回true,走到下一个操作。 - 数字2执行
distinct,不重复,进入下一个操作。 - 数字2存入
list中。 - 流再次拿到数字2,走到
filter表达式,返回true,走到下一个操作。 - 数字2执行
distinct,重复,直接淘汰。
总的来说,流水编程之所以高效是因为它的流水线对于不符合要求的元素会直接过滤,相对于指令时的按部就班进行简洁许多:
# 限制筛选元素
以上文的菜肴集合为例,我们希望找到热量大于300卡的前3道菜,如果在java8之前,你一定的for循环加上一个count变量,当找到三道菜了就停止循环。
而java8提供了语义化的操作limit方法,我们只需通过filter找到大于300卡的菜肴后,直接使用limit就可以完成限制筛选了
public static void main(String[] args) {
List<Dish> menuList = menu.stream()
//过滤出300卡的菜肴
.filter(d -> d.getCalories() > 300)
//筛选出最先3个符合预期的菜肴
.limit(3)
.collect(toList());
for (Dish dish : menuList) {
System.out.println(dish);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
对应的输出结果如下,符合预期:
pork
beef
chicken
2
3
# 跳过某些元素进行筛选
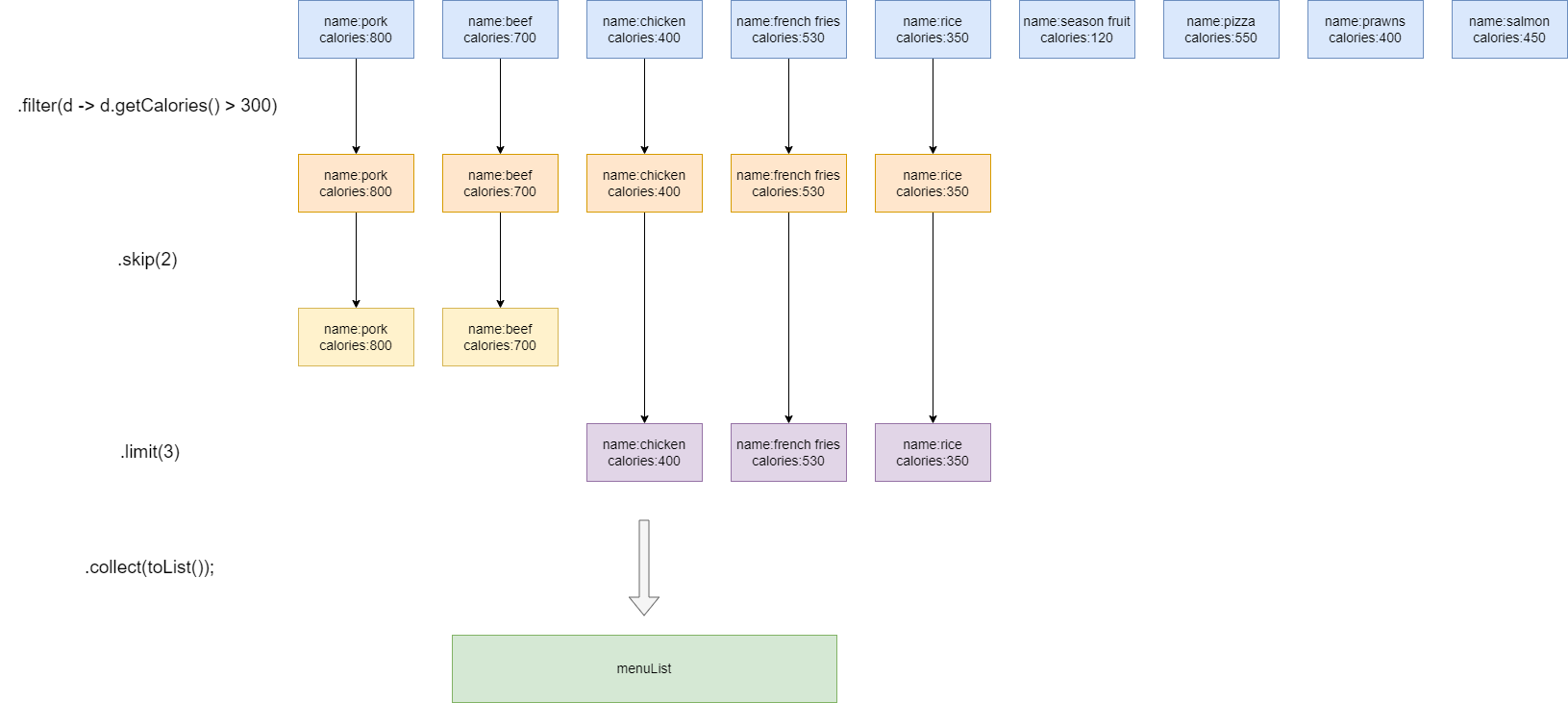
我们希望跳过前两个高于300卡的菜,再筛选出3道高于300卡的菜肴又该怎么办呢?对于java8而言,只需加一个skip操作即可完成这个需求:
public static void main(String[] args) {
List<Dish> menuList = menu.stream()
//过滤出300卡的菜肴
.filter(d -> d.getCalories() > 300)
//跳过前两道热量高于300卡的菜
.skip(2)
//筛选出最先3个符合预期的菜肴
.limit(3)
.collect(toList());
for (Dish dish : menuList) {
System.out.println(dish);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
从输出结果来看,确实高于300卡的前两个被剔除,然后再筛选出前3个元素:
chicken
french fries
rice
2
3
对应的原理图如下所示,可以看到经过filter表达式后,前两个高于300卡的元素直接被剔除:
# 映射
# 映射转换
映射操作其实也很好理解,就像使用sql语句一样通过select出你所需要的字段,例如我们希望从菜肴中拿到所有菜肴的名字,如果在java8之前,你一定会声明一个List<String>的临时集合,然后遍历菜肴集合,获取到每个菜肴的名字,添加到List<String>这个集合中。
java8直接基于map方法即可映射出自己所需要的成员属性,结合终端操作collect(toList())即可直接将映射结果转为list,避免了用户创建临时集合等繁琐操作:
public static void main(String[] args) {
List<String> dishNames = menu.stream()
//拿到每一个菜肴的名字
.map(Dish::getName)
//存入list集合中
.collect(toList());
for (String dishName : dishNames) {
System.out.println(dishName);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
输出结果:
pork
beef
chicken
french fries
rice
season fruit
pizza
prawns
salmon
2
3
4
5
6
7
8
9
# 映射扁平化
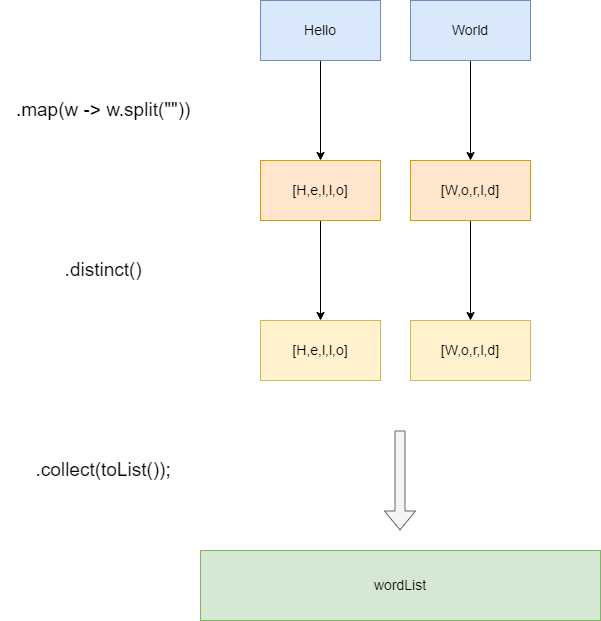
我们有 List<String> 的单词数组,我们希望找出数组中所有不重复的字母并输出,对应的单词数组定义如下:
List<String> words = Arrays.asList("Hello", "World");
这时候你第一时间可能想到这样,将数组中每个单词切成一个个字母,然后distinct去重,最后转成list输出
public static void main(String[] args) {
List<String> words = Arrays.asList("Hello", "World");
List<String[]> resultList = words.stream()
//这里映射的是stream<String[]> 后续的中间操作没有什么作用
.map(w -> w.split(""))
.distinct()
.collect(toList());
for (String[] strings : resultList) {
for (String string : strings) {
System.out.print(string);
}
System.out.println();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
可以看到,这样的做法,最终得到的是一个 List<String[]>,代码如下,其工作原理也很好解释,map(w -> w.split(""))会将hello World分别切割成String[],然后两个String[],很显然对一个数组distinct自然是没有任何作用的:
打印以下输出结果
Hello
World
2
所以我们希望map操作后的数组转为String的stream流,于是我们就有了第2个版本的写法,我们通过map(Arrays::stream),意将切割后的string[]转为Stream<String>再进行去重:
public static void main(String[] args) {
List<String> words = Arrays.asList("Hello", "World");
List<Stream<String>> list = words.stream()
.map(w -> w.split(""))
//将stream<String[]>转为stream<String> 但还是没有解决问题 因为将数组变成string流
.map(Arrays::stream)
.distinct()
.collect(toList());
for (Stream<String> stream : list) {
List<String> stringList = stream.collect(Collectors.toList());
for (String s : stringList) {
System.out.print(s);
}
System.out.println();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
,但是去重再转为数组后得到类型却是 List<Stream<String>>,这意味着我们只是将两个单词转为两个独立的stream<String>:
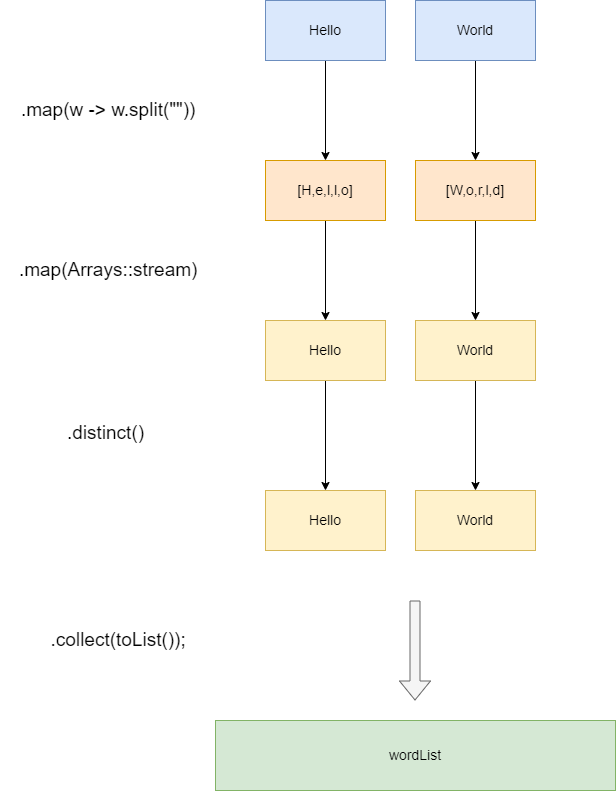
所以我们需要更进一步的操作,来看看正确的写法,通过flatMap调用Arrays::stream,即可完成将两个独立的Stream<String>合并成一个扁平的Stream<String>最终得到正确结果,他的工作流程图也如下图所示
public static void main(String[] args) {
List<String> words = Arrays.asList("Hello", "World");
List<String> wordList = words.stream()
.map(w -> w.split(""))
//将数组扁平化合并为流
.flatMap(Arrays::stream)
.distinct()
.collect(toList());
for (String s : wordList) {
System.out.println(s);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
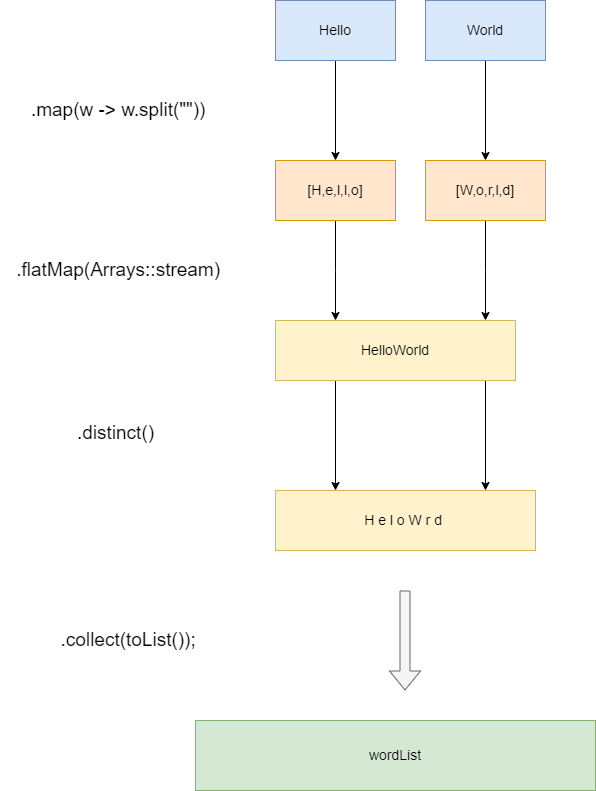
最终输出结果如下,符合预期:
H e l o W r d
2
需要补充的是,对于扁平化的代码我们可以简化,我们可以直接通过表达式拿到集合中的元素在进行切割、扁平化操作:
words.stream()
.flatMap((String line) -> Arrays.stream(line.split("")))
.distinct()
.forEach(System.out::println);
2
3
4
# 查找和匹配
# 检查是否至少匹配一个元素
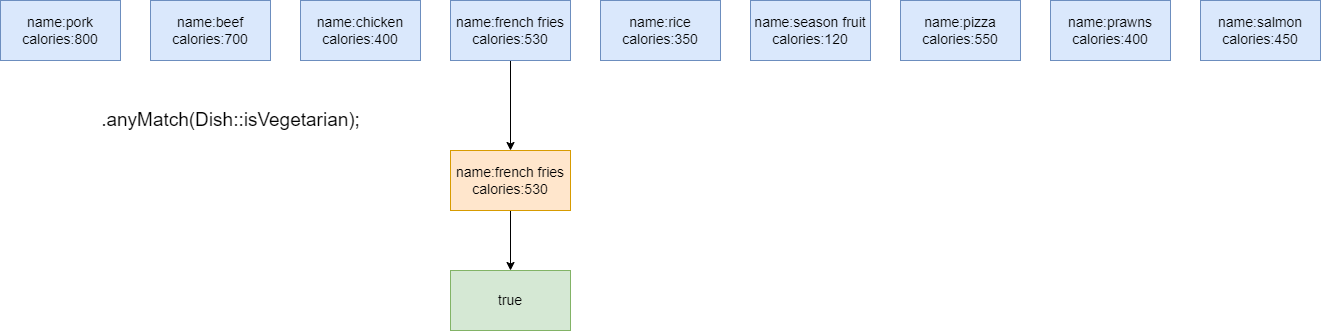
我想知道菜肴集合中是否存在素菜,就可以使用anyMatch方法,该方法是一个终端操作,他将返回一个boolean值,只要集合中看到一个素食的菜肴,那么这样流操作就会返回true:
public static void main(String[] args) {
System.out.println(menu.stream().anyMatch(Dish::isVegetarian));
}
2
3
输出结果:
true
通过peek方法查看anyMatch工作流程:
public static void main(String[] args) {
menu.stream()
.peek(m -> System.out.println(m))
.anyMatch(Dish::isVegetarian);
}
2
3
4
5
6
从peek的输出结果来看,anyMatch只要匹配到符合要求的元素之后,就立即停止并关闭流了:
pork
beef
chicken
french fries
2
3
4
anyMatch的工作流程:
# 检查流元素是否都匹配
同理如果需要全部匹配,我们就用allMatch,例如我们需要判断菜肴中的菜肴是否都是低于1000卡的,我们完全可以这样写:
menu.stream()
.allMatch(d -> d.getCalories() < 1000);
2
# 检查流元素是否都不都匹配
反过来来说,我们可以要找低于1000卡的,同样我们也可以使用下面这样的写法,判断是否不包含高于1000卡的菜肴
menu.stream()
.noneMatch(d -> d.getCalories() >= 1000);
2
# 查找元素
我们希望找出菜肴中是否包含素食,如果有则告知查到的素食是什么菜,我们就可以通过使用findAny方法做到这一点:
public static void main(String[] args) {
Optional<Dish> optionalDish = menu.stream()
.filter(Dish::isVegetarian)
//只要找到符合要求的菜肴,就直接停止并关闭流
.findAny();
//如果可以找到符合要求的元素,则直接输出打印
if (optionalDish.isPresent()){
System.out.println(optionalDish.get());
}
}
2
3
4
5
6
7
8
9
10
11
12
13
但是细心的读者看到了返回值竟然不是Dish而是Optional<Dish>,所以我们需要补充以下Optional的相关概念:
Optional有个isPresent()方法,就以本例来说,假如集合中包含素食,我们调用这个方法就会返回true,说明找到了素食,反之返回falseget()方法,以本示例来说,假如找到了素食,get就会返回菜肴对象,若没找到则报出NoSuchElement异常orElse()相比上一个方法更加友好,假如我们找到值就返回值,反之就返回orElse传入的参数值。
输出结果:
french fries
# 查找第一个元素
相比于查找元素,查找第一个元素语义化更加明显,例如我们想找到第一道素食,我们就可以使用findFirst,实际上关于findAny和findFirst的使用场景区别不大,但是在并行的情况下,你想找到第一道素食的话,建议你使用findFirst,反之使用findAny即可,因为它使用并行流来说限制较少一些:
public static void main(String[] args) {
Optional<Dish> optionalDish = menu.stream()
.filter(Dish::isVegetarian)
//只要找到符合要求的菜肴,就直接停止并关闭流
.findFirst();
//如果可以找到符合要求的元素,则直接输出打印
if (optionalDish.isPresent()){
System.out.println(optionalDish.get());
}
}
2
3
4
5
6
7
8
9
10
11
12
13
# 规约
# 元素求和
在java8之前,元素求和计算都需要经过这三步:
- 创建
sum变量。 - 遍历集合,取出集合元素。
- 元素就和。
java8之后我们只需使用reduce结合求和表达式即可实现元素求和:
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(4, 5, 3, 9);
//起始数字为0,将列表中的元素全部累加
int res = numbers.stream()
.reduce(0, (sum, num) ->sum+num);
//输出结果
System.out.println(res);
}
2
3
4
5
6
7
8
9
输出结果如下:
21
其工作原理如下图所示,即以我们传入的identity作为起始值,遍历列表中的每个数字与其进行累加:
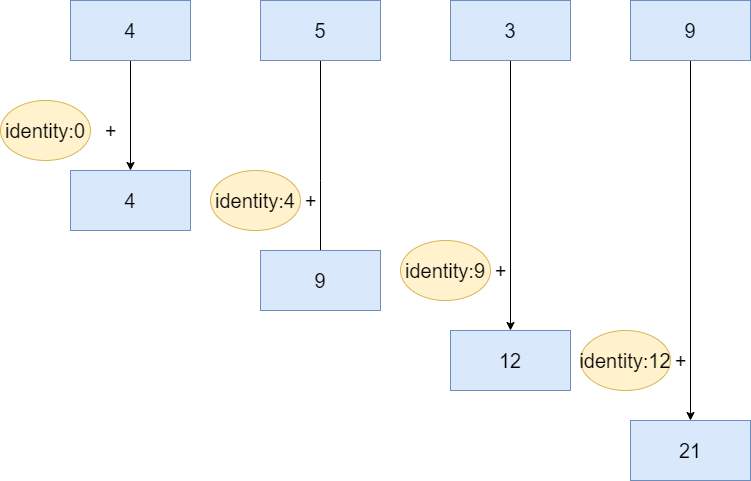
基于上述代码我们使用Integer内置的一个相加的方法sum,于是代码就可以简化成下面这样:
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(4, 5, 3, 9);
//起始数字为0,将列表中的元素全部累加
int res = numbers.stream()
.reduce(0, Integer::sum);
//输出结果
System.out.println(res);
}
2
3
4
5
6
7
8
9
假如你的统计操作无需初始值的话,也可以像下文这种写法,这正是java8的高明之处,返回一个Optional操作,让你有余地进行判空操作
·//无需初始值
Optional<Integer> res = numbers.stream().reduce(Integer::sum);
System.out.println(res.get());
2
3
# 求最大值和最小值
最大值和最小值做法和上文差不多,同样是基于reduce结合最大值或者最小值方法即可:
//求最大值
int max = numbers.stream().reduce(0, (a, b) -> Integer.max(a, b));
System.out.println(max);
//求最最小值
Optional<Integer> min = numbers.stream().reduce(Integer::min);
min.ifPresent(System.out::println);
2
3
4
5
6
# 实践题
就以博客最早提到的菜肴类,我们希望用流式编程统计出菜肴的数量,可以看到笔者的做法很巧妙,通过映射将每道菜计算为1,传到reduce流中统计计算
Optional<Integer> menuCount = menu.stream()
.map(d -> 1)
.reduce(Integer::sum);
System.out.println(menuCount.get());
2
3
4
我们甚至可以简写成这样,因为java8为我们提供了这样的终端操作
long count = menu.stream().count();
System.out.println(count);
2
# 实践
# 需求描述
我们首先定义一个交易员的类,该类描述了交易员的姓名和居住城市:
public class Trader {
/**
* 姓名
*/
private String name;
/**
* 居住城市
*/
private String city;
public Trader(String n, String c) {
this.name = n;
this.city = c;
}
public String getName() {
return this.name;
}
public String getCity() {
return this.city;
}
public void setCity(String newCity) {
this.city = newCity;
}
public String toString() {
return "Trader:" + this.name + " in " + this.city;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
还有一个交易订单类,它描述了订单的交易年份、交以金额、和交易这笔订单的人员:
public class Transaction{
/**
* 交易员
*/
private Trader trader;
/**
* 交易年份
*/
private int year;
/**
* 交以金额
*/
private int value;
public Transaction(Trader trader, int year, int value)
{
this.trader = trader;
this.year = year;
this.value = value;
}
public Trader getTrader(){
return this.trader;
}
public int getYear(){
return this.year;
}
public int getValue(){
return this.value;
}
public String toString(){
return "{" + this.trader + ", " +
"year: "+this.year+", " +
"value:" + this.value +"}";
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
用这两个类,构成了一个关于订单的列表:
//4个交易员
Trader raoul = new Trader("Raoul", "Cambridge");
Trader mario = new Trader("Mario", "Milan");
Trader alan = new Trader("Alan", "Cambridge");
Trader brian = new Trader("Brian", "Cambridge");
//4个交易员的订单总表
List<Transaction> transactions = Arrays.asList(
new Transaction(brian, 2011, 300),
new Transaction(raoul, 2012, 1000),
new Transaction(raoul, 2011, 400),
new Transaction(mario, 2012, 710),
new Transaction(mario, 2012, 700),
new Transaction(alan, 2012, 950)
);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 问题
基于上述代码,我们给出下面几道问题:
(1) 找出2011年发生的所有交易,并按交易额排序(从低到高)。
(2) 交易员都在哪些不同的城市工作过?
(3) 查找所有来自于剑桥的交易员,并按姓名排序。
(4) 返回所有交易员的姓名字符串,按字母顺序排序。
(5) 有没有交易员是在米兰工作的?
(6) 打印生活在剑桥的交易员的所有交易额。
(7) 所有交易中,最高的交易额是多少?
(8) 找到交易额最小的交易。
# 对应答案
上述8个问题笔者都已给出答案,读者在练习完成后可自行核对:
问题1:
List<Transaction> tr2011 = transactions.stream()
.filter(transaction -> transaction.getYear() == 2011)
.sorted(comparing(Transaction::getValue))
.collect(toList());
System.out.println(tr2011);
//找出2011年发生的所有交易,并按交易额排序(从低到高)
List<Transaction> transactions_2011 = transactions.stream()
.filter(t -> t.getYear() == 2011)
.sorted(comparing(Transaction::getValue))
.collect(toList());
System.out.println(transactions_2011);
2
3
4
5
6
7
8
9
10
11
问题2:
List<String> cities =
transactions.stream()
.map(transaction -> transaction.getTrader().getCity())
.distinct()
.collect(toList());
System.out.println(cities);
//交易员都在哪些不同的城市工作过
List<String> citys = transactions.stream()
.map(Transaction::getTrader)
.map(Trader::getCity)
.distinct()
.collect(toList());
System.out.println(citys);
2
3
4
5
6
7
8
9
10
11
12
13
14
问题3:
List<Trader> traders =
transactions.stream()
.map(Transaction::getTrader)
.filter(trader -> trader.getCity().equals("Cambridge"))
.distinct()
.sorted(comparing(Trader::getName))
.collect(toList());
System.out.println(traders);
//查找所有来自于剑桥的交易员,并按姓名排序
List<Trader> cambridgeTraders = transactions.stream()
.map(Transaction::getTrader)
.filter(t -> "Cambridge".equals(t.getCity()))
.distinct()
.sorted(comparing(Trader::getName))
.collect(toList());
System.out.println(cambridgeTraders);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
问题4:
String traderStr =
transactions.stream()
.map(transaction -> transaction.getTrader().getName())
.distinct()
.sorted()
.reduce("", (n1, n2) -> n1 + n2);
System.out.println(traderStr);
//返回所有交易员的姓名字符串,按字母顺序排序。×
String names = transactions.stream()
.map(Transaction::getTrader)
.map(Trader::getName)
.distinct()
.sorted()
.reduce("", (s1, s2) -> s1 + s2);
System.out.println(names);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
问题5:
boolean milanBased =
transactions.stream()
.anyMatch(transaction -> transaction.getTrader()
.getCity()
.equals("Milan")
);
System.out.println(milanBased);
//(5) 有没有交易员是在米兰工作的?
boolean hasMilan = transactions.stream()
.anyMatch(t -> "Milan".equals(t.getTrader().getCity()));
2
3
4
5
6
7
8
9
10
11
12
问题6:
transactions.stream()
.map(Transaction::getTrader)
.filter(trader -> trader.getCity().equals("Milan"))
.forEach(trader -> trader.setCity("Cambridge"));
System.out.println(transactions);
//(6) 打印生活在剑桥的交易员的所有交易额。
Optional<Integer> sum = transactions.stream()
.filter(t -> "Cambridge".equals(t.getTrader().getCity()))
.map(Transaction::getValue)
.reduce(Integer::sum);
System.out.println(sum.get());
2
3
4
5
6
7
8
9
10
11
问题7:
int highestValue =
transactions.stream()
.map(Transaction::getValue)
.reduce(0, Integer::max);
System.out.println(highestValue);
//(7) 所有交易中,最高的交易额是多少?
Optional<Integer> max = transactions.stream()
.map(Transaction::getValue)
.reduce(Integer::max);
System.out.println(max.get());
2
3
4
5
6
7
8
9
10
11
12
问题8:
Optional<Transaction> min2 = transactions.stream()
.reduce((t1, t2) -> t1.getValue() < t2.getValue() ? t1 : t2);
Optional<Transaction> min3 = transactions.stream()
.min(comparing(Transaction::getValue));
System.out.println(min +" "+ min2 +" " +min3);
2
3
4
5
6
7
8
# 参考文献
Java 8实战:https://book.douban.com/subject/25912747/ (opens new window)
