 摩擦感:AI时代的写作自省
摩擦感:AI时代的写作自省
# AI时代下的焦虑
写于2026年某个深夜。近期无论是个人输出还是配合友人写作,笔者逐渐感知到个人心态的转变。随着AI的高速发展,笔者的写作也变得愈发浮躁。正如知乎《为什么我会感觉vibe coding让程序员越来越浮躁了?》一文中的类比——我们失去了那种主动思考的摩擦感。所谓「摩擦感」,即主动思考与输出过程中的认知阻力——正是这种阻力,促使大脑深度加工信息,从而真正掌握知识。这与学习科学中「合意困难(Desirable Difficulties)」的概念不谋而合:适当的学习阻力不是障碍,而是深度学习的必要条件。

SharkChili · 计算机路上的禅修者
开源贡献
- mini-redis:教学级 Redis 精简实现 · https://github.com/shark-ctrl/mini-redis
- Nightingale:深度源码研究
关注公众号,回复 【加群】 加入技术社群
# 为什么要持续输出
结合上述知乎回答的观点,传统写作的流程也与此类似:
- 明确学习目标或主题
- 搜集素材并整理实践
- 汇总生成文章纲要
- 逐步填充知识内容
- 核对校正
- 阅读润色
- 发表分享,结合读者反馈再次迭代复盘
但现在的问题是,随着AI的发展,许多人在内容填充和纲要生成阶段就变得非常浮躁,内心存在一种 差不多写写,后续让AI帮我优化就行了 的想法。随着时间推移,这种心态逐渐演变为:不用写,给个想法让AI完成就好了。这种做法虽在效率上有所提升,却让笔者逐渐丧失了创造性的规划与书写能力。所以本着自我反思的目的,笔者想借这篇文章重新谈谈对写作的看法。
传统写作模式下,写作者都存在主动思考和主动输出,这使得以学习或工作复盘为目的的写作具备以下价值:
- 通过对既有知识进行细致的输出,发现不足之处,进而深入研究对应知识点,透彻理解知识
- 重塑大脑,即学习观中的有效训练——通过主动思考(实际执行)和校验校正(反馈答案)完成神经结构的更新,巩固既有知识
- 通过主动调动手、眼、脑多个器官完成知识复盘梳理,加深印象辅助记忆
- 写作物理持久化,周期性的复盘迭代回顾,可以认识到自己的不足,逐步成长
- 心理学中存在一种名为CBT(认知行为疗法)的心理干预方法,其中一项核心技术是认知重构,要求通过写作将内心想法表述出来,审视并校验自身思维模式的合理性
总的来说,写作是一个将思考结果输出的过程,即构建元认知的步骤。通过主动思考、倒逼输出的方式,能够有效获得所谓的摩擦感,从而提升个人认知能力。
明确了写作的价值后,下面笔者结合自身经验,详细拆解传统写作的具体执行步骤。
# 详解传统写作的执行步骤
# 明确目标
以笔者个人为例,写作的目的主要是对个人学习内容或灵感的复盘,即通过《断墨寻径》所说的转换表述和新例预测(用自己的话表达和举例说明)进行技术写作。通过这种主动输出的思考方式,不仅可以检验所构建知识的准确性,还能让大脑获得正向反馈以促进知识泛化,从而完成学习闭环和巩固。
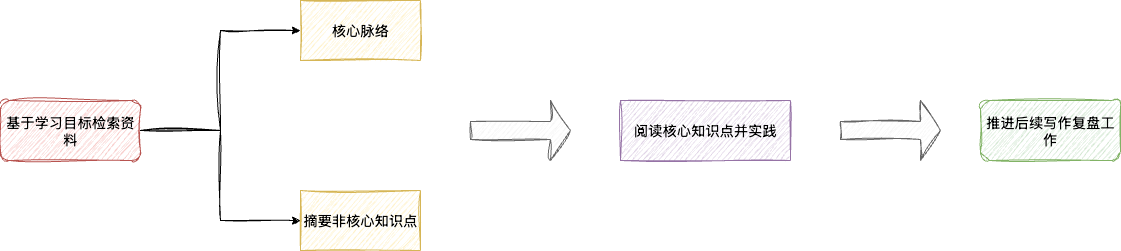
所以无论是针对个人灵感的复盘还是既有学习内容的梳理自检,写作的第一步都包含学习或提升个人认知维度的目标确认,即通过规划的方式确定学习和写作的方向。按照传统的技术博客写作方式,该阶段笔者会通过搜索引擎或书籍检索相关知识的内容,通过宏观阅读了解知识核心要点,而非所有细节。
计算机是一门无穷无尽的科学与哲学学科,每个知识点都可以无限延伸。所以,笔者在学习新技术或知识点时,都会通过通读的方式了解知识点的核心脉络,将一些细节上的使用简要概括,后续按需回顾。
以笔者23年写的这篇《写给Java开发的Go语言协程实践》为例:https://mp.weixin.qq.com/s/JBTxdiHz4wW_6zoGuEH5_A (opens new window)。作为Java程序员对舒适区之外技术的探索,确定目标时,笔者检索资料套路为:
- 检索非编程语言维度的协程相关概念
- 检索go语言协程基本教程文章
- 结合权威教程或开源项目了解go语言协程最佳实践
整体思路即通过基本概念扫盲->核心基础知识->进阶实践->原理剖析逐步递进获取资料,从而构建一个宏观且明确重点的知识框架:
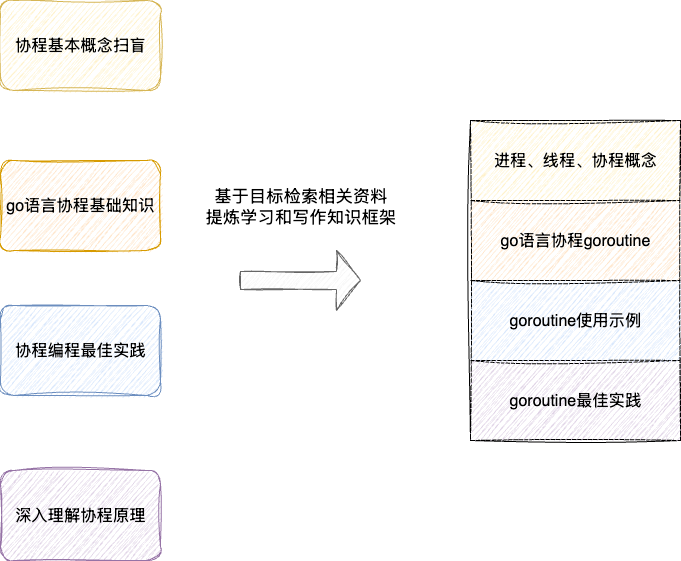
可以看到,通过对大量材料的收集、通读和归纳,整个学习和写作的执行路径就会非常明确且清晰:
# 素材学习实践
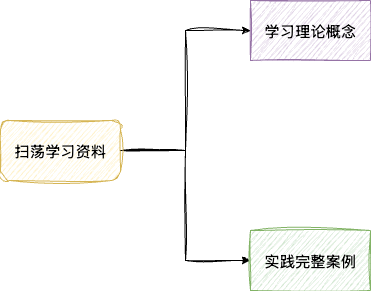
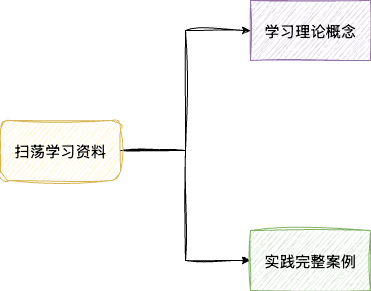
完成知识材料收集和学习目标制定之后,就可以着手学习了。以笔者为例,目标制定阶段已收集所有高质量的资料,这一阶段笔者会扫荡式学习与实践,即阅读资料中每个核心概念,对于不理解的知识点会通过扩充资料来理解掌握,确保知识泛化。
在理论学习的基础上,对于涉及代码实践的部分,则需要更进一步地动手验证。若是代码量比较庞大的案例,笔者会将其拆分为若干个小步骤,逐步实践并逐一核对,以主动思考独立实现的方式完整地实践下来。这样做的好处是——在眼、脑协同工作之上,增加手这个实践步骤,刺激更多的相关神经细胞群,让大脑做好更新的准备,注意笔者所强调的——做好更新的准备。
完成一次完整的实践之后,再结合教程中的案例进行比对核验,将实践结果反馈给大脑,让大脑明白当前的问题是什么,确保其能够正确完成自动归纳,完成神经细胞间的结构更新,从而完成一次有效训练的闭环。
我们还是以Go语言协程为例,阅读了解协程的工作机制时,对于 goroutine 模型的 M:N 设计感到困惑,为充分理解,笔者检索操作系统级别的权威资料,从系统底层了解其工作机制。这正是学习观中解决欠拟合问题的实践——通过扩充资料,建立新旧知识之间的联系,让所拟合的规律能够满足更多旧情况。
在此基础之上,完成协程模型的经典案例实践,构建一个理论与实践的闭环:
# 纲要先行
通过整体的学习和实践,对于既有学习知识就具备相对全面的认知,为了更好地归纳总结和复盘梳理,以及后续写作的条理性和连贯性,笔者在写作时首先会拟定标题,通过声明标题的方式,完成脑图式总结和梳理。
以笔者 Go 协程文章为例,整体的纲要与学习路径类似:
- 开篇介绍痛点、本文内容、收获
- 基础理论概念扫盲
- Go语言协程理论知识
- 实践落地
- 进阶知识点升华
- 总结梳理

# 写作风格与表述收益
写作风格因人而异,以笔者为例,整体表述追求严谨、清晰、规范,避免过于哗众取宠,行文上强调流畅和读者的舒适度。不会像常规公众号软文一样,通过花哨的表情包和过于庸俗的比喻影响知识的连贯性和权威性。以「分布式锁」这一概念为例,不同的写作风格会带来截然不同的阅读体验:
花哨庸俗(堆砌网络用语和表情,损害专业性和知识连贯性):
今天咱们来聊聊分布式锁这个骚东西,保证你看完直呼内行!🔥🔥🔥
过于学术晦涩(堆砌术语,读者需要反复咀嚼才能理解):
分布式锁是一种在分布式系统环境下,通过共享存储介质实现跨进程互斥访问的同步原语,其实现依赖于共识协议与租约机制。
严谨且易读(准确、清晰、有场景铺垫):
在分布式系统中,多个服务实例可能同时访问共享资源,此时需要一种协调机制来保证数据一致性,分布式锁就是解决这一问题的常见方案。
所以在写作风格上,笔者的建议是追求严谨且易读——既不花哨庸俗,也不过于学术晦涩。
无论选择何种风格,写作的表述都应遵循一个底层原则——让目标读者群能够准确理解你想要传达的技术或理论。这一点与费曼学习法的核心理念不谋而合:假设你在向任何一位技术同仁分享某个技术概念,用简单的词、短句和日常场景来类比。
表述技巧:当你试图简化表述时,会逼迫自己摈弃复杂的术语,主动思考并寻找更贴合读者认知的表述方式。
表述收益:这个过程不仅能让读者准确理解,更能倒逼作者发现自身理解上隐藏的空白。正如费曼所说:只有当你能用简单的话把一个概念解释清楚时,你才是真正理解了它。
基于上述风格与理念完成写作后,最后一步是跳出作者视角,以读者的视角审视文章内容。主动思考并输出,发现自己理解上隐藏的空白,并检验表述是否清晰准确、易于理解,由此找到适合自己也适合读者的写作风格。
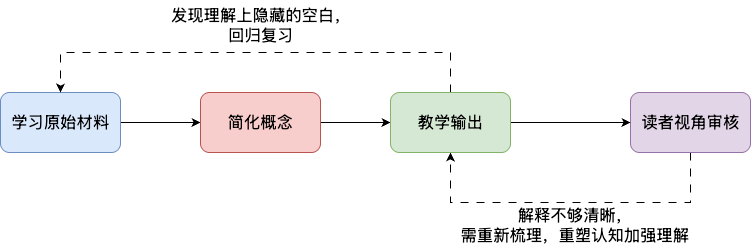
# 写作工具
# 资料检索渠道推荐
学习观指出,当我们对同一材料学习到一定程度时,就会遇到材料瓶颈——重复的材料无法继续提升泛化能力。因此需要从不同渠道获取新的学习材料,多角度理解同一知识点。
对于资料的检索,除了通过豆瓣检索高分书籍以外,对于互联网资料,笔者推荐以下几个渠道:
1. BestBlogs:一个非盈利的 AI 驱动技术内容聚合平台,帮助开发者获取最相关技术内容,避免信息过载:
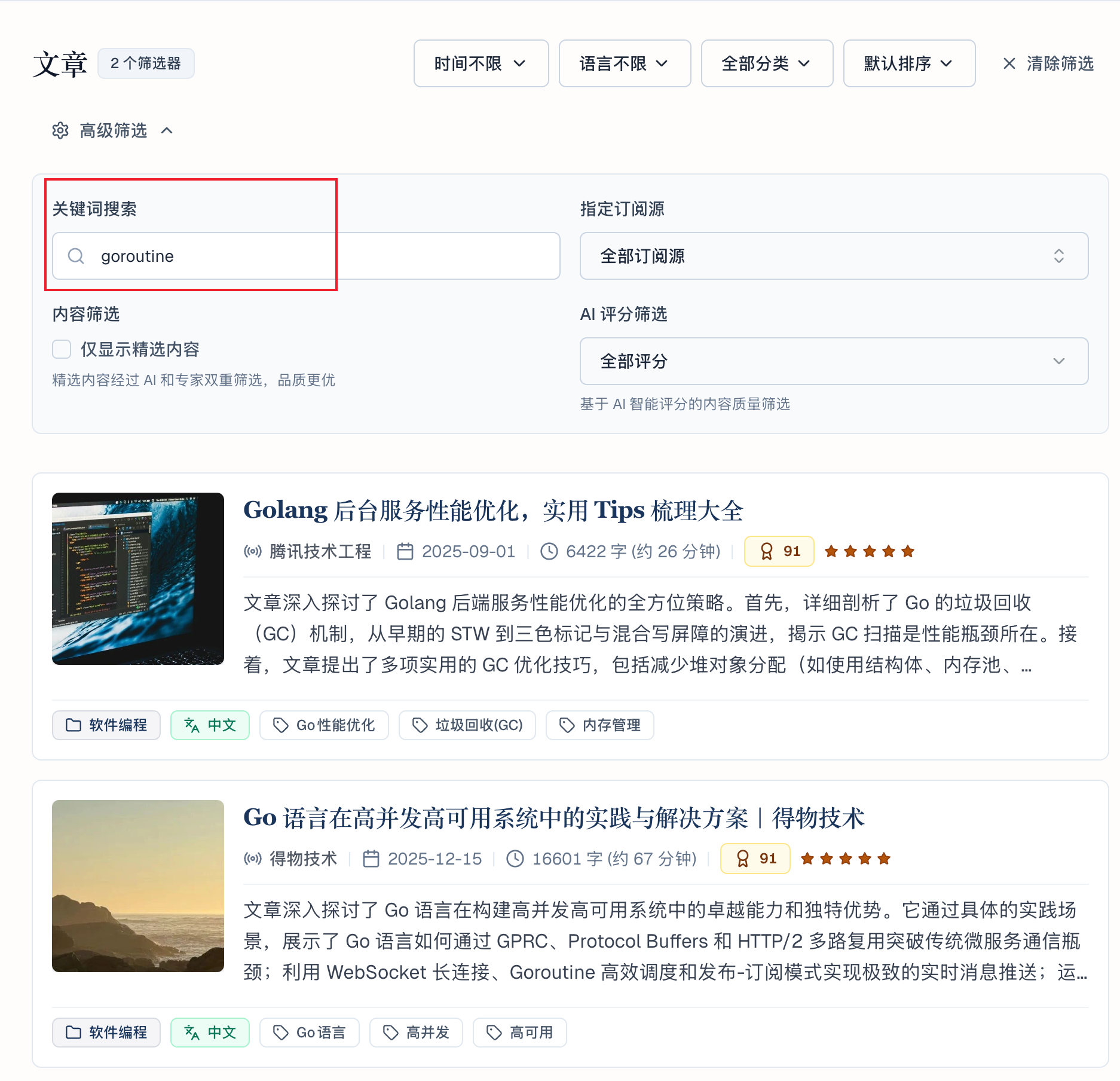
2. 公众号搜索:微信搜索能触达大量公众号独家技术内容,且通过阅读量、点赞等社交数据天然筛选出高质量文章。
3. 谷歌 AI 模式:通过英文检索让 Google 推荐相关参考文献

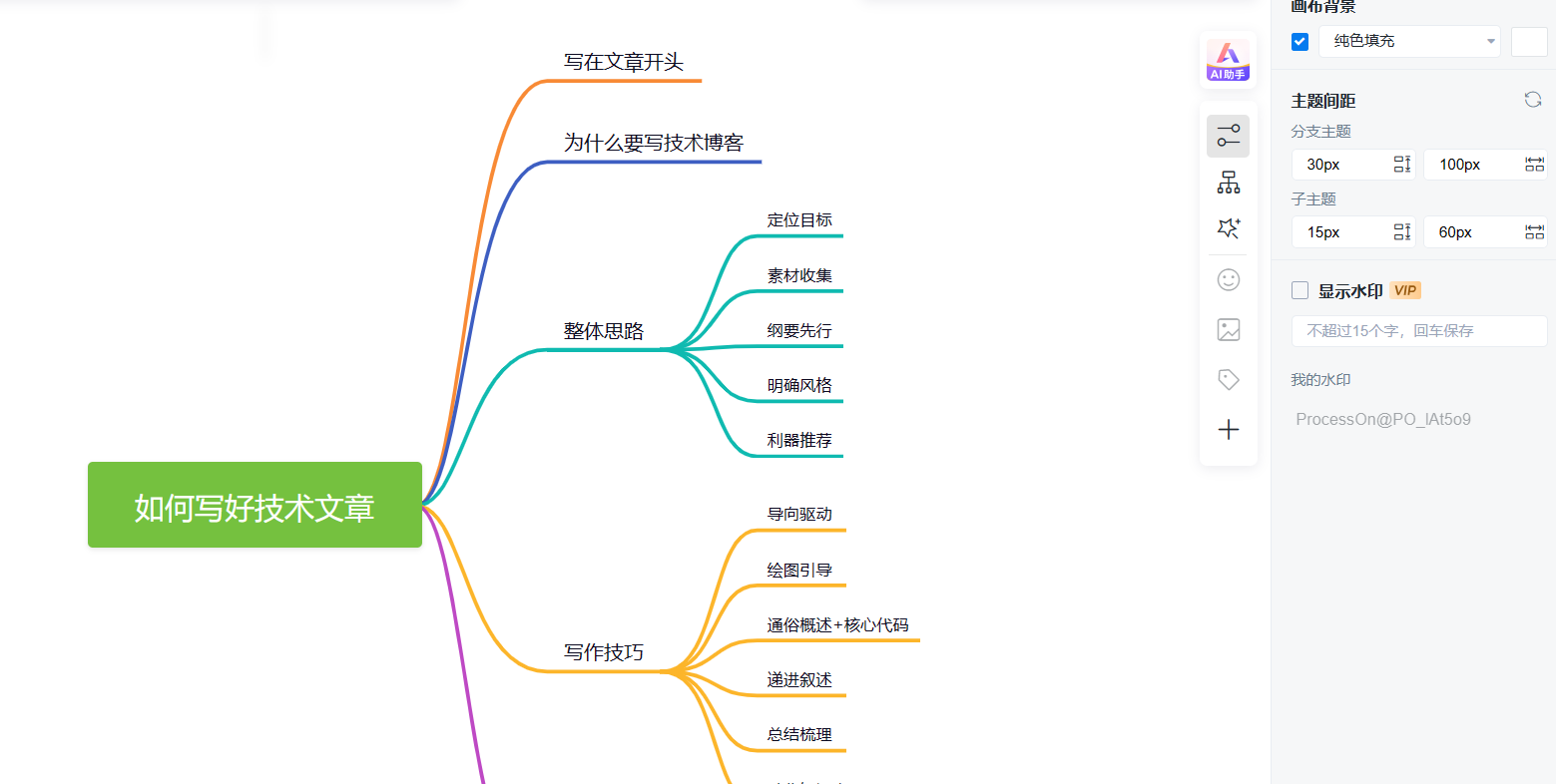
# 脑图工具:ProcessOn
写文时需要构建清晰文章脉络,辅助作者和读者把握文章结构,参考网上一些不错的文章分享,推荐使用 ProcessOn 进行大纲规划和脑图构建:
# 绘图工具:Draw.io
经常会有人强调"一图胜千言",所以写文时,笔者会大量绘制图片来表述观点。对于绘图工具,鉴于 Java Guide 的推荐,Draw.io 这款工具无论是图形风格还是颜色都比较舒服,符合笔者的审美。长期使用后,笔者更偏向使用它作为日常工作和写作的绘图工具。
关于图片的表达和绘制,更多是作者主观的抽象,这里笔者仅对配色和装饰做一些建议:
尽可能使用红黄蓝三基色,相较于大红大紫的颜色,红黄蓝更舒适。以笔者为例,使用 Draw.io 进行配色时,更多使用的是下面这几种配色风格。
背景色尽可能淡一些,使用淡黄背景更加清爽舒适。
- 图形可选用草图或 Comic 进行装饰。如果读者希望图形更特别,可在添加图形后选择草图:
当然,若希望配图有草稿纸风格,也可通过勾选 Comic 实现这种效果:
# 写作表达技巧
# 开篇引入方式
基于认知心理学,设问方式引导具有以下作用:
- 制造认知冲突,通过设问制造问题缺口,激发读者求知欲
- 明确学习目标,提升工作注意力和分配效率
- 给出具体场景,给予读者沉浸式阅读体验,增强记忆效果
- 主动引发读者思考,促使其完成知识提取,提升学习效率
以AQS源码讲解为例,如果我们开篇直接这样写:
谈到并发,我们不得不说AQS(AbstractQueuedSynchronizer),所谓的AQS即是抽象的队列式的同步器,内部定义了很多锁相关的方法,我们熟知的ReentrantLock、ReentrantReadWriteLock、CountDownLatch、Semaphore等都是基于AQS来实现的。
讲完之后直接贴出一张十分突兀的类图,试问读者还有深入了解这个知识点的热情吗?
反观闪客这篇文章的做法,它并没有以上帝的视角说所谓的"大话",而是直接用轻松诙谐的对话引入 AQS 的概念和基本作用,渐进式披露知识点:
10 点整,我到了公司,又成为全组最后一个到的员工。 正准备刷刷手机摸摸鱼,看见老板神秘兮兮地走了过来。 老板:闪客,你写个工具,基于 AQS 实现一个锁,给咱们组其他开发用 我:哦,好的 老板:你多久能搞好? 我:就是一个工具类是吧,嗯今天下午就给你吧 老板:嗯,那你抓紧时间搞吧,大家都等着用呢 我:哦,好的
所以笔者认为,在写硬核的技术文章时,应注意:
- 避免没有导向性的开篇
- 避免在开篇堆砌大量突兀的概念
- 采用渐进式披露的方式,在读者的记忆容量内逐步完成知识点覆盖学习
# 图文结合表述
对于知识点的讲解,我们还是强调要"讲清楚"而不是"堆名词",基于认知心理学的双重编码理论:文字信息由语言系统编码和存储,图片信息由视觉系统编码和存储,通过图文结合表述可以带来如下好处:
对读者:
- 通过视觉系统减少工作记忆上语言处理的负担,引导视觉注意力,促进语言系统上的语义理解
- 图片信息更紧凑密集,可以更快理解当前学习观点,并通过语言完成补充
- 两个系统互相激活,促进知识点关联网的形成,提升记忆效果
对作者:
- 这也印证了费曼学习法中"创造性重复"的观点——大脑喜欢多样性,把同一个概念用不同角度和形式讲述,会建立更多连接。当你试图用图画来解释一个技术概念时,会逼迫自己从文字表达的逻辑线中跳出来,为知识的桥梁建立更多支柱,巩固对知识的准确理解
我们还是以 AQS 为例,很多作者在进行源码讲解时,会直接列出源码中所有方法的说明,这种写法笔者之前也做过:
AQS 中提供了很多关于锁的实现方法, getState():获取锁的标志 state 值。 setState():设置锁的标志 state 值。 tryAcquire(int):独占方式获取锁。尝试获取资源,成功则返回 true,失败则返回 false。 tryRelease(int):独占方式释放锁。尝试释放资源,成功则返回 true,失败则返回 false。
写完后笔者以读者的方式代入这篇文章阅读时发现,它会有这样的问题:
- 锁是什么?在源码哪个位置?是什么锁?
state是什么?做什么用的?tryAcquire中的资源又是什么?什么样的东西可以定位为资源?- 最重要的一点,这几个方法有什么用?作者列出来的目的是什么?
- 了解这些知识点后对我有什么帮助?
相比之下,下面的做法更为可取,闪客在介绍 AQS 时的做法是:
- 将知识点自行消化
- 总结出核心的部分
- 用连贯的表述串联这些变量的关系
- 再用图解的方式辅助学习梳理
当这些前置铺垫都讲解清楚之后,他才将相关方法和变量进行细化展开,确保读者明确目的且阅读时不会感到突兀。

# 核心代码精简
在源码讲解的文章中,代码解读至关重要,笔者读过很多书籍博客,最常见的负面反馈就是:"这篇文章只是贴代码"。
所以笔者认为,对于源码讲解的文章,讲解细致工作流程之后,贴出最核心的代码是最佳的做法,这样写出来的文章既简洁又清晰。从认知负荷理论的角度来看:
- 提取核心代码段,减少非必要的信息干扰
- 提升信息密度,突出关键技术点,避免概念分散
- 方便知识点抽取和提炼,基于有限记忆容量完成知识的高效讲解
就以 AQS 源码为例,讲解细致工作流程之后,就无需用长篇源码带动读者去走读,取而代之的是引出核心部分的代码让读者自行学习,这样既保证了文章篇幅的简洁,又不会陷入文字级别的 debug 导致源码解读流程不流畅:
public abstract class AbstractQueuedSynchronizer {
private transient volatile Node head;
private transient volatile Node tail;
private volatile int state;
static final class Node {}
}
static final class Node {
// ... 省略一些暂不关注的
volatile Node prev;
volatile Node next;
volatile Thread thread;
}
2
3
4
5
6
7
8
9
10
11
12
13
同样的如果能够通过文字连贯地讲线程池七大参数讲解完成,那么我们索性贴出这些参数的核心部分也是可以的:
public FlashExecutor(
int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
{
... // 省略一些参数校验
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 知识点递进衔接
根据认知心理学研究,人类工作记忆容量有限(约 3~5 个信息组块,Cowan, 2001),因此,学习和写作都应采用递进式方法,以做到:
- 分块处理:将复杂技术概念分解为符合记忆容量的信息单元
- 渐进式披露:递进式加载知识,避免认知过载
- 上下文关联:利用工作记忆的上下文关联
如果在表述过程中突然出现很突兀的概念,对读者来说是非常灾难的,以这篇 AQS 源码讲解为例:
关于 state 的 get、set 方法就不贴了,重要的是有个通过 CAS 修改 state 的方法。 相关代码 除此之外,还维护了等待队列(也叫 CLH 队列、同步队列)的头节点和尾节点。 相关代码 CLH 队列由链表实现,以自旋的方式获取资源,是可阻塞的先进先出双向队列。通过自旋和 CAS 操作保证节点插入和移除的原子性。当有线程获取锁失败,就被添加到队列末尾。下面我们来看看每个节点是怎么实现的。
整个段落阅读完后,最直观的感受就是:
- 整个知识点变得很突兀
- 技术性概念没有很好的串联
- AQS 核心流程还是没有很直观的了解
反观这篇关于线程池核心参数的做法,在前文中用有限的文字将 worker 和任务队列都讲述清楚之后,以递进式披露的方式提出任务过多而无脑丢弃这个不合理的设计,从而引出拒绝策略的概念:
## 阐明线程异步机制,提出性能瓶颈,递进式披露引出核心线程数概念
小宇:哦,的确,只有一个线程在某些场景下是很吃力的,那我把 Worker 线程的数量增加?
闪客:没错,Worker 线程的数量要增加,但是具体数量要让使用者决定,调用时传入,就叫核心线程数 corePoolSize 吧。
## 增加线程数后,递进披露线程空转等一系列并发设计需要思考的问题
小宇:好的,那我这样设计
引出 worker 和队列的关系
闪客:好,你边吃我边说。现在我们已经实现了一个至少不那么丑陋的线程池了,但还有几处小瑕疵,比如初始化的时候,就创建了一堆 Worker 线程在那空跑着,假如此时并没有异步任务提交过来执行,这就有点浪费了。
小宇:哦好像是诶!
闪客:还有,你这队列一满,就直接把新任务丢弃了,这样有些粗暴,能不能让调用者自己决定该怎么处理呢?
小宇:哎呀,想不到我这么温柔的妹纸居然写出了这么粗暴的代码。
闪客:加拒绝策略 xxxxx
2
3
4
5
6
7
8
9
10
11
所以我们写文时切记一定要保持递进,前者一定要能带出后文的概念,确保读者阅读文章时连贯的感觉。
# 总结梳理
最后就是总结梳理。碍于篇幅,读者阅读后常有局部懂了而整体模糊的感觉,所以笔者建议在讲述完所有知识点之后,对文章中每一段知识点的内容进行简要总结,辅助读者梳理知识和回顾,构建完整体系的知识框架。按照现代科学研究,总结梳理技巧符合记忆巩固的认知规律:
- 回顾目标:回顾写作之初设定的学习目标,检验知识覆盖的完整性
- 知识整合:将分散的知识点整合为完整的认知图式,形成由点到面的认识
- 提取练习:通过主动回忆和提炼完成知识的二次加工,巩固记忆
- 迭代优化:结合读者反馈再次复盘迭代,逐步提升文章质量
所以,对于知识点的讲解,碍于篇幅,读者阅读后常有局部懂了而整体模糊的感觉,所以我们建议在讲述完所有知识点之后,通过一个段落帮助读者进行复盘梳理,帮助读者串联知识点,例如线程池源码讲解后的图片总结:
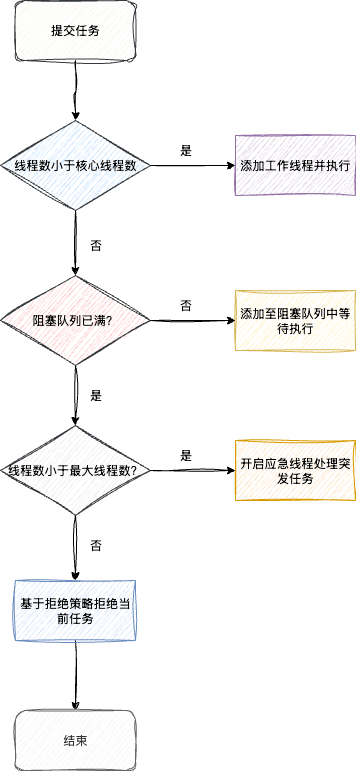
又比如这篇文章对于 LongAdder 源码讲解完成之后的总结:
至此,设计思路和实现过程,就都搞定了,我们来看一下整个流程:xxxxx
适时的总结,能够让读者对知识点形成由点到面的认识,所以笔者建议在文章中进行总结,从而保证文章的学习质量。
# 升华文章
升华文章是笔者构建进阶知识图谱的常用手段,通过将不同领域的知识建立深度链接,让作者和读者都能获得这些收益:
- 概念性挖掘:在既有知识图谱中发现概念间的隐含关系
- 跨领域链接:构建不同技术领域之间的关联,建立一个更庞大的知识体系
- 抽象层次递进:从具体实现上升到设计思想的抽象提升
如果作者对于技术有着不错的理解,完全可以理清所有概念之后,通过深入核心知识点去剖析底层原理,讲述经典的生产问题、难度较大的面试题或进阶知识点。依然是渐进式递进到进阶知识点,通过类比思维降低理解难度,给出通用的解决模式。
就例如闪客这篇文章,在讲解完 LongAdder 基础概念、实践与源码级核心流程之后,为了加深读者对于 LongAdder 的理解,引出伪共享问题的概念。通过伪共享这一操作系统级别的理论知识,让读者在 LongAdder 日常运用中,具备一个更加底层的视角,确保技术选型和方案落地的精准性:

# 借助AI润色文章
内容润色是笔者最新补充的一个概念,也是比较重要的一环,笔者必须强调,写作是主动思考和复盘梳理的过程,只有写作者主动思考的实践才能确保这一过程的有效性,即学习观中的有效训练概念。
润色仅仅是现代写作中一个锦上添花的操作,该步骤是利用大语言模型(LLM)的知识储备,对文章中可能遗漏的错误或不当的表述进行纠正。必须清楚地认识到,AI润色只能提供描述性材料,而真正让大脑完成神经结构更新的是实际执行这一步——主动思考内化并输出AI反馈的结果,让相关神经细胞群受到刺激,做好更新的准备。
随后通过校验、比对、纠正完成反馈答案,让大脑知道该如何更新。只有经历这两个过程,才算一次有效训练。跳过主动思考直接让AI生成,等同于只接收指令性材料而不经历实际执行,大脑无法完成有效的结构更新。
所以笔者的建议是:先自己主动完成写作和核对,再让AI辅助建议并主动。前者完成有效训练的闭环,后者提供额外的反馈信号,进一步优化知识结构。
以笔者为例,针对既有学习和复盘的写作,收尾阶段一般会通过以下提词进行辅助调整:
作为一名计算机编程技术博客写作助手,请对指定文本执行以下专业编辑任务:
1. 语法与拼写修正:全面检查并修正文本中的语法错误、拼写错误及标点符号使用不当问题
2. 技术准确性提升:核实并纠正所有知识点的表述错误,确保技术概念、术语使用及代码示例的准确性
3. 内容优化:
- 提升文章整体清晰度与专业表达
- 增强文本简洁度,删除冗余表述
- 分解冗长复杂句子,优化句式结构
- 消除内容重复,确保信息传达高效
4. 可读性改进:调整段落结构,优化逻辑 flow,提升文章整体可读性
2
3
4
5
6
7
8
9
# 大胆分享,拥抱错误
费曼学习法中有一个关键观点:错误不是障碍,而是地图。当你讲不顺利的地方,正是将其转为清晰表达的原材料。这个理念同样适用于写作。
很多技术写作者有一个共同的心理障碍:怕写错,所以不敢写。担心被读者指出错误,担心表述不够严谨,担心观点经不起推敲——于是反复打磨迟迟不敢发表,甚至直接放弃。但实际上,正如学习观所指出的,当我们对同一材料学习到一定程度时,就会遇到模型瓶颈——仅凭自己的思考已经无法继续提升认知,此时需要外部反馈来打破这个瓶颈,而读者的意见恰恰是最直接的外部反馈。
写作中的错误并不可怕,可怕的是:
- 害怕犯错而不写:你永远无法发现自己理解上的空白
- 回避读者反馈:你永远无法突破模型瓶颈
- 把批评当成否定:批评恰恰是帮你打通知识桥梁的外力
大胆把你的思考分享给读者,哪怕不够完美。当读者指出你的错误时,这不是否定,而是一次免费的"费曼复习"——它帮你精确定位了知识的缺口,甚至暴露出你从未意识到的问题,让你知道该在哪里补强。每一次纠正,都是对知识模型的迭代升级。
真正的学习,不是等到完美才输出,而是在输出中走向完美。
# 我对AI写作的一些看法
AI时代快速发展,其发展速度远超过人类的思考速度,使得我们在单位时间窗口内的理解成本急剧增加,导致人类愈发浮躁,进而出现某些元能力的退步。笔者不知道这是否算一种进步,但现阶段,笔者还是试着将这些原本自己具备的元能力捡回来,保持写作时那种所谓的大脑思考与输出之间的摩擦感,使其成为笔者日常学习和工作的有效整理手段。
希望我的理解对你有所帮助。
SharkChili · 计算机路上的禅修者
开源贡献
- mini-redis:教学级 Redis 精简实现 · https://github.com/shark-ctrl/mini-redis
- Nightingale:深度源码研究
关注公众号,回复 【加群】 加入技术社群
# 参考
老板让只懂Java基本语法的我,基于AQS实现一个锁:https://mp.weixin.qq.com/s/1Nq_izUkOGmtvkIQ9c0QRQ (opens new window)
破玩意 | 多线程 +1 的最快操作:https://mp.weixin.qq.com/s/Hbz1k5bDhdfPSb05PAZNrw (opens new window)
你管这破玩意叫操作系统源码 | 第二回 自己给自己挪个地儿 :https://mp.weixin.qq.com/s?__biz=Mzk0MjE3NDE0Ng==&mid=2247499274&idx=1&sn=23885b5b1344a1425f5a971d06ad2e7d&chksm=c2c584a7f5b20db1b0a75ea896e7218a9f8bcd006e68f53693bab240b13f9e2fb0ec0c9b9a6a&cur_album_id=2123743679373688834&scene=189#wechat_redirect (opens new window)
写公众号文章,我其实用了这些工具! :https://mp.weixin.qq.com/s/gyM5E5RZKGNko0dhL-hLVw (opens new window)
为什么我会感觉vibe coding让程序员越来越浮躁了?:https://www.zhihu.com/question/1951716962645288920/answer/2015813714209701999 (opens new window)
断墨寻径摘录:https://blog.csdn.net/qq_54088234/article/details/135237324 (opens new window)
【断墨寻径】学习笔记 :https://zhuanlan.zhihu.com/p/443948940 (opens new window)
鹅厂写码13年,我总结的程序员高效阅读方法论:https://cloud.tencent.cn/developer/article/2453570?policyId=1&traceId= (opens new window)
- 01
- Go语言常见面试题解析(上)语言基础与核心概念05-20
- 03
- AI 写的企业级组件不敢用?我替你验过了05-19
