 从断墨寻径浅谈程序员的元学习能力
从断墨寻径浅谈程序员的元学习能力
# 写在文章开头
作为开发者,不知你是否观察过这样一种现象:面对一门新技术,有的人能够快速完成检索、学习和总结,并将其应用到实际项目中;而有的人工作多年,仍然依赖教程手把手地教学,不具备元学习能力,始终无法做到与时俱进。
所谓元学习能力,即「学会如何学习」的能力。软件开发是一个需要持续学习的行业,技术栈的更新速度远快于大多数职业,一个开发者能否在职业生涯中不断成长,很大程度上取决于其元学习能力的强弱。而造成上述差距的核心原因,正是前者掌握了一套科学的学习方法,后者则始终停留在低效的学习习惯中。
《断墨寻径》是笔者23年左右进行自我迭代复盘时发现的一门宝藏课程,它从认知科学和神经科学的角度,系统地回答了「如何有效学习」这一核心问题。本文结合该课程的核心观点,从软件从业者日常学习场景出发,梳理出一套完整的学习观,内容涵盖以下几个方面:
- 知识与记忆的区别
- 两种学习方式——指令学习与归纳学习
- 学习效果的偏差——欠拟合与过拟合
- 学习材料的有效性——有效实例与有效描述
- 知识的适用范围——限定条件也是知识的一部分
- 学习的瓶颈与突破——材料瓶颈与模型瓶颈
- 大脑的记忆机制与有效训练
- 精细加工——建立新旧知识的关联
- 知识的验证——新例预测与表述转换
本文不会介绍任何具体的计算机知识,而是提供一套学习的方法和技巧。通过提升学习的底层能力,帮助读者在职业生涯中实现更高效的成长。
我是 SharkChili ,Java 开发者,Java Guide 开源项目维护者。欢迎关注我的公众号:写代码的SharkChili,也欢迎您了解我的开源项目 mini-redis:https://github.com/shark-ctrl/mini-redis (opens new window)。
为方便与读者交流,现已创建读者群。关注上方公众号获取我的联系方式,添加时备注加群即可加入。
# 知识与记忆的区别
# 什么是记忆
在学习方法之前,我们需要先区分两组核心概念:记忆与学习、信息与知识。
记忆的目标是重现信息,即将已经见过的内容重新复现出来。这类信息通常没有规律可循,只能通过反复强化来记住。典型的例子如:
- 面向对象三大特性:仅需记住"封装、继承、多态"这三个名字
- 事务中 ACID 四大原则:仅需记住"原子性、一致性、隔离性、持久性"及其英文缩写
- HTTP 状态码 200、404、500 含义:仅需记住数值与含义的对应关系
学习的目标则是泛化,即根据已知信息推断出从未见过的新情况该如何处理。与记忆不同,学习适用于情况无限、事先未知的场景,这也是学习方法需要解决的核心问题。
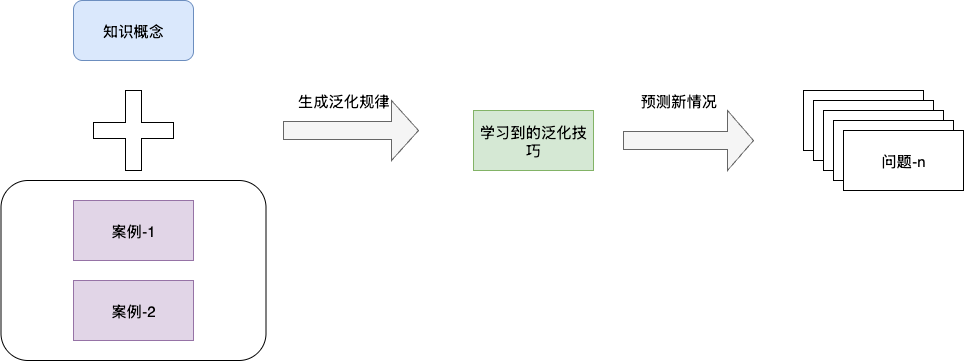
简单来说,记忆应对的是已知情况的重复出现,而学习解决的是未知情况的应对。
# 什么是知识
与记忆不同,知识的目标是生成新信息、解决新情况,即泛化。这类规律不是凭空产生的,而是通过大量实例,经过实践、归纳、总结得出的。
以算法时间复杂度的推导为例,掌握这类知识的标志是:给定任意一段代码,我们都能推导其时间复杂度。其推导规则如下:
- 定位代码中的循环或递归部分
- 计算循环或递归的最长执行次数
- 用 n 代替次数的最高阶,如
5n² + 3n → O(n²)
例如:
public void function(int n){
for (int i = 0; i < n; i++) {
// todo something
}
}
2
3
4
5
这段代码只有一层循环,循环次数为 n 次,因此时间复杂度为 O(n)。
而对于双层嵌套循环:
public void function(int m, int n){
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
// todo something
}
}
}
2
3
4
5
6
7
循环次数为 m*n,即 n²,因此时间复杂度为 O(n²)。
可以看出,知识的价值在于其可泛化性:掌握推导规则后,面对从未见过的代码,我们依然能正确推导其时间复杂度。这正是记忆与学习的本质区别。
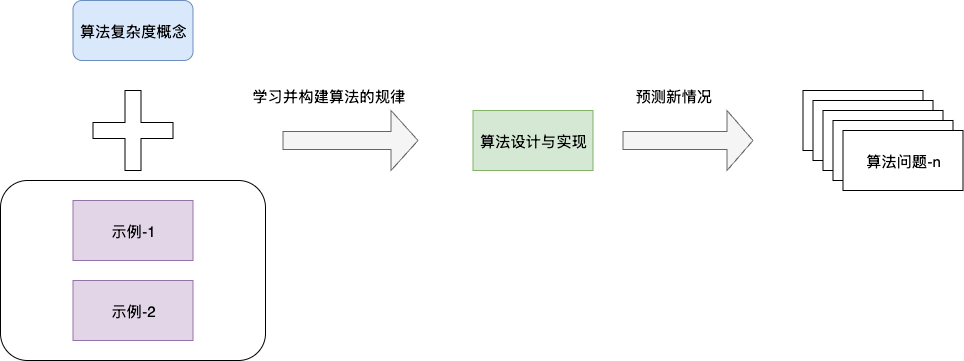
# 两种学习方式——指令学习与归纳学习
# 什么是指令学习
指令学习即通过语言描述,对概念、规律进行学习,从而建构知识。其特点是:
- 指令较为规范,不容易以偏概全,便于泛化
- 必须依赖人类语言,而人脑天生不擅长处理抽象语言
例如算法时间复杂度的推导,指令学习就是直接看教材中的定义:
数循环/递归的层数和变化规律,只取 n 的最高次项
对于已经熟练掌握的人来说,这个定义非常清晰;但对于初学者,仅靠这段抽象描述来完成推导却非常困难,因此需要结合归纳学习来配合完成知识构建。
# 什么是归纳学习
归纳学习通过观察多个实际案例,让大脑自动找到不同实例之间的共性,然后用共性来推测从未见过的情况该如何处理。其特点是:
- 归纳过程不由意识控制,而是大脑在特定条件下自动执行
- 不依赖语言,古人、动物都会,仅通过对实例的观察和操作即可完成
- 可以增加泛化能力
- 但容易以偏概全,无法泛化
归纳学习最经典的例子是学习遥控器的使用:初次使用时我们并没有阅读说明书(指令学习),而是通过操作按键观察电视的反馈,让大脑利用这些实例构建出使用规律。
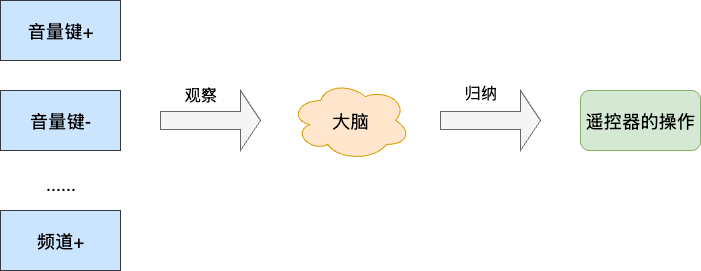
# 为什么归纳和指令需要结合
人类很容易在示例不足时产生错误的知识映射。例如:
给定数字 1、2,猜测第 3 个数字是多少?
按照当前的映射,可能得出公式 f(x) = x,但实际上这可能是个斐波那契数列,真实公式是 f(x) = f(x-1) + f(x-2)。因此,学习时需要以归纳学习为主泛化规律,指令学习为辅验证标准。
# 学习过程中的"理解"
理解即为感知模式,这里的模式指的就是不同实例中都会重复出现的共性和规律。
理解的过程,就是不断对比实例、感知共性的过程。例如:
- 线性子空间:查看定义 → 结合不同案例感知差异 → 得出特点和规律
- HashMap 与 List 的查询性能:阅读文档了解两者底层数据结构 → 对比在 List 中遍历查找元素与在 HashMap 中通过 key 查找元素的性能差异 → 感知到 HashMap 通过额外空间存储 key-index 映射实现了 O(1) 查询效率 → 理解以空间换时间这一取舍的本质
理解就是感知模式,感知到的共性和规律就是模式本身。
# 归纳与指令的结合——双例对比法
基于上述讨论,我们可以得出一个实用的学习方法——双例对比法,步骤如下:
- 确定学习目标:选择要学习的知识,例如算法的时间复杂度推算
- 查看指令:粗略了解知识的定义,如"数循环/递归的层数和变化规律,只取 n 的最高次项"
- 搜集实例:找到两个算法的代码段作为学习案例
- 独立思考:尝试自行推算,做每道题都需要经过完整思考,不能没思路就看答案
- 对比总结:感受两道题的共性和差异性,再回过头理解对应的指令
- 测试验证:做新题来测试自己的理解,重复步骤 2-5 直到泛化能力满意为止
提示:做过的旧题目可以和新的题目进行比较,能极大节约时间、提高效率。
# 学习效果的偏差——欠拟合与过拟合
# 欠拟合:归纳学习的不充分
欠拟合的本质是归纳学习不充分:基于现有案例得出的规律,却无法印证当前情况(泛化失败)。
其原因是看到的样本过少。解决方法很简单:增加新样本观察。
例如:看到一个简单的 for 循环遍历数组:
for (int i = 0; i < n; i++) {
// 一些操作
}
2
3
可能会认为这是 O(n)。但如果这个 for 循环内部调用了 Arrays.sort():
for (int i = 0; i < n; i++) {
Arrays.sort(someArray);
}
2
3
实际复杂度是 O(n log n)。如果只见过循环体中没有函数调用的示例,就无法理解这种模式,从而导致欠拟合。
# 过拟合:示例的以偏概全
过拟合的本质是归纳学习过度:基于现有案例得出的规律,可以满足旧情况,但无法满足新情况(不能泛化)。
其原因是样本有偏,缺少负面案例。
例如在学习插入排序的时间复杂度时,如果只看到它在无序数据下的表现,可能会得出"插入排序总是 O(n²)"的结论。但如果数据已经有序,插入排序的时间复杂度是 O(n),这个结论在新情况下无法满足。
// 数据有序时,每次只需比较一次
for (int i = 1; i < n; i++) {
int key = arr[i];
int j = i - 1;
while (j >= 0 && arr[j] > key) { // 实际只比较一次就退出
arr[j + 1] = arr[j];
j--;
}
arr[j + 1] = key;
}
2
3
4
5
6
7
8
9
10
如果只见过无序数据的示例,就无法理解插入排序在有序数据下的性能表现,从而导致过拟合。
对于过拟合问题,解决方法同样是增加新的样本,即增加负面案例。
# 学习材料的有效性——有效实例与有效描述
# 有效实例
归纳学习要求通过大量例子让大脑自动进行归纳,因此实例必须满足以下要求:
- 知识点要有对应的问题
- 题目详细的解决步骤
- 有标准的输出答案
缺少以上任何一个条件都无法完成完整的学习。这意味着在学习过程中必须确保:
- 搜寻的素材必须具有输入和输出
- 如果对示例中的概念有不清楚的地方,应及时查阅资料进行理解和掌握
# 有效描述
对于指令学习来说,仅有实例是不够的,还需要有效的描述。有效描述包括:
- 理解概念:明白术语的定义
- 理解指代:知道概念在具体场景中指向什么
例如在学习时间复杂度时,不仅要知道"时间复杂度是算法执行时间与输入规模的关系"这一定义,还要能够识别代码中的输入规模 n 和基本操作的执行次数。
# 学习的瓶颈与突破——材料瓶颈与模型瓶颈
学习瓶颈分为两种类型:
# 材料瓶颈:缺乏新材料
学完当前材料后仍无法掌握知识,例如看完算法书还是不懂分析时间复杂度。
这种情况需要增加新的材料来构建知识。单一的资料往往难以讲透某个概念,多本书籍配合学习效果更好。例如只读《算法导论》可能觉得时间复杂度难以理解,这本书更偏理论推导,会用数学公式和递归式来分析复杂度。
但补充一本《算法图解》后,书中会用图形化的方式展示一个 for 循环的执行过程——每循环一次输出一次结果,让你能直观看到循环次数与输入规模 n 的关系,从而理解为什么复杂度是 O(n)。
# 模型瓶颈:旧认知的抗拒
能解决大部分问题,但仍有一些情况无法处理或处理错误,例如会算 for 循环的时间复杂度,却算错二分查找。
这种情况是因为当前知识足以应对日常工作,但并非完全正确。当有人指出错误时,大脑会产生抗拒。应对方法是增加更多实例,打破大脑对现有知识的旧认知。
例如只见过 O(n) 的代码示例,容易形成"所有循环都是 O(n)"的认知:
// O(n) - 单层循环
for (int i = 0; i < n; i++) {
System.out.println(arr[i]);
}
2
3
4
但二分查找虽然是循环结构,实际复杂度却是 O(log n):
// O(log n) - 二分查找
int left = 0, right = n - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (arr[mid] == target) return mid;
else if (arr[mid] < target) left = mid + 1;
else right = mid - 1;
}
2
3
4
5
6
7
8
需要通过这类新实例来纠正认知偏差。
# 大脑的记忆机制与有效训练
# 什么是有效训练
学习的最终目标是让大脑建立新的神经结构。要实现这个目标,需要通过有效训练。有效训练包含两个过程:
- 实际执行:自己动手做一遍,得到自己的答案。研究表明,想象和观察也能刺激部分神经细胞,但最有效的方式是实际执行。例如学习Redis有序集合的底层数据结构跳表时,不要只盯着文章或Redis源代码看,而是自己在纸上画出跳表的结构、手动模拟插入和查询的步骤。看一百遍别人画的图,不如自己动手画一遍印象深刻。
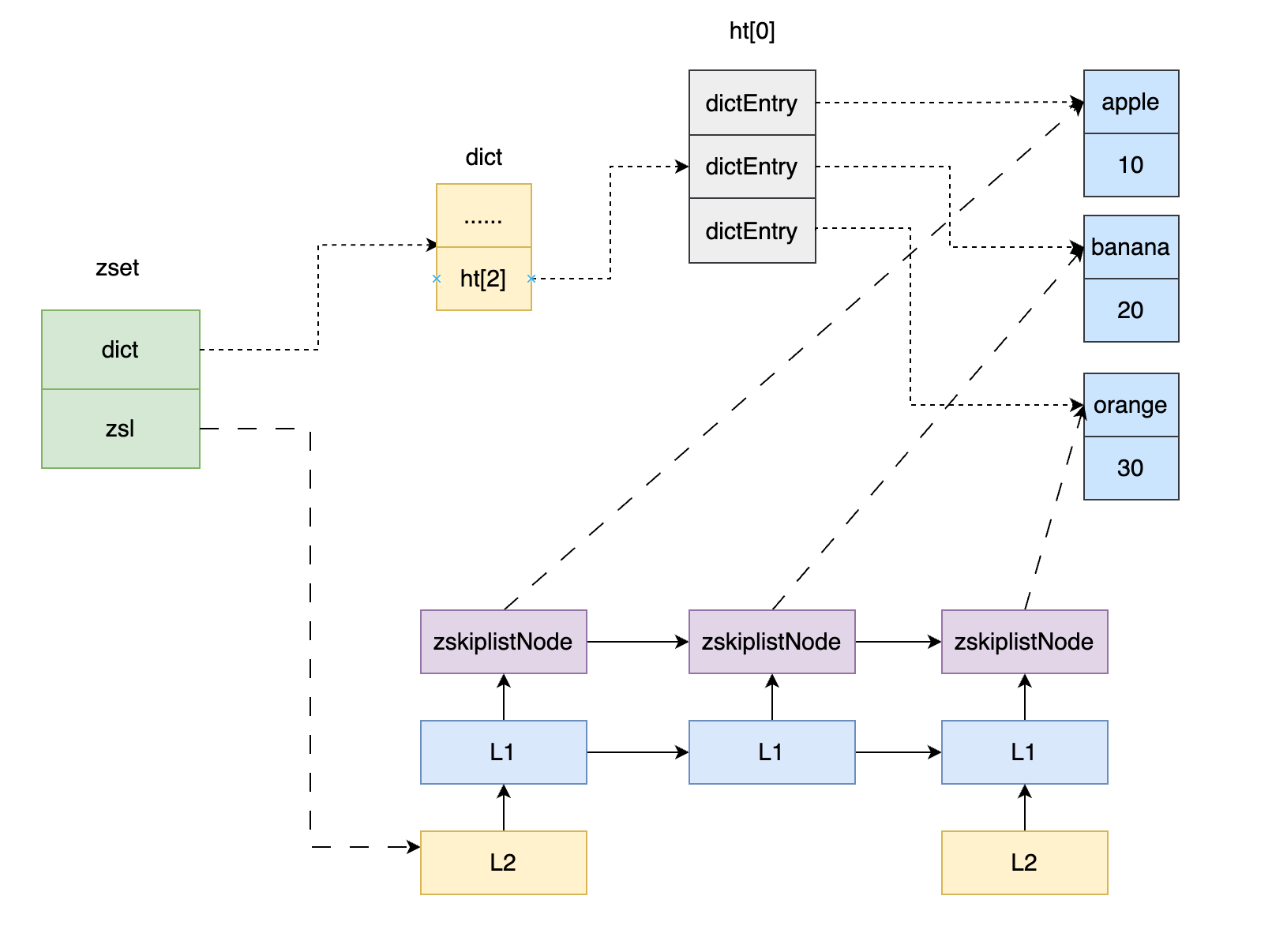
做每道题都要经过完整的思考,不能一没思路就看答案,要思考得出一个自己的答案为止,即使哪个答案是错误的也没关系。值得注意的是,小孩子往往比大人做得好——小孩子会完整模仿一遍,而大人因为已经建构了很多知识,一看就明白,很容易跳过这一步,以至于往往只是在应用已有的知识,而不是去建构新的知识。实际执行只是让相关神经细胞做好更新的准备。
- 反馈答案:执行后需要得到答案或评分。例如学习Redis跳表时,画完跳表结构后需要对照文章检查自己画的是否正确;模拟完插入操作后需要用Redis实际运行命令验证结果。又比如婴儿学说话时,父母的表情和反应就是天然的反馈——没有反馈就无法确认自己说得对不对。反馈答案的作用是让大脑知道如何更新神经结构,这是有效训练中不可或缺的环节。
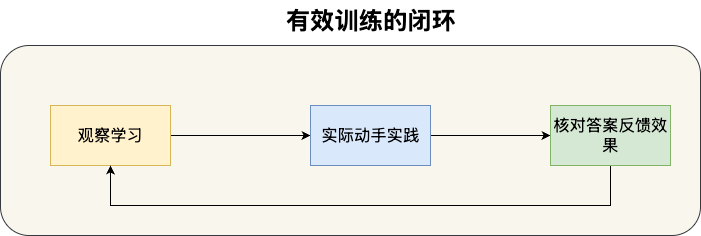
对于指令性材料,由于语义表述抽象,初学者难以理解。有效训练的方法是:转换表述,用自己的话解释定义,并结合实例去验证。大量的有效训练才是我们进步的关键。
# 建立新旧知识之间的关联——精细加工
用新的知识结合旧的知识互相印证,加深对知识的理解,这就是精细加工。研究表明,深度加工的信息更容易进入长期记忆。大脑中的知识不是孤立存储的,而是通过神经连接形成网络。当新旧知识建立联系后,提取时线索会激活一个节点,然后自动扩散到相关节点——连接越多,记忆越稳固。
例如:学习Java并发包中的ConcurrentSkipListMap时,联想到之前学过的Redis有序集合底层数据结构跳表——ConcurrentSkipListMap正是Java对跳表思想的实现,新旧知识互相印证能帮助更好地理解两者的共同原理。
# 充分睡眠,更好地构建知识
有些人为了节省时间而压缩睡眠,或者要求当天就完全学会知识,忘了就自责——这两种想法都不正确。
知识存储在神经细胞之间的突触结构中,学习就是让神经细胞形成合适的结构。神经细胞通过网络传递电信号来"交流",合适的结构才能生成正确的信号。
但我们无法直接改造神经结构,只能通过有效训练让大脑接收合适的材料,自己调整出合适的结构。而大脑大规模调整结构的时间,正是睡眠期间。
很多人都有过这种经历:当天怎么学都学不会的技能,睡一觉醒来突然就掌握了。这就是睡眠在知识构建中的重要作用。
因此,学习和睡眠需要平衡:光学习不睡眠,大脑没有时间调整结构;光睡觉不学习,大脑没有依据来调整。
而且大脑不能保证每次调整都正确,复杂的知识需要多次迭代,慢慢调整出更普遍的规律。以学习Redis跳表为例,第一天看完文章后只能大体了解跳表的工作机制,第二天结合代码才能深入理解细节,再过几天不看书直接手写复刻,才能真正把抽象概念内化为自己的知识。因此,合理的学习安排是同时学习多个领域,每天每个领域学两三个知识点,让大脑在睡眠期间有充足的调整时间。比如在学习Redis跳表的同时,可以穿插学习并发编程或系统设计,让不同领域的知识交替进行。
# 知识的验证——新例预测与表述转换
# 新例预测
有效训练之后,还需要验证学习是否正确,最好的办法是接触更多新情况,将知识运用到新场景中。
例如学习时间复杂度的推算方式后,去分析其他算法的时间复杂度;学习Redis跳表后,尝试分析ConcurrentSkipListMap的时间复杂度。只有将现有知识运用到新情况中,才能更好地巩固和加深理解。
研究表明,提取练习效应(Retrieving Practice Effect)是迄今最有效的学习方法之一。相比被动重复阅读,主动从大脑中提取信息会强化神经突触连接,建立多条记忆通路,使记忆更加牢固。这正是为什么在工作中实际运用了某个知识点后,对它的理解会格外深刻——因为你在不断"提取"和"应用"知识,而非被动地"看"。
# 表述转换(同义转换)
通过能否用自己的话来表述相同的意思,来排除自己并不是只记住了表述而未理解。倘若某人真的用指令性材料建构了知识,而不是单单机械记住了这个材料本身,那他一定也可以用另一种描述表达出与该指令性材料类似的意思。也就是老师常说的"学习要用自己的话来表述"。
例如Redis有序集合底层跳表的定义:
跳表是一种基于有序链表的多层索引数据结构,通过在每个节点中随机决定层级,以空间换时间的方式将查找时间复杂度从O(n)降低到O(log n)。
我们的说法是:跳表就是带有多级索引的链表,每一级通过forward指针和span跨度构成索引,查找时从最高层开始,通过score比较不断向前向下递进,逐步缩小检索范围,直到定位到目标元素。
# 以教促学
预测新例和转换表述的结合应用。教别人的时候,举个例子、换句话说,其实就是新例预测和转换表述。
教人之所以可以巩固自己学习,其关键就在于,教学过程既可以检验学习者所建构知识的正确性,又给大脑提供了一个反馈信号,让大脑知道所建构的知识已经可以泛化,不必遗忘,从而确保成果正确。
对于程序员而言,推荐采用代码实践+写博客技术复盘输出的方式:代码实践对应有效训练中的实际执行与反馈答案,让大脑完成神经结构的更新;写博客对应以教促学,用自己的话表述知识(转换表述)并举例说明(新例预测),既检验知识的正确性,又给大脑提供反馈信号以巩固知识。详见笔者另一篇文章:摩擦感:AI时代的写作自省 (opens new window)。
# 总结
让我们来总结这篇文章所要告诉我们的完整学习步骤:
- 明确目标:确定学习目标是记忆还是需要泛化的知识,选择对应的学习策略。
- 选择材料:确保学习材料的有效性——实例性材料需同时具备问题和答案,描述性材料需确保所有概念均可被理解。结合指令学习与归纳学习,通过双例对比法感知实例中的共性和规律。
- 有效训练:自己动手实际执行一遍,得出自己的答案,再对照标准答案进行反馈校正,让大脑完成神经结构的更新。结合精细加工,将新知识与旧知识建立关联以强化记忆。
- 突破瓶颈:遇到学习瓶颈时,区分是材料瓶颈(需补充新材料)还是模型瓶颈(需用实例打破旧认知),对症突破。
- 验证巩固:通过新例预测和表述转换验证知识的正确性,以教促学巩固学习成果。
- 充分睡眠:给大脑足够的时间完成知识的调整与归纳,复杂的知识需要多次迭代,合理安排多个领域交替学习。
当然,上述学习方法论是一套普适标准定义的方案,学习者可以针对自身情况对这套学习方法论进行扩充找到适用于自己的学习方式。
你好,我是 SharkChili ,Java Guide 核心维护者之一,对 Redis、Nightingale 等知名开源项目有深度源码研究经验。熟悉 Java、Go 等多语言技术栈,现任某知名黑厂高级研发。
🌟 开源项目贡献
- mini-redis:教学级 Redis 精简实现,助力分布式缓存原理学习
🔗 https://github.com/shark-ctrl/mini-redis (opens new window)(欢迎 Star & Contribute)
📚 公众号价值 分享企业级架构设计、性能优化、源码解析等核心技术干货,涵盖分布式系统、微服务治理、大数据处理等实战领域,并探索面向AI的vibe coding等现代开发范式。
👥 加入技术社群 关注公众号,回复 【加群】 获取联系方式,与众多技术爱好者交流分布式架构、微服务等前沿技术!
# 参考
断墨寻径:https://www.bilibili.com/video/BV1LU4y1g7no/?spm_id_from=333.788 (opens new window)
看书的一点小建议!:https://mp.weixin.qq.com/s/_y_kkhDil-2GCedilKurTA (opens new window)
《断墨寻径》学习方法总结: https://zhuanlan.zhihu.com/p/521996300 (opens new window)
学习系列02:学习时,大脑发生了什么?:https://zhuanlan.zhihu.com/p/134739395 (opens new window)
符号系统能降低认知负荷,强化信息分类能力(源于认知心理学中的"Chunking"机制)。
Mueller & Oppenheimer (2014) 《The Pen Is Mightier Than the Keyboard》 证实手写符号标记比纯文字更提升长期记忆。
Clark & Paivio (1991) 《Dual Coding Theory and Education》 证明图表重构提升技术概念掌握度30%以上
[1] Karpicke, J.D., & Blunt, J.R. (2011). Retrieval Practice Produces More Learning than Elaborative Studying. Science.[2] Bjork, R.A. (1994). Memory and Metamemory Considerations. MIT Press.
什么是费曼学习法,具体使用方法?一文讲清费曼学法!:https://xie.infoq.cn/article/391753802b21ea9d99ea6b308 (opens new window)
断墨寻径摘录:https://blog.csdn.net/qq_54088234/article/details/135237324 (opens new window)
做读书笔记的时候有哪些实用的符号?:https://www.zhihu.com/question/24206829 (opens new window)
- 01
- Go语言常见面试题解析(上)语言基础与核心概念05-20
- 03
- AI 写的企业级组件不敢用?我替你验过了05-19
