 Java异常:从原理到实践
Java异常:从原理到实践
# 写在文章开头
日常开发中频繁接触异常,但多数开发者对其底层机制和性能影响缺乏深入理解。对于 Java 异常技术,如果使用得当,异常可以提高程序的可读性、可维护性和健壮性,使用不当则会适得其反。
所以,本文将从异常的核心概念、最佳实践到底层原理,由浅入深地进行全面梳理和分析,希望对你有所帮助。
你好,我是 SharkChili ,Java Guide 核心维护者之一,对 Redis、Nightingale 等知名开源项目有深度源码研究经验。熟悉 Java、Go 等多语言技术栈,现任某知名黑厂高级研发。
🌟 开源项目贡献
- mini-redis:教学级 Redis 精简实现,助力分布式缓存原理学习
🔗 https://github.com/shark-ctrl/mini-redis (opens new window)(欢迎 Star & Contribute)
📚 公众号价值 分享企业级架构设计、性能优化、源码解析等核心技术干货,涵盖分布式系统、微服务治理、大数据处理等实战领域,并探索面向AI的vibe coding等现代开发范式。
👥 加入技术社群 关注公众号,回复 【加群】 获取联系方式,与众多技术爱好者交流分布式架构、微服务等前沿技术!
# 深度解析Java异常机制:从核心概念到最佳实践与底层原理
# 什么是异常
在Java中,"异常"通常指程序执行过程中发生的非正常情况。从异常机制角度,Java异常体系基于Throwable类,分为两大类:
Exception:程序可以捕获并处理的异常Error:严重的系统级错误,一般不应捕获
本文重点讨论Java异常机制,尤其是Exception体系。
引用guide哥的图片,Java异常类体系结构如下图所示,整体来说分为三大类:
checked exceptions:一些三方包方法签名上常会打上这些异常,告知调用者可能需要处理这些异常,需在代码中显式捕获或声明抛出。unchecked exceptions:运行时异常,程序运行期间才可能发生,编译器不强制要求处理。errors:一些比较严重的异常,它表示合理的应用程序不应尝试捕获的严重问题。
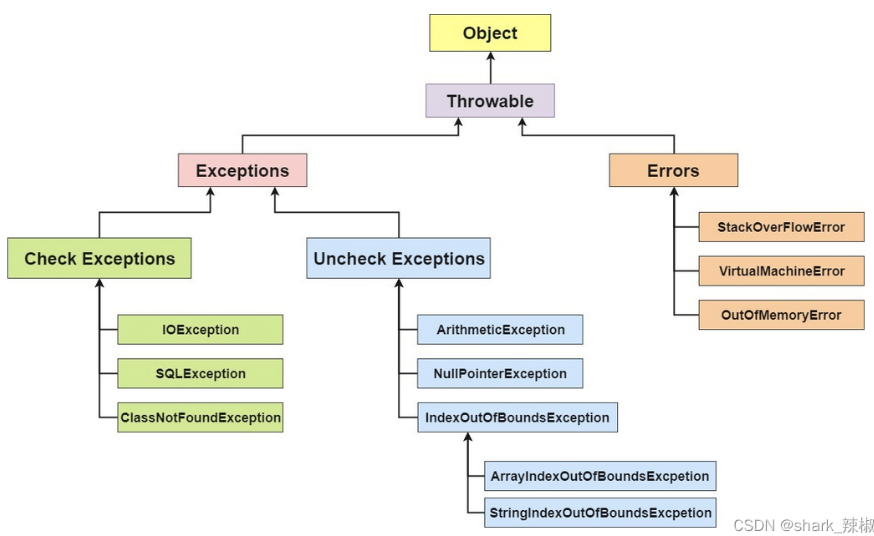
# 受检异常、非受检异常与Error的区别
前文提到,Java 异常体系基于 Throwable 类,整体分为三大类,下面分别说明。
Exception及其子类的异常对象通常是可以进行捕获和处理的。例如下面这段算术异常,我们就可以手动捕获并处理:
try {
for (int i = 0; i < 30_0000; i++) {
int num = 10 / 0;
System.out.println("Fnum:" + num);
}
} catch (Exception e) {
System.out.println("outerTryCatch 报错");
}
2
3
4
5
6
7
8
从 Exception 的子类来看,又分为受检异常和非受检异常:
- 受检异常(checked):方法在调用时需要对可能抛出的潜在风险进行处理,要么捕获,要么向上抛出声明。
- 非受检异常(unchecked):运行时才可能知晓的异常,该异常可由开发人员结合业务场景确定是否捕获。
关于受检异常和非受检异常,后文将给出具体示例。
与Exception不同,Error表示严重的系统级错误,如OOM(内存溢出)、VirtualMachineError(虚拟机错误)、NoClassDefFoundError(类定义错误)等。这类错误通常导致应用程序崩溃,一般情况下不应捕获,而是需要定位并修复根本问题。
# 受检异常和非受检异常的区别
从编译期检查的角度,两者的核心区别如下:
| 维度 | 受检异常 | 非受检异常 |
|---|---|---|
| 编译期检查 | 强制处理,否则编译失败 | 不强制处理,编译通过 |
| 继承关系 | 继承 Exception(非 RuntimeException) | 继承 RuntimeException |
| 典型场景 | 外部资源操作、可恢复的业务异常 | 编程错误、不可恢复的运行时错误 |
# 受检异常:编译期强制处理
受检异常是指在方法签名中通过 throws 声明的异常,调用方必须在编译期显式处理(捕获或继续声明抛出)。这类异常通常表示可预见且可恢复的异常情况,例如:
- 文件操作:
FileNotFoundException - 网络通信:
SocketTimeoutException - 数据库访问:
SQLException
以 FileInputStream 为例,其构造方法声明了 FileNotFoundException:
public FileInputStream(String name) throws FileNotFoundException {
this(name != null ? new File(name) : null);
}
2
3
调用时若不处理该异常,编译器将报错:
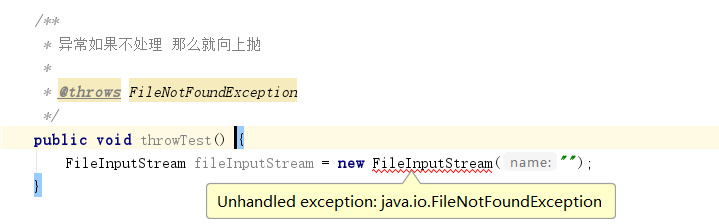
正确的处理方式如下:
// 方式一:try-catch 捕获处理
try {
FileInputStream fis = new FileInputStream("config.txt");
// 使用文件流...
} catch (FileNotFoundException e) {
logger.error("配置文件不存在", e);
}
// 方式二:继续声明抛出
public void loadConfig() throws FileNotFoundException {
FileInputStream fis = new FileInputStream("config.txt");
}
2
3
4
5
6
7
8
9
10
11
12
# 非受检异常:运行时才暴露
非受检异常是指 RuntimeException 及其子类,编译器不强制要求处理。这类异常通常表示编程错误或系统级问题,例如:
NullPointerException:空指针访问IllegalArgumentException:非法参数ArithmeticException:算术运算异常ArrayIndexOutOfBoundsException:数组越界
以下代码编译期正常通过,但运行时抛出异常:
public class ArithmeticDemo {
public static void main(String[] args) {
int num = 10 / 0; // 编译通过,运行时抛出 ArithmeticException
System.out.println("结果:" + num);
}
}
2
3
4
5
6
# 非受检异常的 throws 声明规则
需要特别说明的是,抛出 RuntimeException 或其子类时,方法签名上无需 throws 声明。这是 Java 语言规范的明确约定:
class Calculator {
/**
* 执行除法运算,对非法参数抛出运行时异常
*/
int divide(int a, int b) {
if (b < 0) {
throw new IllegalArgumentException("除数不能为负数: " + b);
}
if (b == 0) {
throw new ArithmeticException("除数不能为零");
}
return a / b;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
设计原理:根据《Effective Java》第71条,
RuntimeException代表编程错误或不可恢复的运行时条件,调用方通常无法有效恢复。因此,设计者选择不强制编译期处理,由开发人员根据实际场景决定是否捕获。
# throw与throws的区别
throw 和 throws 是 Java 异常处理机制中的两个关键字,虽然名称相似,但用途和语法完全不同:
| 对比维度 | throw | throws |
|---|---|---|
| 位置 | 方法体内 | 方法签名上 |
| 作用 | 抛出异常对象 | 声明方法可能抛出的异常类型 |
| 后面跟什么 | 单个异常对象(new XxxException()) | 一个或多个异常类名 |
| 执行时机 | 执行到该语句时立即抛出 | 编译期检查,告知调用者需处理 |
| 适用异常类型 | 受检异常和非受检异常均可 | 主要用于受检异常 |
# throw 用法
throw 用于在方法体内主动抛出异常对象:
public void setAge(int age) {
if (age < 0) {
throw new IllegalArgumentException("年龄不能为负数: " + age);
}
this.age = age;
}
2
3
4
5
6
# throws 用法
throws 用于在方法签名上声明可能抛出的受检异常:
// 声明单个异常
public void readFile(String path) throws FileNotFoundException {
FileInputStream fis = new FileInputStream(path);
}
// 声明多个异常
public void loadData(String path) throws FileNotFoundException, IOException {
FileInputStream fis = new FileInputStream(path);
// 读取数据...
}
2
3
4
5
6
7
8
9
10
# 核心区别总结
- throw:是一个动作,用于在代码中主动抛出异常对象
- throws:是一个声明,用于告知调用者该方法可能抛出哪些异常,由调用者决定如何处理
注意:
throws声明的非受检异常(RuntimeException及其子类)不会强制调用者处理,仅作为文档提示。
# 异常常用方法和使用示例
Throwable 类提供了多种获取异常信息的方法,开发者可根据日志需求选择:
| 方法 | 返回内容 | 是否含堆栈 | 适用场景 |
|---|---|---|---|
getMessage() | 异常的简要描述 | ❌ | 仅需错误原因 |
toString() | 异常类名 + 详细消息 | ❌ | 需要异常类型信息 |
getLocalizedMessage() | 本地化的异常描述 | ❌ | 国际化场景 |
printStackTrace() | 完整堆栈追踪 | ✅ | 调试和问题定位 |
以下面代码为例,对比各方法输出:
try {
int result = 10 / 0;
} catch (ArithmeticException e) {
System.out.println("getMessage: " + e.getMessage());
System.out.println("toString: " + e.toString());
System.out.println("getLocalizedMessage: " + e.getLocalizedMessage());
System.out.println("printStackTrace:");
e.printStackTrace();
}
2
3
4
5
6
7
8
9
输出结果:
getMessage: / by zero
toString: java.lang.ArithmeticException: / by zero
getLocalizedMessage: / by zero
printStackTrace:
java.lang.ArithmeticException: / by zero
at com.example.Main.main(Main.java:5)
2
3
4
5
6
实践建议:生产环境推荐使用日志框架(如 SLF4J)记录异常,将异常对象作为最后一个参数传入,自动打印完整堆栈:
logger.error("操作失败,参数: {}", param, e);
# 自定义异常最佳实践
上文介绍了受检异常的基本用法,这里补充自定义异常的设计建议:
推荐做法:提供包含详细信息的构造方法,而非仅重写 getMessage():
// 推荐:提供丰富的构造方法
public class BusinessException extends Exception {
private final String errorCode;
public BusinessException(String errorCode, String message) {
super(message);
this.errorCode = errorCode;
}
public BusinessException(String errorCode, String message, Throwable cause) {
super(message, cause);
this.errorCode = errorCode;
}
public String getErrorCode() {
return errorCode;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
使用示例:
public void withdraw(Long userId, BigDecimal amount) throws BusinessException {
BigDecimal balance = accountService.getBalance(userId);
if (balance.compareTo(amount) < 0) {
throw new BusinessException("INSUFFICIENT_BALANCE",
"余额不足,当前余额: " + balance + ", 提现金额: " + amount);
}
// 执行提现逻辑...
}
2
3
4
5
6
7
8
这样设计的好处:
- 异常信息包含业务上下文(错误码、具体数值)
- 支持异常链传递(cause 参数)
- 便于上层统一处理和国际化
了解了异常的基本使用后,我们来看看 try-catch 在 JVM 层面是如何工作的。
# try-catch运行原理
从 JVM 层面理解异常处理机制,有助于编写更高效的代码。
# 异常抛出与捕获流程
当 try 块中抛出异常时,JVM 的处理流程如下:
- 创建异常对象:执行
throw语句时,JVM 在堆上创建对应的异常对象 - 遍历异常表:JVM 查询当前方法的异常表,寻找匹配的 catch 块
- 栈帧展开:若当前方法无匹配项,JVM 沿调用栈向上查找,直到找到匹配的 catch 块或程序终止
# 异常表(Exception Table)底层机制
编译后的字节码中包含一张异常表,记录每个 catch 块的捕获范围和异常类型。以下面的代码为例:
public class ExceptionDemo {
public static void main(String[] args) {
int a = 10, b = 0;
try {
int result = a / b; // try 块
} catch (ArithmeticException e) {
System.out.println("除数不能为零"); // catch 块
} finally {
System.out.println("清理资源"); // finally 块
}
}
}
2
3
4
5
6
7
8
9
10
11
12
使用 javap -v ExceptionDemo 查看字节码,可以看到如下异常表:
Exception table:
from to target type
5 9 20 Class java/lang/ArithmeticException
5 9 40 any
20 29 40 any
40 42 40 any
2
3
4
5
6
异常表字段含义:
| 字段 | 含义 |
|---|---|
from | 监控范围的起始字节码偏移量 |
to | 监控范围的结束偏移量(不包含) |
target | 异常处理代码的起始偏移量 |
type | 捕获的异常类型(any 表示任意异常) |
逐行解读异常表:
| 行号 | 监控范围 | 目标位置 | 类型 | 含义 |
|---|---|---|---|---|
| 1 | 5-9 | 20 | ArithmeticException | try 块内抛出 ArithmeticException,跳转到 catch 块(偏移量 20) |
| 2 | 5-9 | 40 | any | try 块内抛出其他异常,跳转到 finally 块(偏移量 40) |
| 3 | 20-29 | 40 | any | catch 块内抛出异常,跳转到 finally 块 |
| 4 | 40-42 | 40 | any | finally 块自身异常的处理(防止无限递归) |
从这个异常表可以看出 finally 的实现本质:JVM 为 try 块和 catch 块都生成了指向 finally 的异常表条目,确保无论是否发生异常、是否捕获异常,finally 块都会执行。
# 性能影响
理解异常表机制后,可以明确异常处理的性能开销来源:
- 创建异常对象:需填充堆栈轨迹,涉及
StackTraceElement数组创建 - 遍历异常表:虽然是 O(n) 操作,但需在异常发生时执行
- 栈帧展开:沿调用栈查找匹配项,调用层次越深开销越大
因此,异常机制不适合用于正常的控制流,应仅用于真正的异常情况。
# Effective Java中关于异常的最佳实践
# 在正确的场景使用异常
明确java异常基本概念之后,我们再来聊聊异常的一些最佳实践。按照《 Effective Java》一书中的说法,设计者明确说明异常机制应用于异常情况,而不是用于普通的控制流。
例如:开发人员采用循环+指针递进的方式进行迭代,这完全是一种基于错误的推理得出的错误优化的尝试。
int[] arr = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
int i = 0;
try {
while (true) {
int num = arr[i++];
//do something
}
} catch (ArrayIndexOutOfBoundsException e) {
//do something
}
2
3
4
5
6
7
8
9
10
11
其推理逻辑为:因为JVM虚拟机在获取元素时会对数组进行越界测试,所以对于循环终止条件测试就是多余的,应该在代码层面上避免。例如下面这段经典的for-each循环,JVM底层会将其编译为for-range循环:
// foreach 底层实际编译为:
// for (int i = 0; i < arr.length; i++) { int i1 = arr[i]; ... }
for (int i1 : arr) {
//do something
}
2
3
4
5
对应for-each编译优化可通过解析字节码印证:
L1
ALOAD 1 // 加载数组 arr
ASTORE 2
ALOAD 2
ARRAYLENGTH // 获取数组长度
ISTORE 3 // 存储长度到变量3
ICONST_0
ISTORE 4 // int i = 0 (计数器)
L2
ILOAD 4 // 加载 i
ILOAD 3 // 加载长度
IF_ICMPGE L3 // if i >= length 跳转到 L3 (结束循环)
ALOAD 2 // 加载数组
ILOAD 4 // 加载 i
IALOAD // arr[i]
ISTORE 5 // int i1 = arr[i]
... // 循环体代码
IINC 4 1 // i++
GOTO L2 // 跳回 L2 继续循环
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
而指针递进+while迭代的代码设计就是考虑到JVM底层存在数组访问越界的检测,所以采用了激进的异常处理控制流的运转。
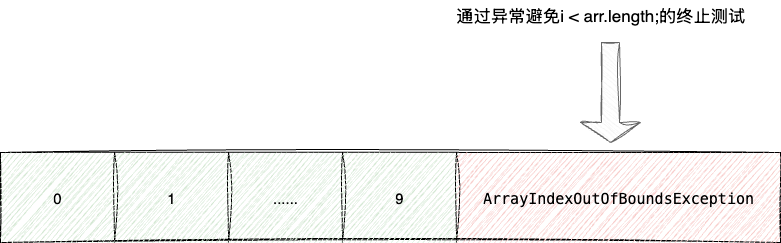
这其中是一种过度 "优化" 的设计,它存在以下几个弊端:
- 抑制JIT优化:将代码放在try-catch块内,抑制了JVM某些可能的优化操作,使得程序执行性能下降
- 低效的迭代效率:异常机制是针对异常情况设计,JVM设计者没有什么动力将其优化得像显示条件测试(i < arr.length)一样高效,这一点笔者也会在后续篇幅中给出实验结果。
- 冗余操作:采用标准语法的数组迭代未必会导致多余的检查,许多JVM实现会将终止检查操作优化掉。
所以,最佳实践是正确识别异常使用的场景,即对于逻辑流的控制优先采用合理的API处理,而非捕获异常手动控制流的运转:
List<User> list = Arrays.asList(new User("name", 18),
new User("name2", 19));
for (User user : list) {
//do something
}
2
3
4
5
为了更直观地说明异常控制流程的性能问题,我们再看一个 Stack 出栈的性能对比实验:用 try-catch 控制循环 vs 使用标准 for 循环控制:
public static void stackPopByCatch() {
long start = System.currentTimeMillis();
try {
Stack stack = new Stack();
for (int i = 0; i < 1000_0000; i++) {
stack.push(i);
}
while (true) {
try {
stack.pop();
} catch (Exception e) {
System.out.println("出栈结束");
break;
}
}
} catch (Exception e) {
}
long end = System.currentTimeMillis();
System.out.println("使用try进行异常捕获,执行时间:" + (end - start));
start = System.currentTimeMillis();
Stack stack2 = new Stack();
for (int i = 0; i < 1000_0000; i++) {
stack2.push(i);
}
int size = stack2.size();
for (int i = 0; i < size; i++) {
stack2.pop();
}
end = System.currentTimeMillis();
System.out.println("使用逻辑进行出栈操作,执行时间:" + (end - start));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
输出结果,可以看到用 try 块控制业务流程性能相差近一倍:
出栈结束
使用try进行异常捕获,执行时间:2613
使用逻辑进行出栈操作,执行时间:1481
2
3
补充说明:上述性能测试仅使用
System.currentTimeMillis()粗略计时,结果受 JVM 预热、系统负载等因素影响。如需更精确的基准测试数据,建议使用 JMH(Java Microbenchmark Harness)框架进行测量。
# 受检异常和运行时异常的使用技巧
异常体系存在check exception和runtime exception以及error三大体系,正确的理解并在合适的场景使用这些异常有助于我们编写出健壮且易于维护的程序。
我们更多的是的讨论受检异常(check exception)和非受检异常(runtime exception),就笔者个人经验而言,二者并没有很明显的区分,使用建议如下:如果调用者能够从异常中恢复,就使用受检异常。
例如下面这段代码,即开发者明确知晓网络的不可靠性,在编写创建连接的方法时抛出超时异常,外部调用者可以利用方法签名进行重连:
public static void main(String[] args) {
int retryCount = 0;
while (retryCount < MAX_RETRY_COUNT) {
retryCount++;
try {
Socket socket = createConnection(HOST, PORT);
System.out.println("连接成功!");
// 使用socket进行通信...
break;
} catch (SocketTimeoutException e) { //捕获超时的受检异常,进行重试
System.err.println("第 " + retryCount + " 次连接超时");
if (retryCount >= MAX_RETRY_COUNT) {
System.err.println("达到最大重试次数,放弃连接");
}
}
}
}
/**
* 创建连接,超时抛出异常
*/
public static Socket createConnection(String host, int port) throws SocketTimeoutException {
Socket socket = new Socket();
try {
socket.connect(new InetSocketAddress(host, port), CONNECT_TIMEOUT);
return socket;
} catch (SocketTimeoutException e) {
throw e;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
对于error和runtime exception而言,二者在某些行为上是相同的:它们都不需要,也不应该捕获。如果程序抛出运行时异常亦或者错误,这就意味代码实现逻辑或者程序在运行时出现了不可恢复的错误,继续执行只会弊大于利,应抛出适当的错误信息并停止。
# 避免非必要的受检异常
受检异常是针对可以感知,且强制程序员处理的问题,适时的使用可以有效提升程序的健壮性。但是过度的使用受检异常,会成为某些API操作的阻碍。最典型的案例就是JDK 8中针对受检异常的方法,无法在流操作中使用:
public static void main(String[] args) {
List<User> list = Arrays.asList(new User("Alice", 25), new User("Bob", 30));
List<Map<String, Object>> mapList = list.stream()
.map(user -> convertToMap(user)) //抛出受检异常,无法通过编译
.collect(Collectors.toList());
//do something
}
public static Map<String, Object> convertToMap(User user) throws Exception {
if (user == null) {
throw new Exception("User cannot be null");
}
//......
Map<String, Object> map = new HashMap<>();
map.put("name", user.getName());
map.put("age", user.getAge());
return map;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
所以,对于受检异常的使用,我们建议应在满足以下两个条件的情况下使用: 1. 异常条件无法通过正确的使用API防止,例如某些远程调用无法用optional进行封装判空 2. 一旦出现异常,程序员可以采用有效动作恢复状态
如果无法满足上述两个条件,我们就应该使用非受检异常。
如果方法仅存在一个受检异常能够准确处理的场景下,我们要学会尽可能避免使用受检异常,确保顺畅使用流操作。
上述的流操作,结合业务推理可看出,是针对有效用户数据的类型转换,针对非合法的空对象抛出异常让上层着手处理。实际上针对该逻辑,我们完全可以通过返回Optional实例让上层调用者感知转换是否成功。
修改后的代码如下所示,大体思路为:
- 将受检异常转为Optional受检状态,若转换成功则存入map实例,反之存入null
- 上层调用者不再处理受检异常,取而代之使用optional检测状态
- 通过filter过滤生成有效实例
这样做不仅避免了处理异常的开销,还保证了流操作的可读性和可维护性:
List<Map<String, Object>> mapList = list.stream()
.map(user -> convertToMap(user).orElse(null)) // 利用optional感知实例转换有效性
.filter(Objects::nonNull) //有效过滤
.collect(Collectors.toList());
public static Optional<Map<String, Object>> convertToMap(User user) {
if (user == null) {
return Optional.empty();
}
if (user.getName() == null || user.getName().trim().isEmpty()) {
return Optional.empty();
}
if (user.getAge() < 0 || user.getAge() > 150) {
return Optional.empty();
}
Map<String, Object> map = new HashMap<>();
map.put("name", user.getName());
map.put("age", user.getAge());
return Optional.of(map);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 优先使用标准异常
计算机程序设计一直是一门讲究复用的学科,异常使用亦是同理,Java类库内置了许多高度抽象的标准异常,可以满足大多数API抛出异常的需求。
下面笔者就结合一些实际的场景给出相应异常使用实践,针对参数合法性校验,推荐采用IllegalArgumentException向上传递:
public static void validateUser(User user) {
if (user.getName() == null || user.getName().trim().isEmpty()) {
throw new IllegalArgumentException("用户名不能为空");
}
if (user.getAge() == null) {
throw new IllegalArgumentException("年龄不能为空");
}
}
2
3
4
5
6
7
8
9
针对非法的状态示例,例如:对象尚未初始化、对象状态异常不符合业务操作要求,应统一抛出IllegalStateException:
public static void checkUserState(User user) {
if (user.isDeleted()) {
throw new IllegalStateException("用户已注销,无法执行此操作");
}
updateUser(user);
}
2
3
4
5
6
7
还有一些可复用的异常是ConcurrentModificationException,该异常主要是针对以下两种场景:
- 对象被设计为供单线程使用,不允许并发修改
- 存在同步操作机制
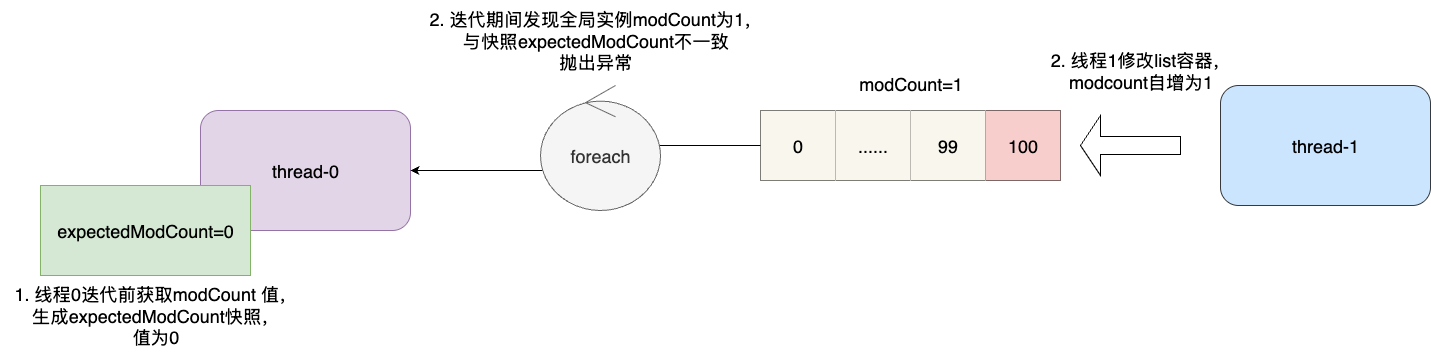
该异常最典型的应用就是ArrayList,该容器是典型的单线程操作容器,其底层通过在进行读写操作时都会采用一个变量modCount来感知是否存在并发操作,例如:当我们进行迭代操作时,forEach函数的执行逻辑为:
- 创建一个不可变的变量expectedModCount拷贝modCount当前的值,作为后续的校验快照
- 比对实例变量modCount与expectedModCount是否一致,若一致则说明遍历期间,容器没有被修改,若不一致则进入步骤3
- 说明当前容器被其他线程修改,存在一致性问题,抛出ConcurrentModificationException
注意ConcurrentModificationException充其量只是一个提示,它无法有效的阻断并发修改操作:
因为ConcurrentModificationException在日常工程实践中比较少用到,所以笔者索性从JDK源代码ArrayList的forEach中作为最佳实践的案例,逻辑和上述说明一致:
- 创建不可变参数expectedModCount拷贝全局示例modCount快照
- 比对二者差异,感知是否存在并发修改
- 出现不一致,则跳出循环抛出ConcurrentModificationException
@Override
public void forEach(Consumer<? super E> action) {
Objects.requireNonNull(action);
//拷贝modCount快照
final int expectedModCount = modCount;
@SuppressWarnings("unchecked")
final E[] elementData = (E[]) this.elementData;
final int size = this.size;
//比对快照和全局变量是否不一致,以确认是否存在并发修改操作
for (int i=0; modCount == expectedModCount && i < size; i++) {
action.accept(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
基于ConcurrentModificationException,我们再给出一些不错的实践。上文说到ConcurrentModificationException无法杜绝并发修改。所以,对于需要阻断并发操作亦或者说要阻断非法操作的,可参考Arrays.asList方法底层的add方法的实现。针对所有非法写操作直接在逻辑层面抛出UnsupportedOperationException:
public void add(int index, E element) {
throw new UnsupportedOperationException();
}
2
3
其他方面例如空校验异常,则直接采用NullPointerException,这里就不多做赘述:
if (key == null)
throw new NullPointerException();
2
标准异常使用场景总结:
| 场景 | 异常类型 |
|---|---|
| 参数合法性校验 | IllegalArgumentException |
| 状态合法性校验 | IllegalStateException |
| 并发修改检测 | ConcurrentModificationException |
| 阻断非法操作 | UnsupportedOperationException |
| 空值校验 | NullPointerException |
# 合理抛出异常信息
异常应结合当前方法抽象维度进行转译,并抛出正确的异常信息,确保调用者能够理解异常。
举个不是很规范的例子:我们编写一个访问列表操作的getElement方法,在执行元素返回操作时,底层的数据结构可能会返回越界异常。默认情况下会抛出IndexOutOfBoundsException:
public static String getElement(List<String> list, int index) {
return list.get(index);//可能抛出IndexOutOfBoundsException
}
2
3
对于我们当前方法的抽象维度即元素读取操作,所以我们应针对该异常做一个特殊的语义上的转换。例如:我们用链表实现一个栈,在pop操作时,存在NoSuchElementException的风险。考虑到该异常不符合当前API层面即pop操作的语义抽象,最佳实践则是将其转译为自定义StackEmptyException,让上层明白该异常原因是栈为空:
public E pop() throws StackEmptyException {
try {
return list.removeFirst();
} catch (NoSuchElementException e) {//将链表的NoSuchElementException异常转换为自定义的StackEmptyException异常
throw new StackEmptyException("Stack is empty");
}
}
2
3
4
5
6
7
# 尽可能给出详尽异常信息
抛出异常的目的,是为了了解程序的情况,并采用合适的策略解决问题。对于异常的故障信息,我们应详细提供导致该异常的参数和值。例如:JDK底层对于列表越界访问异常,就会在IndexOutOfBoundsException构造函数基础之上给出非法访问的索引和当前列表大小信息:
private void rangeCheck(int index) {
if (index < 0 || index >= this.size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
private String outOfBoundsMsg(int index) {
return "Index: "+index+", Size: "+this.size;
}
2
3
4
5
6
7
8
9
需要特别注意:异常的堆栈轨迹信息可能会被很多人看到,因此不要将密码、密钥等重要的信息包含在异常详细信息中。
# 保持异常原子性
抛出异常时,应确保当前逻辑状态的原子性,即异常前后状态是一致的。例如:ArrayBlockingQueue要求添加的元素是非空的,所以为了保证处理异常后,队列内部原子性,会在添加操作前检查元素状态,提前抛出异常,避免队列状态原子性遭到破坏:
public boolean offer(E e) {
//fail-fast提前感知异常并抛出,保证异常操作前后的原子性
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lock();
try {
// 添加元素逻辑...
return true;
} finally {
lock.unlock();
}
}
private static void checkNotNull(Object v) {
if (v == null)
throw new NullPointerException();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
所以,对于异常原子性问题,核心目的就是要做到抛出异常前后状态一致。对于这种异常原子性的处理,常见的方案有4种: 1.快速失败: 提前检查感知并抛出,不修改当前状态,参考上文ArrayBlockingQueue的offer操作。
2.写时复制(copy on write) 拷贝当前处理对象信息,若出现异常直接抛出,不破坏当前对象的状态,参考CopyOnWriteArrayList的add方法,其内部会通过拷贝原数组的方式执行修改操作,只有明确操作成功的情况下才会原子覆盖旧有对象:
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
//基于原数组拷贝一个新的数组,执行修改操作
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
//明确操作成功后原子覆盖
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
3. 手动回滚: 这种做法相对少见,也不太推荐,即在逻辑执行发生异常后将修改的状态还原。例如下面这段这段针对user对象的操作,在业务节点执行过程中出现异常,开发者手动将状态还原并返回:
/**
* 更新用户信息,异常时回滚修改
* @param user 待更新的用户对象
* @param newName 新用户名
* @param newAge 新年龄
*/
public static void updateUserWithRollback(User user, String newName, Integer newAge) {
// 保存原始值,用于异常时回滚
String oldName = user.getName();
Integer oldAge = user.getAge();
try {
// 修改用户信息
user.setName(newName);
user.setAge(newAge);
// 执行后续业务逻辑
doSomething();
} catch (Exception e) {
// 发生异常,回滚到原始值
user.setName(oldName);
user.setAge(oldAge);
// 重新抛出异常,让上层处理
throw e;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
4. 不可变对象: 通过对象不可变性,确保异常处理状态前后的一致性,参考String的replace方法。因为String设计的不可变性,对于替换操作都是采用创建新对象的方式完成修改:
public String replace(char oldChar, char newChar) {
if (oldChar != newChar) {
int len = value.length;
//......
if (i < len) {
//基于原字符长度创建新数组
char buf[] = new char[len];
//拷贝原字符串信息
for (int j = 0; j < i; j++) {
buf[j] = val[j];
}
//执行替换操作,并返回修改后的全新对象
while (i < len) {
char c = val[i];
buf[i] = (c == oldChar) ? newChar : c;
i++;
}
return new String(buf, true);
}
}
return this;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 不要忽略异常
这一点其实是众所周知的一些定论了,受检异常势必是要求调用者手动进行相应兜底处理。唯一需要补充说明的是,如果明确要忽略受检异常处理,我们需要怎么做?
按照代码整洁之道的说法:
声明的变量、函数或者类的名称在阅读时,应能够交待所有的问题,它能够告诉你为什么存在、做什么事、该怎么用。如果一个名称需要注释补充说明,那就不算名副其实。
所以,对于可忽略的异常,我们也应该在变量声明时体现可忽略,同时在逻辑代码块中注释说明这样做为什么是合适的。例如:我们通过TimeUnit封装了一个线程休眠方法yield。按照TimeUnit设计者的考量,线程会因为中断操作而结束休眠,所以会抛出InterruptedException受检异常。
但是我们的场景仅仅是基于sleep操作让出CPU时间片,且所有中断操作都被重写覆盖,不存在这种情况。在明确异常无需处理的情况下,catch块标注异常可忽略,并通过注释说明原因,提升程序可读性和可维护性:
public static void yield(long time, TimeUnit unit) {
try {
unit.sleep(time);
} catch (InterruptedException ignored) {
//所有线程中断操作都被阻断,不存在中断异常
}
}
2
3
4
5
6
7
# 异常使用注意事项
# 多异常捕获处理技巧
多异常捕获应遵循以下原则:
- 有几个异常就处理几个异常,无法处理则向上抛出
- 父类
Exception放在最下方 - 使用
|运算符合并相同处理逻辑的异常
假设方法抛出多个异常,其中 UnknownHostException 是用户配置问题无法处理,应向上抛出:
private int calculate(int number, int divNum)
throws ArithmeticException, FileNotFoundException, UnknownHostException, IOException {
if (divNum == 0) {
throw new ArithmeticException();
}
return number / divNum;
}
2
3
4
5
6
7
使用 | 运算符合并相同处理逻辑的异常,使代码更简洁:
int number = 20;
int result = 0;
try {
result = calculate(number, 0);
} catch (ArithmeticException | FileNotFoundException e) {
logger.error("计算出错或文件不存在,参数:{}, 错误:{}", number, e.getMessage(), e);
} catch (IOException e) {
logger.error("IO异常,参数:{}, 错误:{}", number, e.getMessage(), e);
} catch (Exception e) {
logger.error("未知异常,参数:{}, 错误:{}", number, e.getMessage(), e);
}
2
3
4
5
6
7
8
9
10
11
注意:使用
|运算符后,异常变量e会变为final,无法重新赋值。
# finally 关键字详解
finally 块无论是否发生异常,在 try 块结束后必定执行。
# finally 不执行的场景
以下情况 finally 不会执行:
- 调用
System.exit(0)或Runtime.halt() - JVM 崩溃(如内存不足)
- 守护线程结束时
public void finallyNotRun() {
try {
System.out.println("try block");
System.exit(0); // finally 不会执行
} finally {
System.out.println("finally block");
}
}
2
3
4
5
6
7
8
# 不要在 finally 中使用 return
finally 中的 return 会覆盖 try/catch 的返回值:
public int func() {
try {
return 1; // 被覆盖
} finally {
return 2; // 实际返回值
}
}
2
3
4
5
6
7
# 资源释放的最佳实践
传统方式需要在 finally 中手动释放资源:
Scanner scanner = null;
try {
scanner = new Scanner(new File("read.txt"));
// 使用 scanner...
} finally {
if (scanner != null) {
scanner.close();
}
}
2
3
4
5
6
7
8
9
推荐使用 try-with-resources 语法,代码更简洁:
try (Scanner scanner = new Scanner(new File("read.txt"))) {
// 使用 scanner...
} catch (FileNotFoundException e) {
logger.error("文件不存在", e);
}
2
3
4
5
try-with-resources适用于所有实现了AutoCloseable或Closeable接口的类。
# 异常不处理就抛出
捕获异常是为了处理它,不应捕获后什么都不做。如果当前层无法处理,应向上抛出:
public class MyIllegalArgumentException extends Exception {
public MyIllegalArgumentException(String msg) {
super(msg);
}
}
private void check(String str) throws MyIllegalArgumentException {
if (str == null || str.isEmpty()) {
throw new MyIllegalArgumentException("字符串不可为空");
}
}
2
3
4
5
6
7
8
9
10
11
最外层调用者必须处理异常,转化为用户可理解的提示。
# 规范异常日志打印
日志打印应遵循以下原则:
- 不要使用
JSON工具序列化对象,某些get方法可能会抛出异常 - 记录参数、错误信息、堆栈信息
public void logShowTest() {
Map inputParam = new JSONObject().fluentPut("key", "value");
try {
logShow(inputParam);
} catch (ArithmeticException e) {
logger.error("inputParam:{} ,errorMessage:{}", inputParam.toString(), e.getMessage(), e);
}
}
private int logShow(Map inputParam) throws ArithmeticException {
int zero = 0;
if (zero == 0) {
throw new ArithmeticException();
}
return 19 / zero;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
输出结果:
[main] ERROR com.guide.exception.ExceptionTest - inputParam:{"key":"value"} ,errorMessage:null
com.guide.exception.ArithmeticException
at com.guide.exception.ExceptionTest.logShow(ExceptionTest.java:166)
2
3
# 避免频繁抛出和捕获异常
如下代码所示,可以看到频繁抛出和捕获异常是非常耗时的,所以我们不建议使用异常来作为处理逻辑,我们完全可以和前端协商好错误码从而避免没必要的性能开销:
private int testTimes;
public ExceptionTest(int testTimes) {
this.testTimes = testTimes;
}
public void newObject() {
long l = System.currentTimeMillis();
for (int i = 0; i < testTimes; i++) {
new Object();
}
System.out.println("建立对象:" + (System.currentTimeMillis() - l));
}
public void newException() {
long l = System.currentTimeMillis();
for (int i = 0; i < testTimes; i++) {
new Exception();
}
System.out.println("建立异常对象:" + (System.currentTimeMillis() - l));
}
public void catchException() {
long l = System.currentTimeMillis();
for (int i = 0; i < testTimes; i++) {
try {
throw new Exception();
} catch (Exception e) {
}
}
System.out.println("建立、抛出并接住异常对象:" + (System.currentTimeMillis() - l));
}
public void catchObj() {
long l = System.currentTimeMillis();
for (int i = 0; i < testTimes; i++) {
try {
new Object();
} catch (Exception e) {
}
}
System.out.println("建立,普通对象并catch:" + (System.currentTimeMillis() - l));
}
public static void main(String[] args) {
ExceptionTest test = new ExceptionTest(100_0000);
test.newObject();
test.newException();
test.catchException();
test.catchObj();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
输出结果:
建立对象:3
建立异常对象:484
建立、抛出并接住异常对象:539
建立,普通对象并catch:3
2
3
4
# 尽可能在for循环外捕获异常
上文提到 try-catch 时会捕获并创建异常对象,所以如果在 for 循环内频繁捕获异常会创建大量的异常对象:
public static void main(String[] args) {
outerTryCatch();
innerTryCatch();
}
// for 外部捕获异常
private static void outerTryCatch() {
long memory = Runtime.getRuntime().freeMemory();
try {
for (int i = 0; i < 30_0000; i++) {
int num = 10 / 0;
System.out.println("Fnum:" + num);
}
} catch (Exception e) {
}
long useMemory = (memory - Runtime.getRuntime().freeMemory()) / 1024 / 1024;
System.out.println("cost memory:" + useMemory + "M");
}
// for 内部捕获异常
private static void innerTryCatch() {
long memory = Runtime.getRuntime().freeMemory();
for (int i = 0; i < 30_0000; i++) {
try {
int num = 10 / 0;
System.out.println("num:" + num);
} catch (Exception e) {
}
}
long useMemory = (memory - Runtime.getRuntime().freeMemory()) / 1024 / 1024;
System.out.println("cost memory:" + useMemory + "M");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
输出结果如下,可以看到 for 循环内部捕获异常消耗了 22M 的堆内存。原因很简单,for 外部捕获异常时,会直接终止 for 循环,而在 for 循环内部捕获异常仅结束本次循环,所以如果 for 循环频繁报错,那么在内部捕获异常会创建大量的异常对象。
cost memory:0M
cost memory:22M
2
# 常见面试题解析
# 为什么不建议使用异常控制业务流程
- 《Effective Java》指出,创建异常并抛出的代价昂贵,涉及堆栈轨迹填充、异常对象创建、异常捕获等操作
- 异常旨在处理非正常情况,而非用于控制业务流程
# ClassNotFoundException和NoClassDefFoundError的区别
| 对比项 | ClassNotFoundException | NoClassDefFoundError |
|---|---|---|
| 类型 | 受检异常 | 错误 |
| 触发场景 | 运行时加载类找不到 | 类文件存在但加载/解析失败 |
| 典型案例 | Class.forName("com.mysql.cj.jdbc.Driver") | 编译时存在,运行时 class 文件丢失 |
# 受检异常和非受检异常的区别
| 对比项 | 受检异常 | 非受检异常 |
|---|---|---|
| 编译期检查 | 强制处理 | 不强制 |
| 代表类型 | IOException、SQLException | NullPointerException、IllegalArgumentException |
| 使用场景 | 可恢复的异常 | 代码错误导致的异常 |
📝 选择题练习
36. 以下哪个是检查型异常(Checked Exception)?
A. NullPointerException
B. ArrayIndexOutOfBoundsException
C. IOException
D. RuntimeException
2
3
4
答案:C ✅
37. 以下关于throw和throws的说法,正确的是?
A. throw用于抛出异常对象,throws用于声明方法可能抛出的异常
B. throw用于声明异常,throws用于抛出异常对象
C. throw和throws的作用完全相同
D. throws可以单独使用,不需要throw配合
2
3
4
答案:A ✅
38. 下面代码的输出是什么?
public class Test {
public static void main(String[] args) {
try {
System.out.print("A ");
int x = 1 / 0;
System.out.print("B ");
} catch (ArithmeticException e) {
System.out.print("C ");
} finally {
System.out.print("D ");
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
A. A B C D
B. A B D
C. A C D
D. A C
2
3
4
答案:C ✅
解析:输出A → 执行1/0抛出异常 → B不输出 → 捕获异常输出C → finally执行输出D
39. 以下关于finally块的说法,正确的是?
A. finally块总是会执行
B. finally块在return之前执行
C. 如果finally块中有return语句,会覆盖try中的return
D. 以上全部正确
2
3
4
答案:B、C ✅
注意:A选项错误,调用 System.exit(0) 或 Runtime.halt() 时finally不会执行。因此D选项也错误。
40. 以下关于自定义异常的说法,正确的是?
A. 自定义异常必须直接继承Exception类
B. 自定义异常可以继承Exception类或RuntimeException类
C. 自定义异常必须重写父类的getMessage方法
D. 自定义异常不能有带参数的构造方法
2
3
4
答案:B ✅
# 小结
本文系统梳理了 Java 异常机制的核心知识点:
- 异常体系:Throwable 分为 Exception(可处理)和 Error(系统级错误)
- 受检 vs 非受检:checked 异常需显式处理,unchecked 异常运行时发生
- 处理语法:try-catch-finally、throw、throws 的使用场景和注意事项
- 最佳实践:避免用异常控制流程、规范日志打印、注意性能影响
掌握异常处理是编写健壮 Java 程序的基础,建议结合《Effective Java》和阿里巴巴 Java 开发手册深入理解。
你好,我是 SharkChili ,Java Guide 核心维护者之一,对 Redis、Nightingale 等知名开源项目有深度源码研究经验。熟悉 Java、Go 等多语言技术栈,现任某知名黑厂高级研发。
🌟 开源项目贡献
- mini-redis:教学级 Redis 精简实现,助力分布式缓存原理学习
🔗 https://github.com/shark-ctrl/mini-redis (opens new window)(欢迎 Star & Contribute)
📚 公众号价值 分享企业级架构设计、性能优化、源码解析等核心技术干货,涵盖分布式系统、微服务治理、大数据处理等实战领域,并探索面向AI的vibe coding等现代开发范式。
👥 加入技术社群 关注公众号,回复 【加群】 获取联系方式,与众多技术爱好者交流分布式架构、微服务等前沿技术!
# 参考
Java基础常见面试题总结(下):https://javaguide.cn/java/basis/java-basic-questions-03.html#项目相关 (opens new window)
《Effective Java中文版(第3版)》
阿里巴巴Java开发手册:https://book.douban.com/subject/27605355/ (opens new window)
Java核心技术·卷 I(原书第11版):https://book.douban.com/subject/34898994/ (opens new window)
Java 基础 - 异常机制详解:https://www.pdai.tech/md/java/basic/java-basic-x-exception.html#异常是否耗时为什么会耗时 (opens new window)
面试官问我 ,try catch 应该在 for 循环里面还是外面?:https://mp.weixin.qq.com/s/TQgBSYAhs_kUaScw7occDg (opens new window)
《代码整洁之道》
- 01
- Go语言常见面试题解析(上)语言基础与核心概念05-20
- 03
- AI 写的企业级组件不敢用?我替你验过了05-19
