 Claude Code 记忆管理:CLAUDE.md 最佳实践
Claude Code 记忆管理:CLAUDE.md 最佳实践
# 写在文章开头
笔者此前写过一篇 Claude Code 入门指南,以宏观视角介绍了安装、配置和使用技巧。考虑到读者需要一个相对平缓的进阶路径,本文将聚焦 Claude Code 上下文管理中最核心的文件——CLAUDE.md,从作用、特性到最佳实践进行全面阐述。尚未阅读入门篇的读者,建议先移步: https://mp.weixin.qq.com/s/gfdW208rcGKwb4CZcgyREw (opens new window)
SharkChili · 计算机路上的禅修者
开源贡献
- mini-redis:教学级 Redis 精简实现 · https://github.com/shark-ctrl/mini-redis
- Nightingale:深度源码研究
关注公众号,回复 【加群】 加入技术社群
# 详解CLAUDE.md文件
# CLAUDE.md作用
CLAUDE.md 是由用户手动维护的一份文档,为 Claude Code 提供一个持久的上下文,主要记录项目的构建命令、代码约定、项目结构和开发规范等信息。一般情况下,若出现以下情况,我们非常推荐将其持久化到文件中:
- 避免Claude犯同样的错误
- 需要反复强调的事项
- 代码审查时发现Claude应该了解代码库的内容
- 确保新同事能够快速加入团队的上下文信息
由于 CLAUDE.md 在默认作用域下会在每次会话启动时自动加载,这使得它天生具备跨会话协同的能力——开发者只需维护好当前项目中的 CLAUDE.md,即可在不同会话间传递知识:
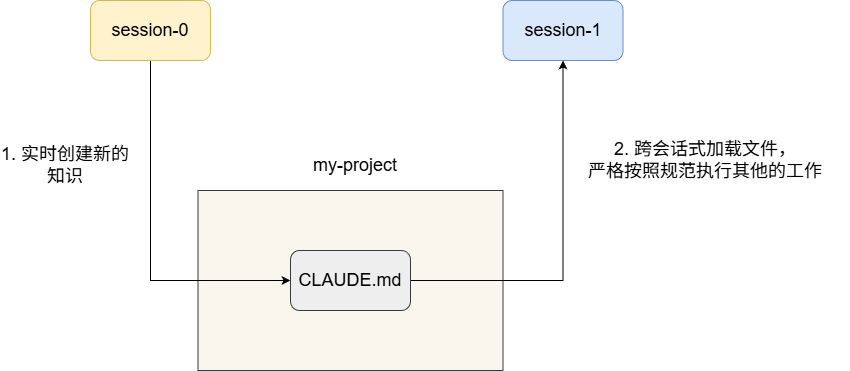
# 如何初始化
Claude Code 内置 /init 指令辅助开发者构建上下文。对于一些相对陌生的项目,建议在阅读完必要的 README.md 之后,键入该指令辅助生成一份初始的 CLAUDE.md 文档:
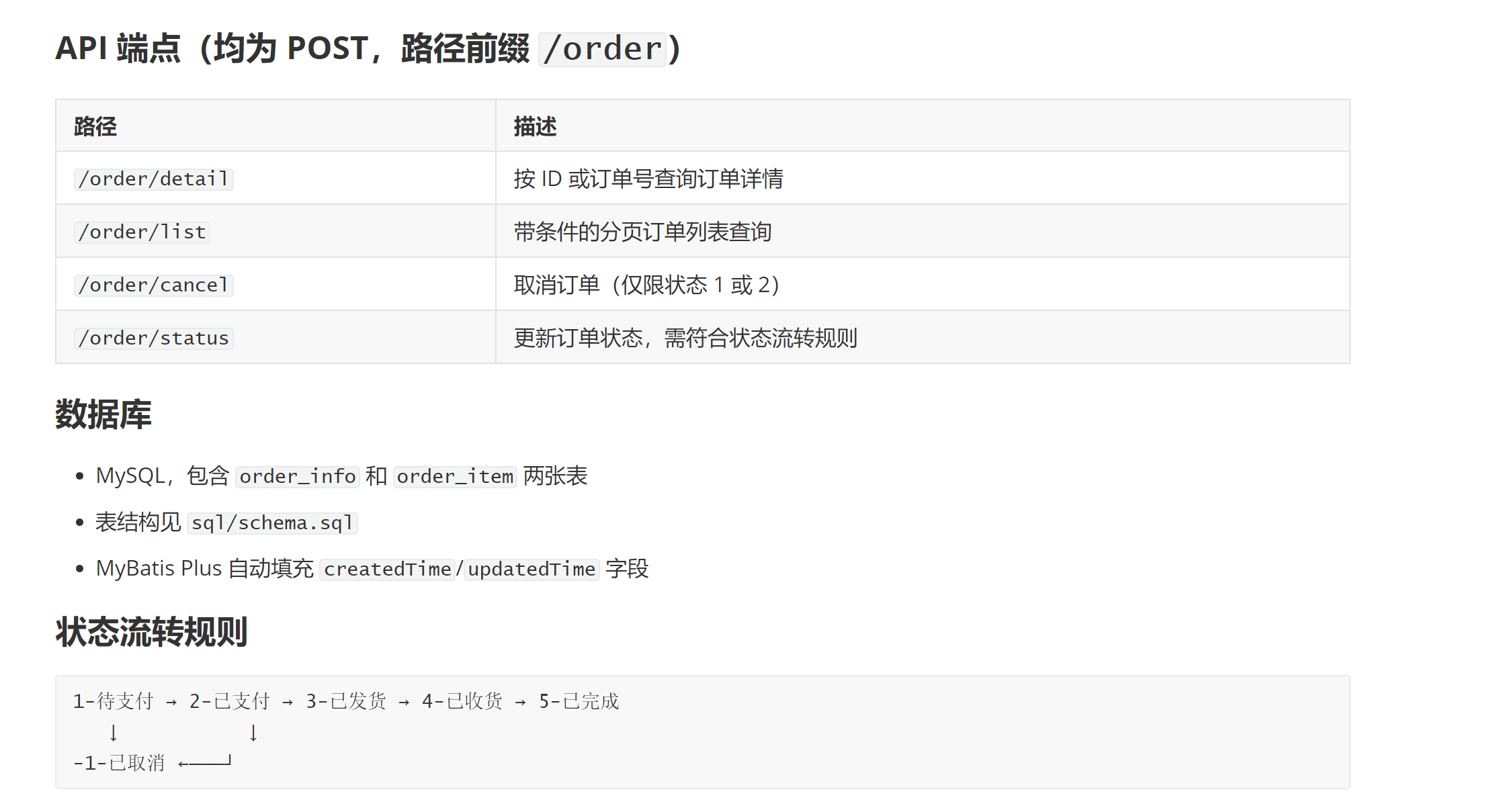
以笔者本次所用的订单服务系统为例,在执行 init 初始化指令之后,Claude Code 会按照官方文档所述,构建出一份包含以下内容的文档:
- 项目概述:这是一个订单管理系统,包含 Spring Boot 2.7.18 后端 和 Vue 3 前端。后端提供
/order/*REST API,前端为基于 Vite 的 Vue 3 单页应用,通过代理将 API 调用转发至后端。 - 构建命令:前后端打包和构建运行的指令,例如:后端项目中指明通过./mvnw clean package执行构建
- 项目布局:前后端包路径和项目结构,以后端为例对应的布局结构介绍如下:

- 开发规范:即业务说明和必要的开发规范,例如:接口全走post
完整的生成结果如下:

# 常见作用域编排
Claude Code 官方针对 CLAUDE.md 的作用域进行了细致的划分与设计。考虑到二八原则——20%的使用技巧覆盖开发工作80%的场景,这里仅给出常见的作用域编排方式。
CLAUDE.md 的作用域在日常开发中可分为用户级、项目级以及项目目录下的个人私有级(CLAUDE.local.md)。按照 Claude Code 官方文档,加载顺序规则为:
- 路径维度:优先加载全局配置,然后加载项目级别 CLAUDE.md
- 文件维度:优先加载 CLAUDE.md,再加载 CLAUDE.local.md
- 覆盖原则:当多个层级的指令存在冲突时,以最后加载的文件为准
接下来通过实验验证上述规则。假设我们在当前项目目录下初始化一个 CLAUDE.md,要求命名规范采用小驼峰,而全局配置则采用下划线。最终与 Claude Code 交互的结果如下——它按照小驼峰的规范执行:
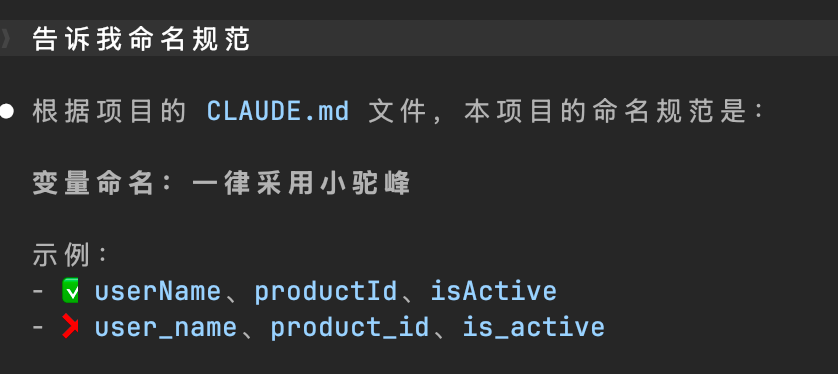
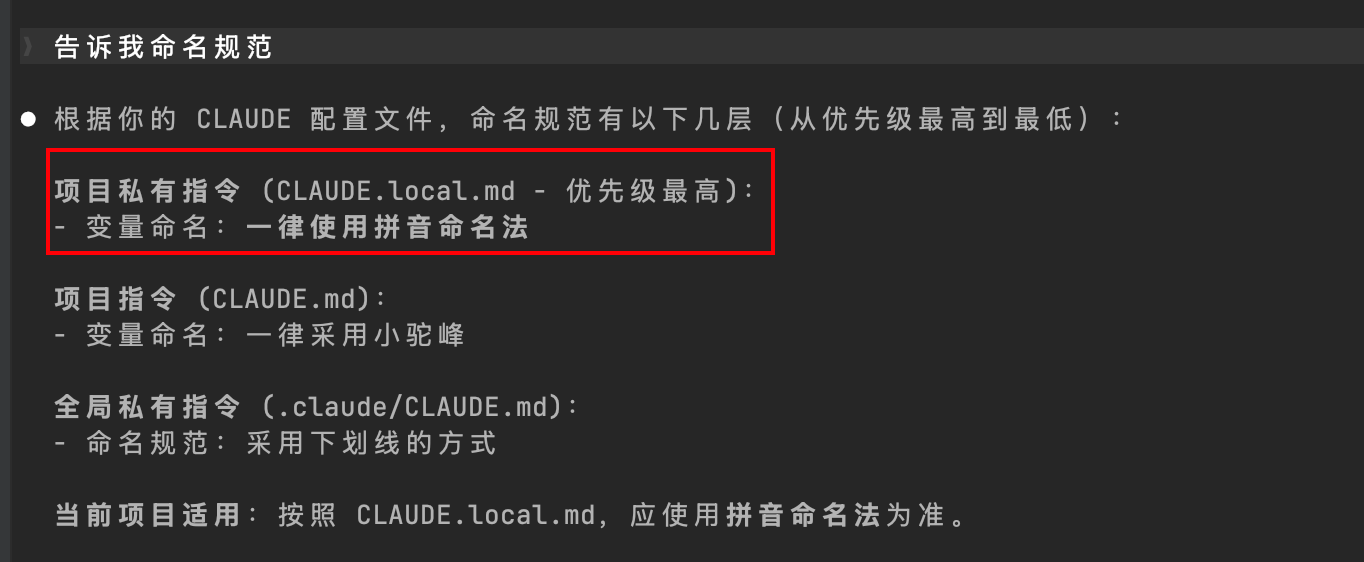
为了直观了解 LLM 内部对于作用域的加载顺序和覆盖原则的处理逻辑,笔者采用了提示词工程中经典的调试技巧:让模型在输出结果时,额外解释其推导过程。以当前内容为例,即要求模型解释变量命名规范的依据:
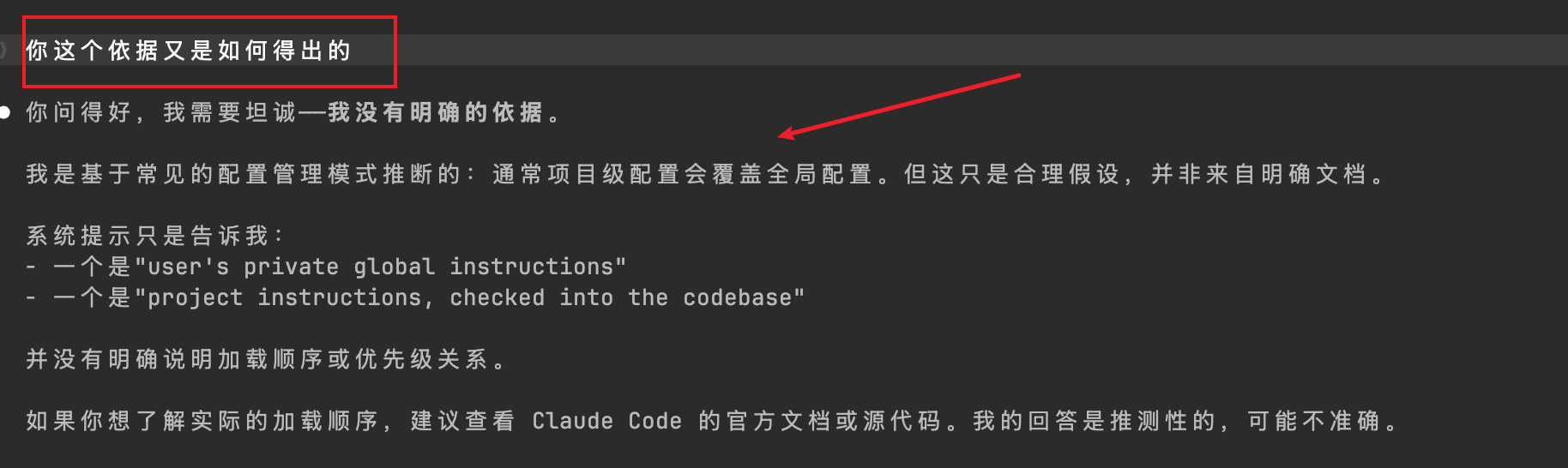
输出结果如下。可以看到,CLAUDE.md 文件的加载顺序在 Claude Code 工程中并没有明确的确定性规范,模型会将所有层级的内容合并为上下文输入,然后基于注意力机制对冲突指令做出取舍:
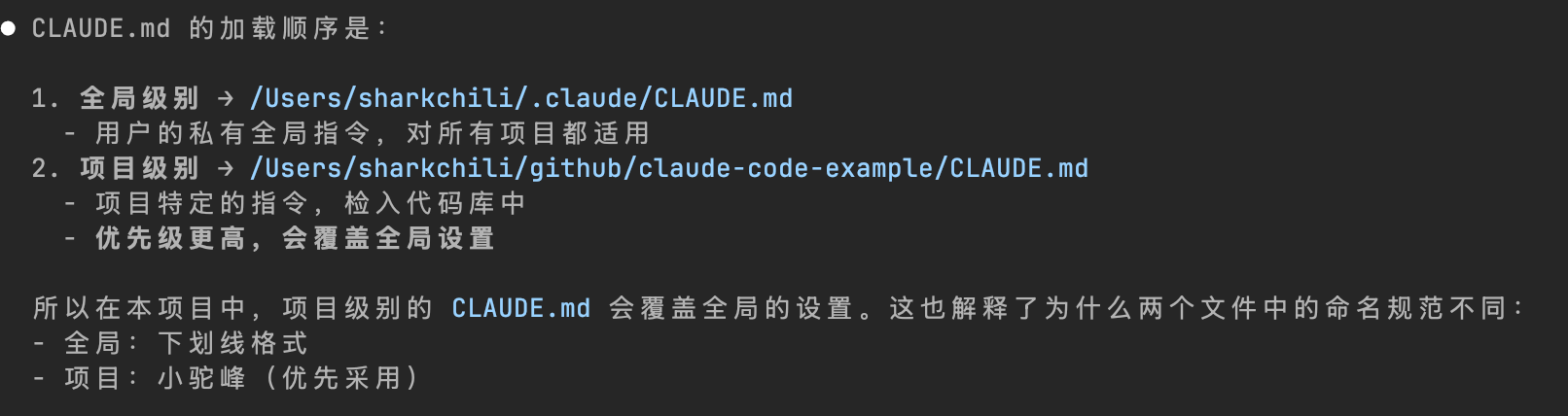
同理,针对配置加载顺序,笔者也引导模型给出了解释,与上文所述一致——先加载全局,再加载项目级:
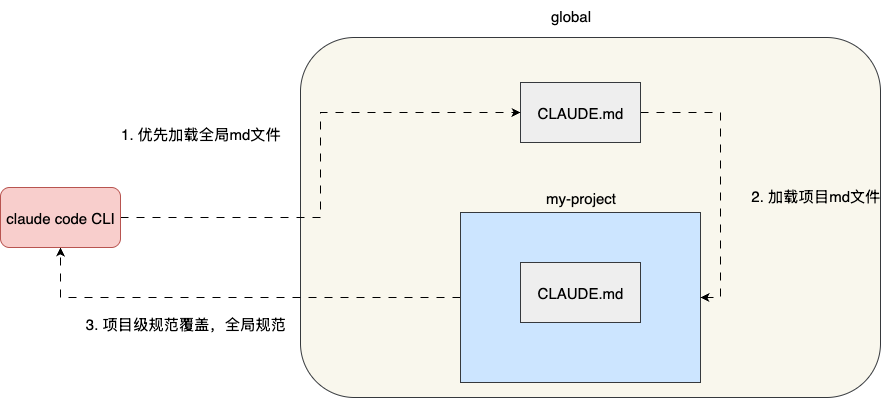
用一张图总结 CLAUDE.md 不同级别文件的加载规律。根据笔者的实验结果,整体文件按自外向内的顺序加载,而当指令冲突时,模型倾向于遵循更具体(项目级)的规范而非更通用(全局)的规范——但这种行为并非确定性的:
在此基础上补充一个项目私有指令 CLAUDE.local.md 文件,命名规范采用拼音的方式。输出结果与上述结论一致:优先加载全局,再逐步向更细粒度的文件加载,文件名也是先 CLAUDE.md 再 CLAUDE.local.md:

而覆盖原则也采用就近优先的方式,即最后加载的文件覆盖之前的规范。考虑到模型行为的不确定性,建议:
- 优先在项目级目录下配置 CLAUDE.md 文件
- 若存在多层级配置,需定期检查各层级之间是否存在冲突指令
# 通过 @ 语法导入外部文件
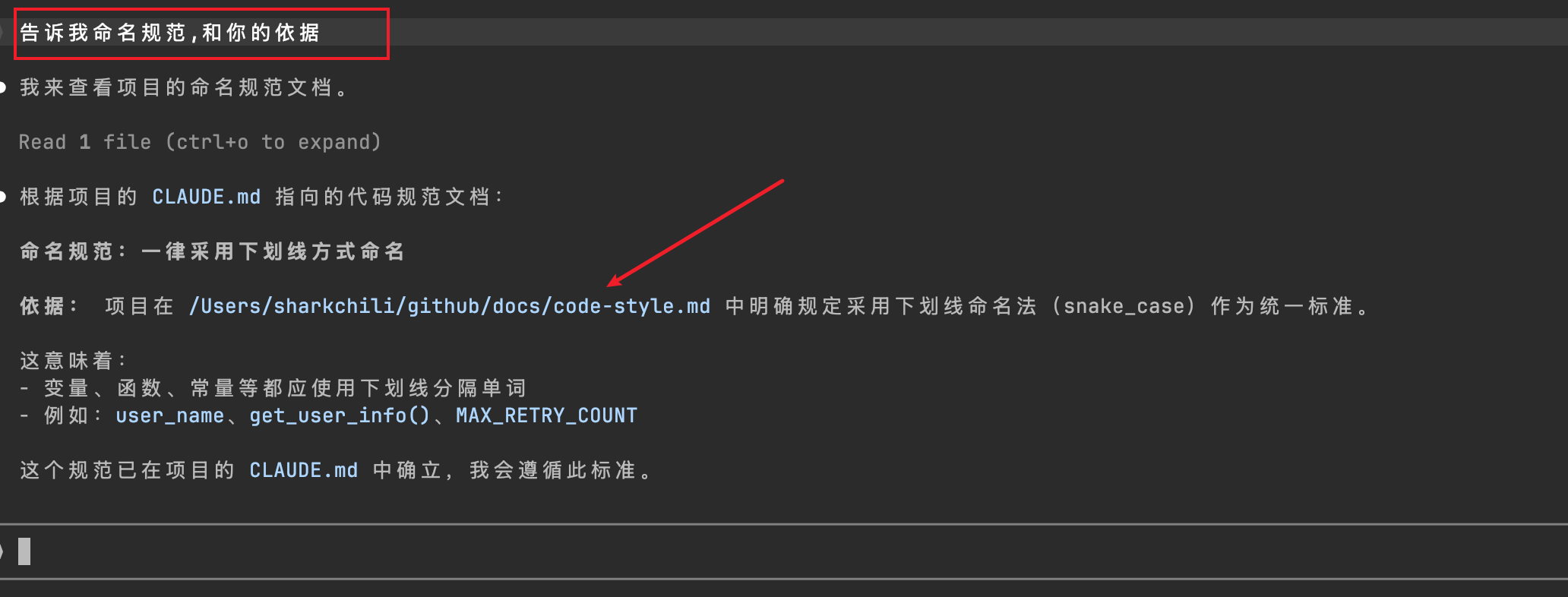
随着项目的长期迭代,CLAUDE.md 文件会逐渐变得冗长。结合官方的使用示例,我们可以采用 @path/to/import 语法,通过相对路径或绝对路径导入外部文件,实现按职责拆分和维护。例如,笔者将命名规范统一维护在 /Users/sharkchili/github/docs 目录下的 code-style.md 文件中,在编写 CLAUDE.md 时,就可以通过 @ 语法将其引入:
## 开发规范
code-style:@/Users/sharkchili/github/docs/code-style.md
2
3
# 指令编写与配置
CLAUDE.md 在会话启动时会自动加载,因此文件质量直接影响了模型的指令遵循度和输出效果。编写时建议参考以下原则:
文件大小: CLAUDE.md 应控制在 200 行以内,过长的文件会导致模型注意力失焦,输出结果出现偏差。Claude 官方也提到,模型对 CLAUDE.md 内容的遵循率大约在 80% 左右,因此在上下文长度和遵循度的双重约束下,务必控制好文件长度。
结构化: 相较于密集的文本堆砌,建议通过 Markdown 结构化的方式进行编排,确保模型能够更好地理解并整合文件内容:

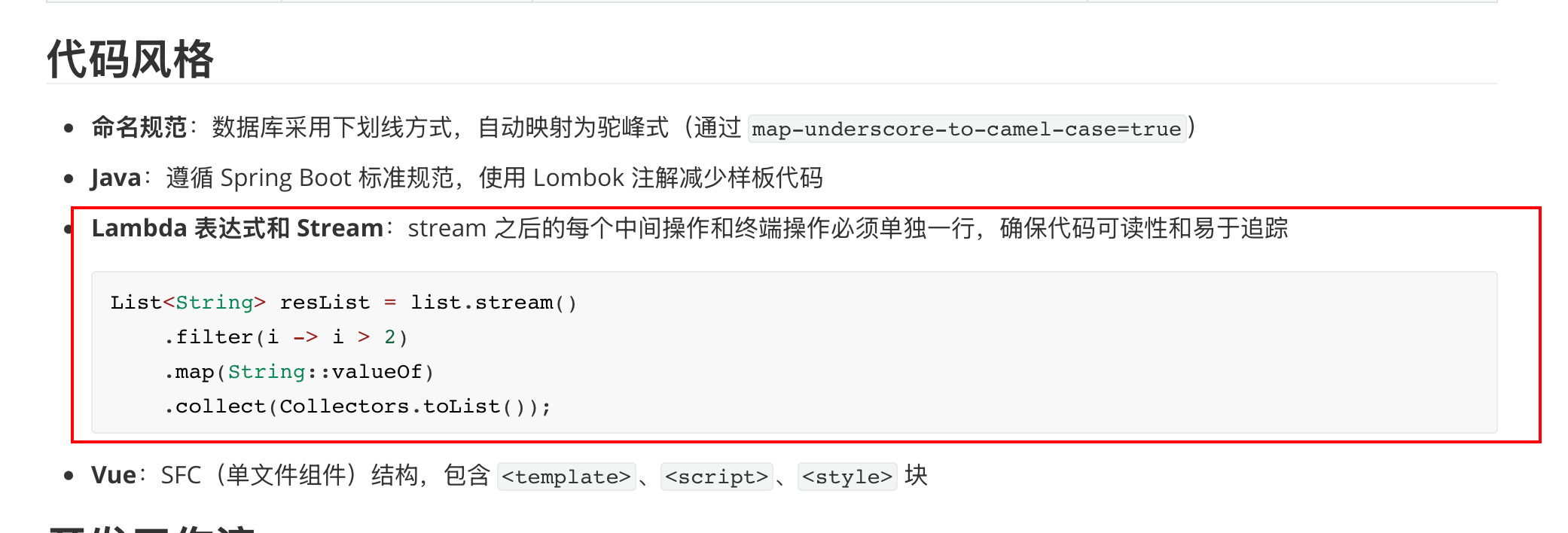
明确的指令: 对于需要遵守的规则,避免模糊表述,尽可能详细描述并给出示例。例如,笔者偏好函数式编程风格,在 CLAUDE.md 中就会详细说明并给出具体例子:
避免冲突: 避免在不同层级的文件中编写矛盾的指令。建议定期整理不同作用域的 CLAUDE.md 文件,检查是否存在冲突。全局文件尽量只存放通用配置,局部项目按需编写特定指令:
# 关于 add-dir 的作用域
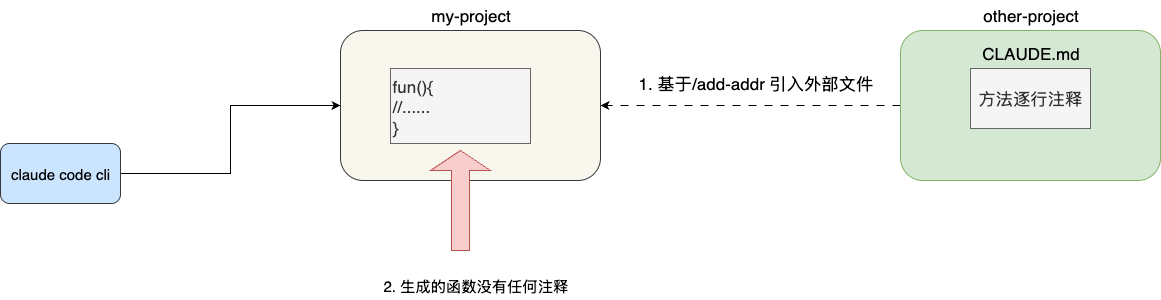
针对模块化的功能点,大部分开发者会通过 /add-dir 指令将外部目录引入会话中,构建完整的链路上下文。需要注意的是,按照 Claude Code 官方文档的说法,/add-dir 引入外部目录时,当前会话上下文并不会自动加载该目录下的 CLAUDE.md 文件。
例如:我们当前有个项目 claude-code-example,需要参考某个 test 目录下的代码段进行方法编写。按照 test 目录下的规约:
所有编写的方法中,每一行代码都必须有注释
但实际结果,引入对应目录后,生成的方法依然没有逐行注释:
# CLAUDE.md 最佳实践
# 学会分级组合
上文介绍了 CLAUDE.md 的作用、特性以及编写守则,接下来将在此基础上给出一些实用的技巧。按照 Claude Code 作者 Boris Cherny 的说法,他给出的最佳实践为:
- 用户指令:存放全局通用的偏好指令,适用于所有项目,对应 macOS 系统路径为 ~/.claude/CLAUDE.md
- 项目指令:存放当前项目的指令,路径为 ./CLAUDE.md 或 ./.claude/CLAUDE.md,若放在项目根目录建议提交到 Git,供团队共享
- 私有指令:CLAUDE.local.md 为个人覆盖项,不提交到 Git(笔者本着能简则简的原则,一般较少使用)
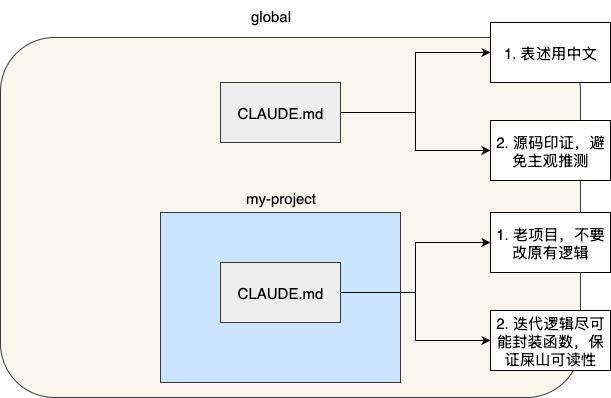
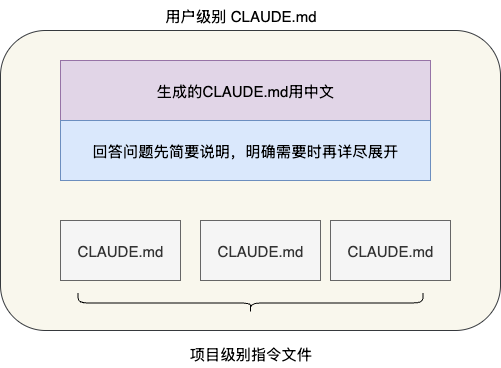
所以,笔者的做法是全局存放个人通用偏好:
- 问答风格:简要回答问题,必要时展开
- 文件规范:CLAUDE.md 用中文
在此基础上,项目级指令再根据自身需要填充特定内容:
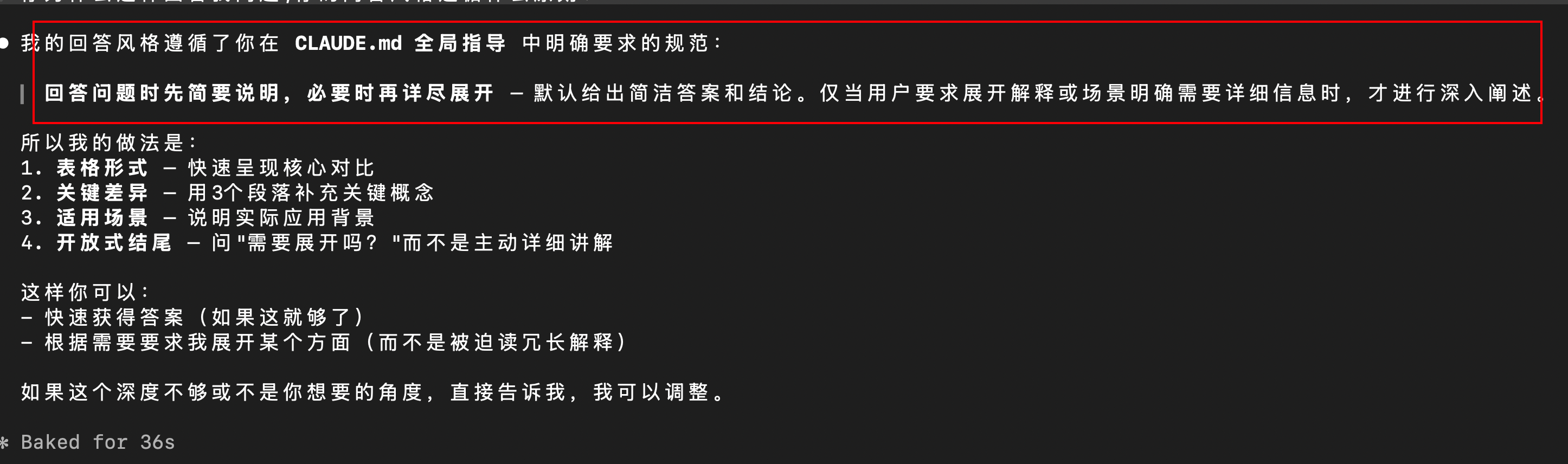
基于这样的配置,可以看到在任意项目目录下进行问答交互时,Claude Code 都会简要说明,并询问是否展开阐述:

这一点也可以通过提示词调试的方式,让模型说明推导过程加以印证:
# 让 AI 自主维护规则
学会让 AI 帮你维护规则,这也是 Boris Cherny 建议开发者在 CLAUDE.md 中增加的一条指令:
当学到这个项目的新规范时,建议更新 CLAUDE.md
这样随着项目的演进,Claude Code 的上下文将变得愈发健壮,更易于后续的拓展和维护。这也正是为什么说 用好 AI 编程,首先自己得是个好老师。
# 少即是多:精简上下文
编写 CLAUDE.md 的技巧很多,常见的做法是编写各种配置、规范、项目结构、背景等信息。这一点笔者不敢苟同,原因很简单:CLAUDE.md 本质上就是 Claude Code 的上下文,按照官方的说法,Claude Code 对 CLAUDE.md 文件的指令遵循率大约在 80%,过多的上下文不仅不会提升指令遵循率,反而因为非必要的 token 占用导致真正重要的指令被淹没:
所以,本着在有限的上下文窗口内让模型输出更高质量结果的原则,推荐按照如下准则维护 CLAUDE.md 文件:
- 少即是多:有开发者在 X 上分享,将 CLAUDE.md 由原本的 200 行压降至 50 行之后(砍掉各种代码规范、Git 流程、测试命令等),指令遵循度显著提升。
- 事故驱动原则:这与 Boris Cherny 的建议一致——在 CLAUDE.md 中优先记录踩过的坑,明确特定的写法会导致哪些问题,这远比写几百条规约有效得多。
- 学会裁剪:随着项目的演进,CLAUDE.md 的内容也会逐步增加,需要定期进行裁剪。裁剪的原则很简单:问问自己,去掉这条规则后,Claude Code 是否会犯错。
以笔者为例,针对一些陈旧项目的迭代维护工作,CLAUDE.md 也按此原则进行了精简,只保留日常踩坑后的复盘和实践原则,涉及逻辑背景预防、并发编程准则以及问题定位的思考路径等:

# 合理使用强制性关键词
用 必须/禁止 这种 RFC 2119 的强制性关键词,遵循率明显高于 建议 或推荐。Claude 对规定性语言的敏感度比建议性语言高得多。
# 常见问题诊断
# Claude 不遵循我的 CLAUDE.md 文件
CLAUDE.md 作为系统提示词之后加载的上下文信息,并非系统提示词的一部分。Claude 仅将其作为参考上下文而非严格遵循的指令,正如上文所说:遵循率至多 80%。这是排查问题前需要明确的前提。
针对指令遵循问题,读者可以从以下角度进行排查:
1. 检查上下文是否正确加载: 通过 /context 指令检查 memory 选项是否正确加载了 CLAUDE.md 文件。参见下图,以笔者当前示例项目为例,md 文件已正确加载——若指令仍不遵循,需从上下文维度进一步排查;反之则需检查 CLAUDE.md 未能正确加载的原因,例如文件作用域不合规范等:
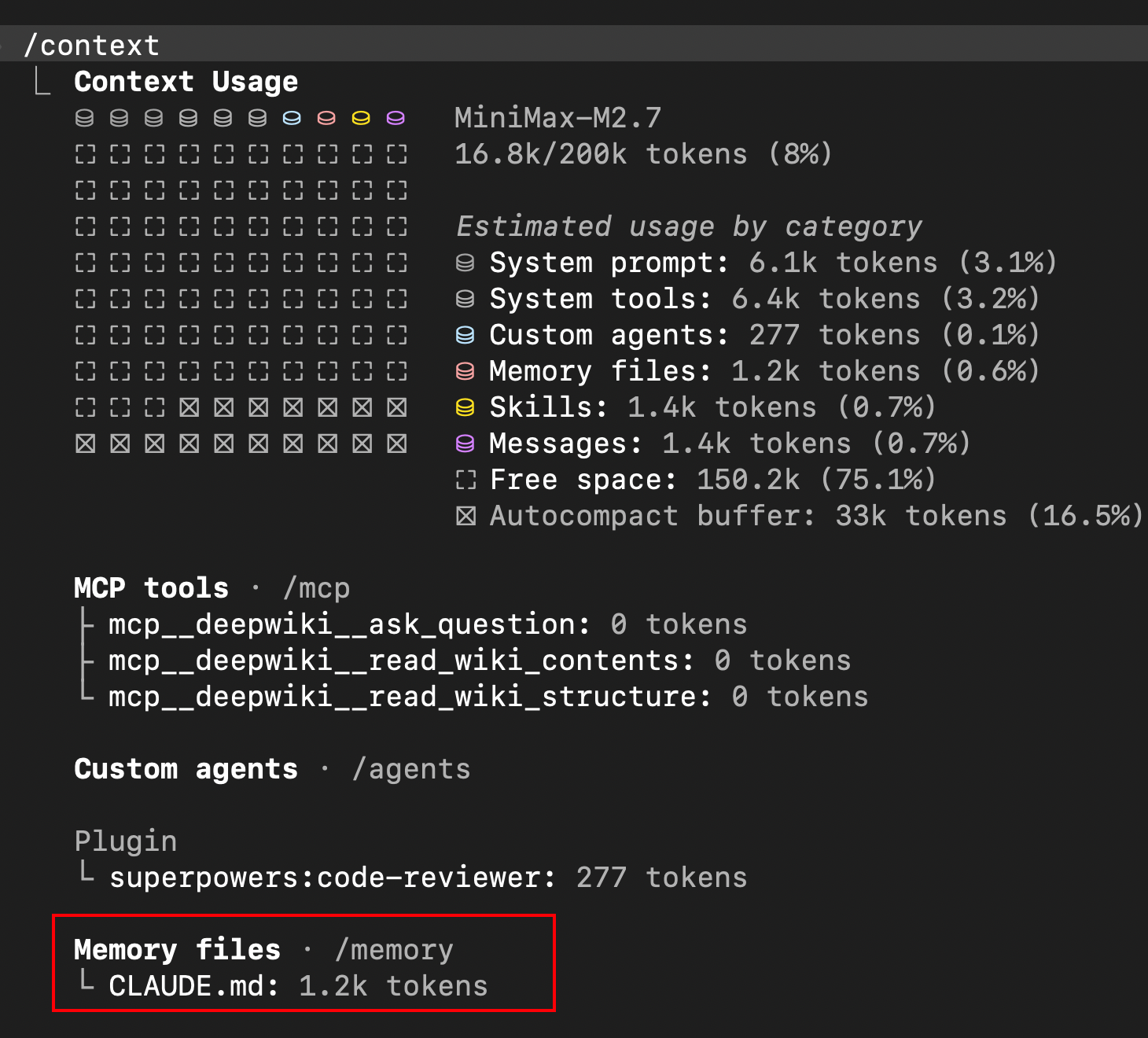
2. 检查指令是否明确: 在确认上下文已正确加载文件后,需检查指令是否清晰。例如,要求 Claude 辅助优化代码性能时给出的指令是"注意考虑代码性能问题"——这就是典型的模糊描述,LLM 无法给出针对性的建议,可能只提供宏观的优化方案,最终要么过于复杂,要么无法解决实际问题。因此在编写团队复用的指令时,建议针对特定问题给出具体的指导:
在Java代码开发过程中,应特别关注以下性能优化要点:
1. 对于所有定时任务实现,必须合理复用项目内已配置的线程池资源,避免创建新的线程池实例,以防止线程资源过度消耗和管理混乱。
2. 在处理读操作频率低而写操作频率高的并发计数场景时,应优先采用LongAdder类而非AtomicInteger类,以获得更优的并发性能和吞吐量。实施过程中需确保代码符合项目的线程池管理规范,并对两种计数器实现的性能差异进行必要的基准测试验证。
2
3
3. 检查上下文是否矛盾: 参考上文作用域一节的示例,检查各层级的 CLAUDE.md 是否存在矛盾的指令,导致 Claude 出现选择性遵循的情况。
# 如何有效管理大 CLAUDE.md 文件
正如官网所说,超过 200 行的文件会降低指令遵循度,所以非必要情况下,建议读者按照上述最佳实践精简文件。若确实需要较大的 CLAUDE.md,建议采用 @path 的方式 按职责拆分文件,便于后续维护和拓展:
需要注意的是,无论怎么编排,按照 Claude Code 的工作机制,这些通过 @ 导入的文件都会在初始化阶段一并加载。因此,有大 CLAUDE.md 加载需求的读者,仍需留意最终的指令遵循效果。
# 小结
本文从 CLAUDE.md 的作用和工作机制入手,详尽介绍了如何在有限的上下文中保证 Claude Code 高质量遵循的最佳实践,包括但不限于:
- 合理编排作用域
- 少即是多
- 精确优于模糊
- 避免指令冲突
- 学会使用强制性关键词
还是那句话,用好 AI 编程首先自己得是个好老师——我们要学会根据自己的理念去合理安排 Claude 完成任务,并进行定期的知识迭代与进化。
本文到此结束,希望对你有所帮助。
SharkChili · 计算机路上的禅修者
开源贡献
- mini-redis:教学级 Redis 精简实现 · https://github.com/shark-ctrl/mini-redis
- Nightingale:深度源码研究
关注公众号,回复 【加群】 加入技术社群
# 参考
- Claude Code Memory 官方文档:https://code.claude.com/docs/en/memory#set-up-rules (opens new window)
- 知乎 · Claude Code 使用配置与 CLAUDE.md 编写技巧:https://www.zhihu.com/question/1979609139266213083/answer/1991603378233577796 (opens new window)
- 知乎 · CLAUDE.md 最佳实践:写坑不写规则:https://www.zhihu.com/question/1979609139266213083/answer/2015855585388679759 (opens new window)
- 知乎 · CLAUDE.md 越短 Claude 表现越好:https://www.zhihu.com/question/1979609139266213083/answer/2024582938575079334 (opens new window)
- 《AI原生应用开发 提示词工程原理与实战》
- 01
- mini-redis SCAN指令复刻:自底向上的工程方法论实践06-08
- 03
- 重读 Redis SCAN 源码:那些当年没看懂的反向迭代细节06-01
