 Claude Code 规则管理:Rules 拆分编排与迭代实践(文末送书)
Claude Code 规则管理:Rules 拆分编排与迭代实践(文末送书)
# 写在文章开头
我其实不是很喜欢古法编程这一说法,AI编程本质是一种提效的工具,善于利用AI的人,会结合自己的理念和决策引导强大的LLM快速推导出合适的解决方案,并利用自身经验推进验收。编码的行为只是设计显性化的一个环节,一味地去强调古法、摈弃所谓古法编程的人,我只有苦笑。
毕竟,我自认为优秀的方案设计和基本功,都是来自大量的编程训练,即:
- 主动思考理解优秀框架的设计
- 动手实践感知落地细节和技巧
- 调试验收构建学习闭环
- 复盘梳理巩固认知
- 社区分享探寻不足之处
希望我的一些个人的理解和认知,对你有所启发,最近笔者也准备了一个免费赠送Claude Code实战书籍的活动,感兴趣的读者可以移步如下链接到评论区踊跃参与:
本本爆款的咖哥,带着首本Claude Code实战书来了! (opens new window)
回到AI编程,这篇文章要讲的还是AI编程的核心——上下文。基于Claude Code亦或者各种AI IDE进行编程时,无论是任何skill亦或者框架、插件,本质上都是在调整上下文,引导LLM注意力能够聚焦关键信息区域,提高相关内容激活的概率,进而提升推理的准确性。
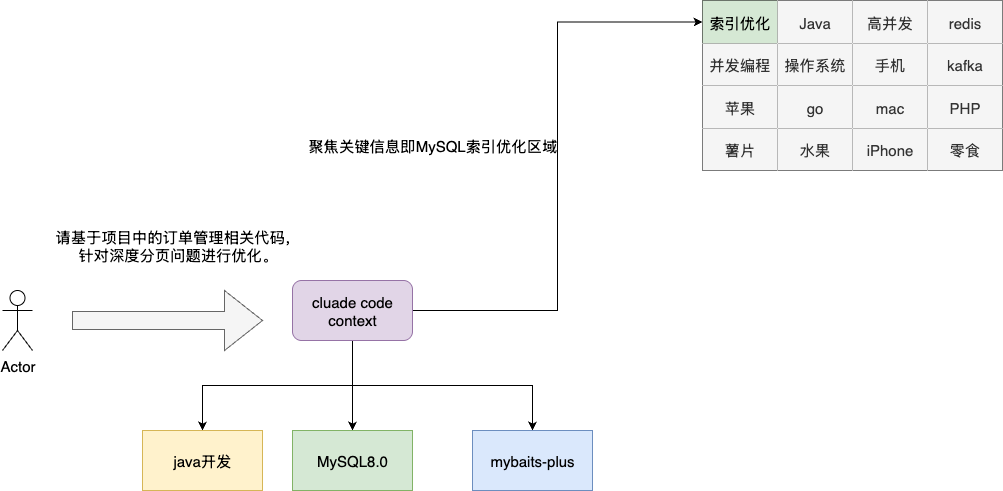
之前的文章,笔者花费了大量篇幅介绍如何通过CLAUDE.md构建任务的上下文引导claude高效的编码工作。但问题也随之而来,按照claude官方的说法,CLAUDE.md尽可能控制在200行以内,过长的上下文会带来过多的噪声,导致模型注意力被稀释,造成指令遵循下降:
target under 200 lines per CLAUDE.md file. Longer files consume more context and reduce adherence.
所以,对于长期迭代的工程项目,我们推荐采用管控粒度更细致的rules作为CLAUDE.md的补充进行管理。这篇文章将针对rules的特性和使用技巧和实践等多个角度,对规则的理念和使用进行详细的介绍,确保读者能够精准把控自己的AI协作编程时的上下文窗口。
考虑到受众面,本文将以使用率最高的Claude Code作为演示工具。当然,这并不意味着这篇文章对于使用其他AI编程工具的读者不受用,本质上,规则可以理解为更精细粒度的上下文增强,无论是Cursor、qoder还是trae,整体的理念和技巧是通用的。
SharkChili · 计算机路上的禅修者
开源贡献
- mini-redis:教学级 Redis 精简实现 · https://github.com/shark-ctrl/mini-redis
- Nightingale:深度源码研究
关注公众号,回复 【加群】 加入技术社群
# 详解AI coding rules
# 为什么需要rules?claude.md的局限性是什么?
在之前的文章:Claude Code 记忆管理:CLAUDE.md 最佳实践 (opens new window) 一文中,笔者已经详细说明了CLAUDE.md对于上下文管理局限性:
- 启动时会话时直接加载,长期处于会话上下文中
- 建议控制在200行以内,过长的文件会消耗更多上下文并降低指令遵循度,更适用于相对普适的编码标准、工作流程和项目架构
- 只能通过作用域管理上下文,无法针对文件夹或文件级别的上下文粒度管理和加载
- 无法按照职责对项目工程指令进行编排,例如将规范按照开发规范、测试、部署等多职责分工角度采用独立文件进行管理和按需披露
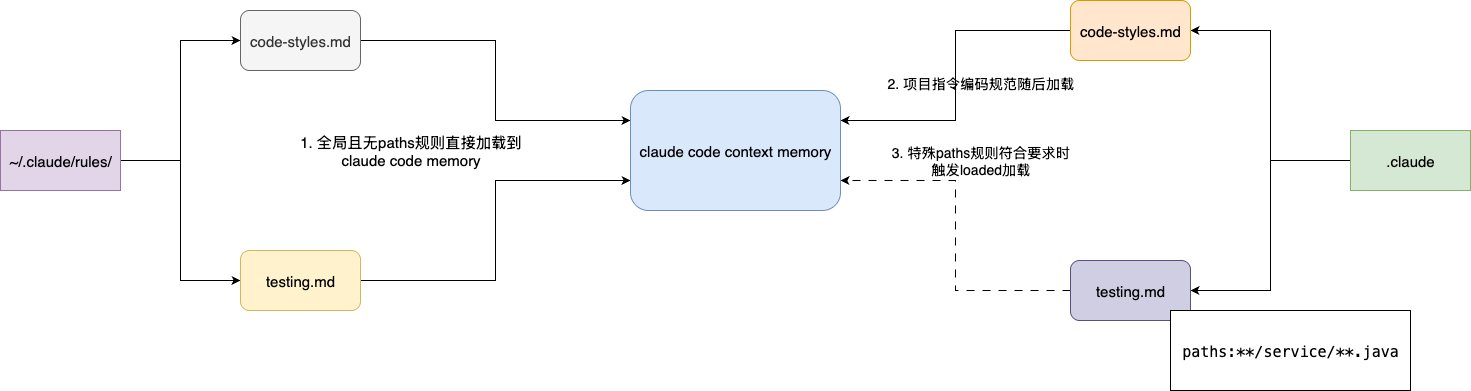
所以,对于需要长期维护的工程代码,我们建议采用更加灵活的rules来维护与AI协作的上下文。结合claude官方的说法(其他编程IDE原理也类似),rules支持通过paths字段指定特定文件的作用域,只有在claude处理匹配文件时才会加载对应的rules到上下文中。需要注意的是,未指定paths的rules会在启动时与CLAUDE.md一同加载,由此做到在减少噪音干扰的同时,节省上下文空间,以尽可能保证LLM的指令遵循度。
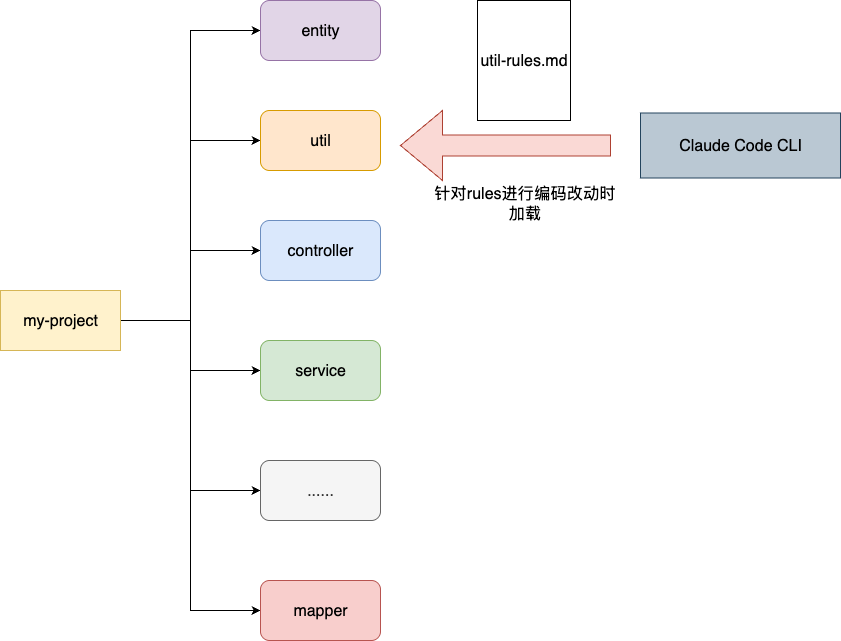
# 如何创建rules
按照提示词工程最佳实践,编写规范文件建议采用markdown语法,通过层次化划分,确保LLM能够结构化有序处理并理解,提升推理的准确性。
按照文件级的作用维度,claude 规则编写的作用域可分为全局作用域和项目作用域,全局作用域一般存储通用性规则或者用户偏好,以MacOS系统为例:
- 用户级规则:存放于
~/.claude/rules/目录 - 项目级规则:存放于项目根目录的
.claude/rules/文件夹下
不难看出,指令作用域规范和CLAUDE.md基本一致,需要注意的是,按照官方的说法,用户级规则会优先加载,所以按照覆盖性原则或者就近原则的角度理解,项目级规则优先级更高:
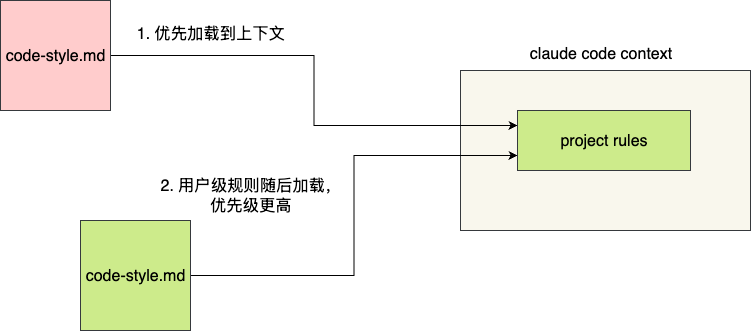
针对这个问题,笔者也以GLM 5.1 测试模型,然后执行如下步骤:
- 全局用户级目录设置规则为英文的指令
- 项目rules目录设置规则为中文的规范指令
完成规则声明后,启动上下文,明确两个测试规则都成功加载到项目文件夹下,此时我们就可以用提示词功能调试的技巧询问其修改建议,查看是否是以用户指令(所有注释为中文)为准:
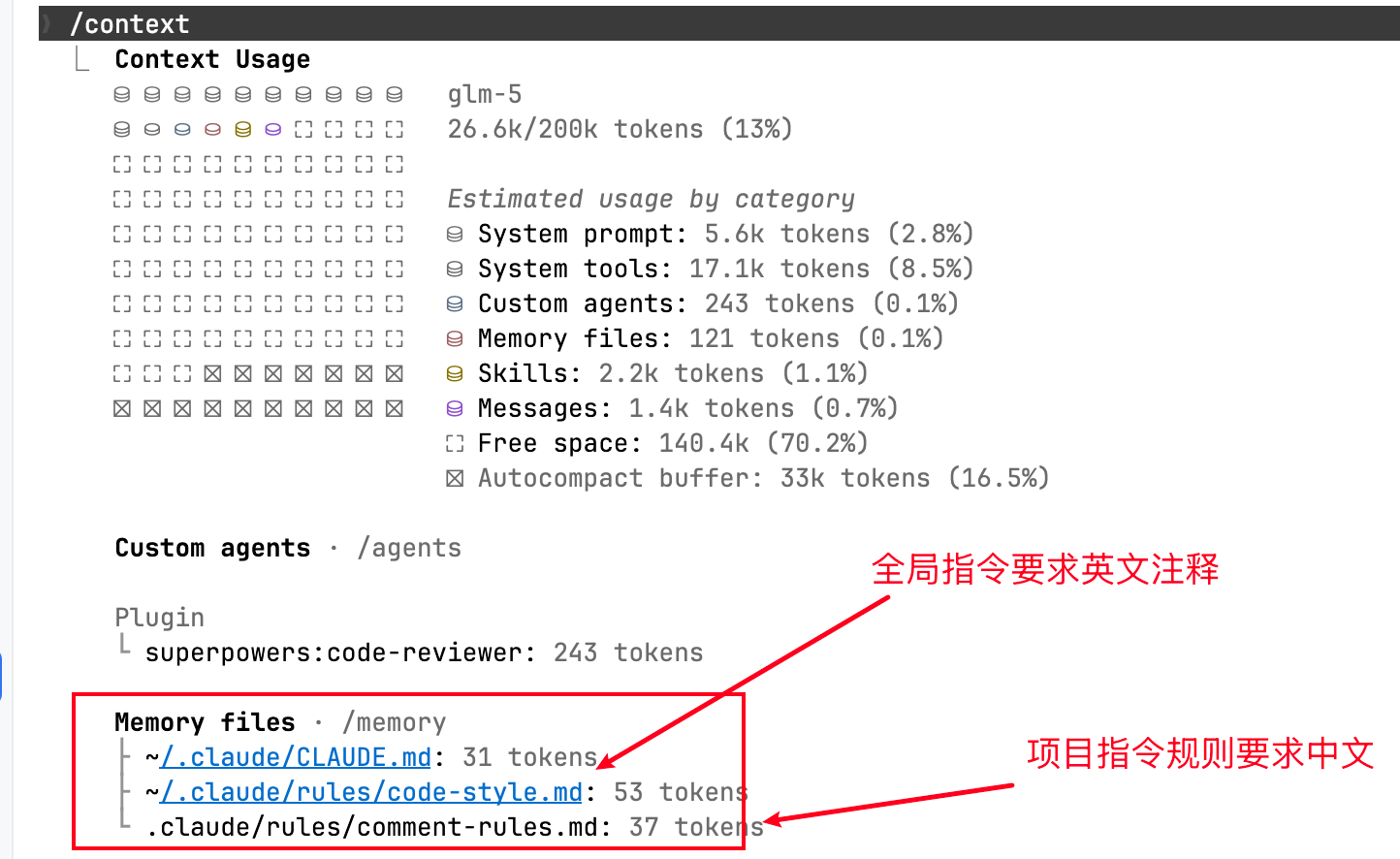
最终输出结果如下,笔者指定的任意代码,给出的修改建议是采用中文。这点也和官方的表述一致:

# rules拆分与编排原则
# 规则拆分的本质
一个成熟且经过长期迭代的系统,在接入AI工具协作编程时,是需要指定各种约束和配置,包括但不限于:
- 编码风格
- 工程规范
- 业务规则
- 部署指南
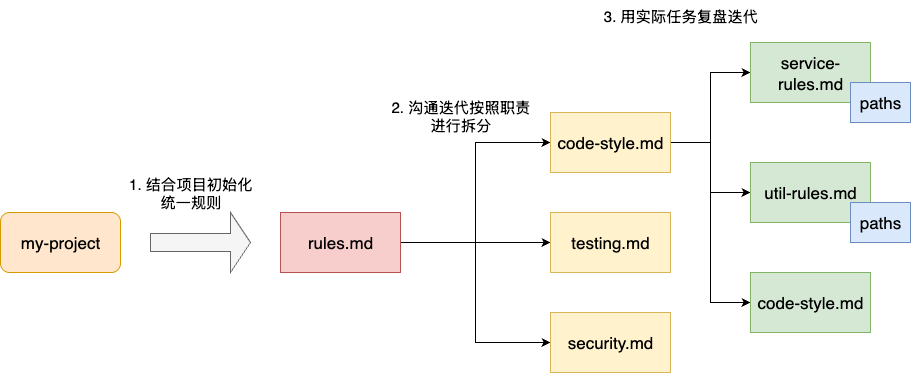
按照现有trae技术社区给出的最佳实践,rules拆分原则可先按照职责执行拆分、再通过范围进行界定。按照笔者的理解,这种做法是先进行有序分类给LLM上下文进行降噪,同时提升规则可维护性。再针对规则的工作范围划定作用域,进行更细一步的拆分,降低上下文的占用的同时,完成对LLM的更进一步的降噪:
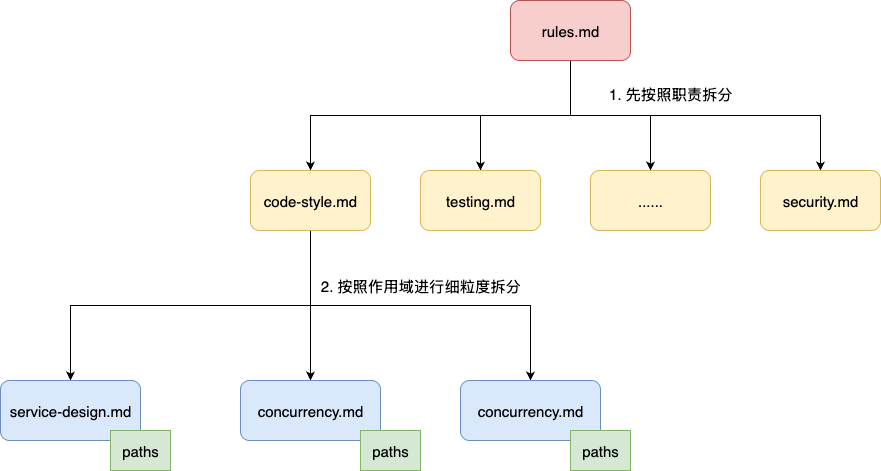
# 职责拆分规则
我们先来说说拆分的第一个考量标准——职责。按照职责拆分维护不同维度的md文件,可以避免非必要的噪声干扰,也有利于后续我们针对特定规则的迭代。
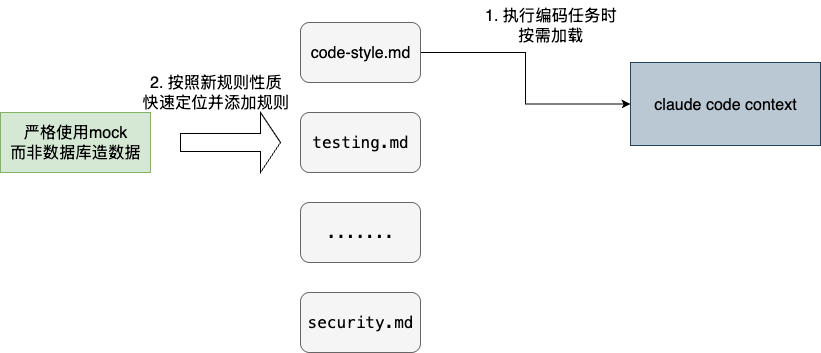
例如:将编码规范和测试流程分而治之,使用不同的md文件进行独立维度,这就确保后续我们在指定开发流程时,可以准确将适用的语料按需注入,避免编码审查时,突然给出测试规范。同时,也保证后续新增规则时,我们可以根据规则的性质将其添加到测试的规则列表中:
# 范围拆分
有了明确维度的职责划分之后,我们再来更精细粒度的作用域划分。笔者一直强调规则把控粒度可针对文件或者文件夹级别。当前阶段就是针对职责划分后的文件进行更细粒度的拆分,确保统一职责不同工作划分的规则能够按需加载。
例如:编码规范中针对service目录下的编码标准,我们可通过paths指定其作用域为src/main/java/**/service/**/*.java,将code-style.md作为通用的编码规范统一维护。
# 适时更新规则
上述的拆分辅助我们构建一个直观且便捷的规则维护框架。考虑到项目的迭代同步也在一定程度影响项目规范,为避免规则的腐化影响AI编码的准确性,我们需要适时的进行规则的维护与更新,对应的更新标准可从新增规则、修改规则以及删除规则三个角度来探讨:
- 新增规则:针对新增规则,首先明确规则的职责并确定对应文件,同时检查是否与存量规则列表存在矛盾冲突(可借助AI辅助检查)
- 修改规则:规则的修改需严格从项目标准和作用域变更角度来考量,即只有发生项目开发规范亦或者作用域范围可进一步进行调整时再针对性修改
- 删除规则:删除规则是比较重的操作,笔者认为只有在规则失效或者新增规则时发现冲突时,才可进行的操作
关于规则的迭代,一个有效的技巧是,学会利用与AI交互的上下文,让其主动探索规则维护的不足之处,针对实际应用场景对规则进行有效迭代。
对应笔者也给出,规则调整的提示词:
结合我们本轮开发任务的交互历史和当前项目需求,请全面评估现有的开发规范和编码规则,识别是否存在需要新增、修改或删除的规则项。请从以下维度进行分析:
1)现有规则是否覆盖了当前项目的技术栈、业务和架构模式;
2)规则是否存在过时、冗余或冲突的内容;
3)是否需要补充新的最佳实践或约束条件;
4)规则的可执行性和维护性如何改进。
基于你的分析,提出具体的规则更新建议。
2
3
4
5
6
7
所以,结合上述的说法,对于规则的管理原则,
- 按照职责拆分建立基调
- 按照作用域限定界定工作范围
- 适时迭代更新避免规则腐化
最后补充一点,如前文所述,项目级规则的优先级高于全局用户级规则:
User-level rules are loaded before project rules, giving project rules higher priority.
# 初始化构建——基于后端项目演示rules的初始化
# 项目说明
为了让读者更直观的了解规则的编写和维护技巧,笔者准备了一个典型的消息发送中心项目作为演示案例,演示一下如何针对一个既有的成熟的企业级项目进行规则初始化和复盘迭代升级,以提升AI的处理增量任务的指令遵循度。
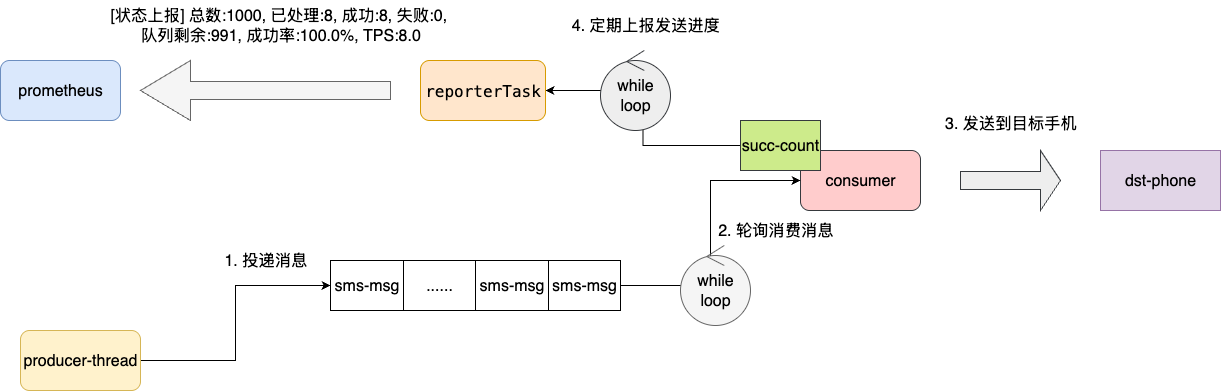
该案例是一个经典的消息发送中心的企业级项目,整体工作流程如下:
- 消费者线程读取数据库bin.log或定时轮询的方式获取短消息
- 消费者线程轮询消息队列消费消息
- 针对发送结果维护一个全局列表
- 监控线程定时获取发送指标同步到监控面板
# 初始化规则
此类项目经过长期迭代和维护,已处于稳定运行阶段,日常只需进行业务拓展迭代和维护工作即可。所以指令规范优先以当前项目风格为主。同时,考虑到项目的体量,我们无法一次性完成规则的编排和粒度把控,笔者建议先全局初始化一份md文件并按照分段的方式划分规则,让这份规则跟随后续实际的迭代任务进行复盘升级,不断优化,使规则做到减少噪音的同时,保证较高的指令遵循度。
所以,在针对既有的工程项目代码,笔者建议通过以下提示词,让AI充分阅读上下文生成一份全局通用项目级指令:
请仔细阅读项目的所有重要目录和文件结构,基于现有代码分析并总结出一套合理的项目开发规范。具体包括:
1. 项目基本目录结构规范 - 明确每个目录的职责和应该存放什么类型的代码文件
2. 功能模块组织规范 - 指定不同功能类型的代码应该放在哪个特定目录下
3. 接口开发规范 - 详细说明开发新接口的标准流程、代码组织方式和最佳实践
4. 文件命名规范 - 规定不同类型文件的命名规则和存放位置
5. 代码风格规范 - 包括注释要求、日志使用、异常处理等编码标准
请基于当前项目的实际结构和代码特点,提炼出项目级别的rules。
2
3
4
5
6
7
8
9
随后,我们就会得到一份统一的以md格式结构化的规则文档:

这时我们就可以结合个人经验阅读这些规则进行微调。以笔者当前初始化的项目规则为例,由于这份规范是基于项目代码风格推理得出的,我们需要结合个人经验进行校准,需要进行如下调整:
- service 业务服务(直接实现类,不抽接口):这一点是因为既有的业务迭代不涉及相同行为不同业务场景的拓展,例如:SmsSendService仅涉及A运行商的短信发送,所以send方法不涉及接口抽象而是直接实现类
- 工具库:由于项目上下文的注释或推理能力的局限性,这三点本质都是围绕的尽可能使用成熟的工具库hutool,而非三条不同的规则。
# 迭代规则
所以为了保证后续开发工作的指令遵循度,以及规则的可读性和可维护性,我们需要对规则进行必要的划分和修剪,首先我们先修复上述问题:
请调整一下规则:
1. Service业务服务设计原则:对于当前业务场景下不需要扩展的情况,采用直接实现类而不抽取接口的方式。例如SmsSendService仅负责A运营商的短信发送功能,在没有其他运营商接入需求的情况下,send方法直接在实现类中完成,无需进行接口抽象。这种设计适用于业务边界明确且短期内不会扩展的场景。
2. 工具库使用规范:由于项目上下文注释或推理能力的局限性,应优先使用成熟的Hutool工具库来替代JDK原生API。这包括但不限于线程休眠(ThreadUtil.sleep替代Thread.sleep)、随机数生成(RandomUtil)等操作,确保代码的一致性和可维护性。此规范旨在统一技术栈,减少重复造轮子,提高开发效率。
2
3
4
调整后的规则如下:

# 职责划分
明确整体性规则无误之后,为确保后续能够快速进行针对性的规则进行迭代修改,笔者建议让AI协助,将既有效的规则进行职责拆分,对应提词如下所示:
@.claude/rules/project-rules.md 请根据项目开发规范中定义的不同职责维度,将 project-rules.md 文件中的规则进行分类整理和拆分。按照以下职责类别重新组织内容:
1. 目录结构规范 - 关于包结构、各目录职责分工的规则
2. Service 设计规范 - 关于服务层实现、接口抽象原则的规则
3. 命名规范 - 关于变量、方法、类、线程名等命名的规则
4. 工具库使用规范 - 关于 Hutool 等工具库使用的规则
5. 日志规范 - 关于日志级别、格式、输出方式的规则
6. 注释规范 - 关于 Javadoc、代码注释的规则
7. 并发编程规范 - 关于线程池、并发集合、原子类使用的规则
请将现有的规则内容按照上述职责维度进行归类,并为每个类别提供清晰的说明和示例。
2
3
4
5
6
7
8
9
10
11
最终拆分后的规则结构如下所示,此时,我们就得到一个标准的、结构化且易于针对性维护拓展的项目级规则指令。可以看到,AI非常准确的从注释、并发编程规范、目录结构、日志等多个角度对开发规范进行拆分。后续,我们就可以根据自身的迭代需求进行迭代、复盘和升级:

# 迭代与沉淀——基于新需求完成规则演进
# 迭代技巧说明
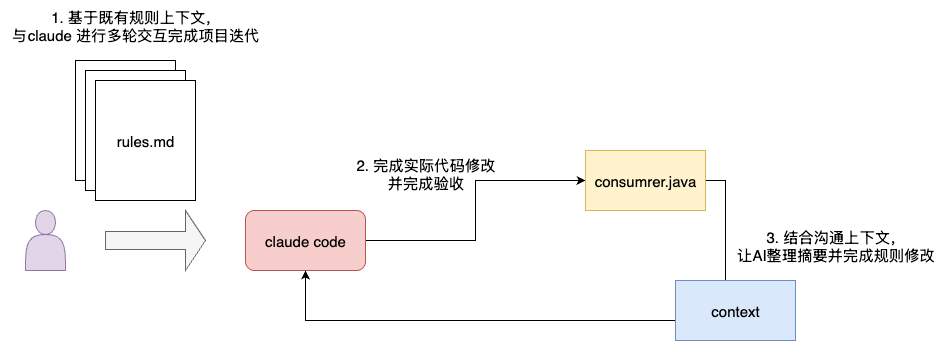
正如上文所说,规则的应用应结合实际场景进行迭代和复盘升级,所以,为了获得更精准的指令遵循度和更符合业务需求的输出质量,笔者建议rules的迭代工作应跟随一次完整的需求或者工程迭代升级,并在验收之后和AI进行沟通复盘,完成既定的规则调整:
# 走查与规则沉淀
为了演示规则的迭代和升级步骤,笔者结合simplify指令进行代码走查:
/simplify 查看当前工程代码是否有需要改进的地方
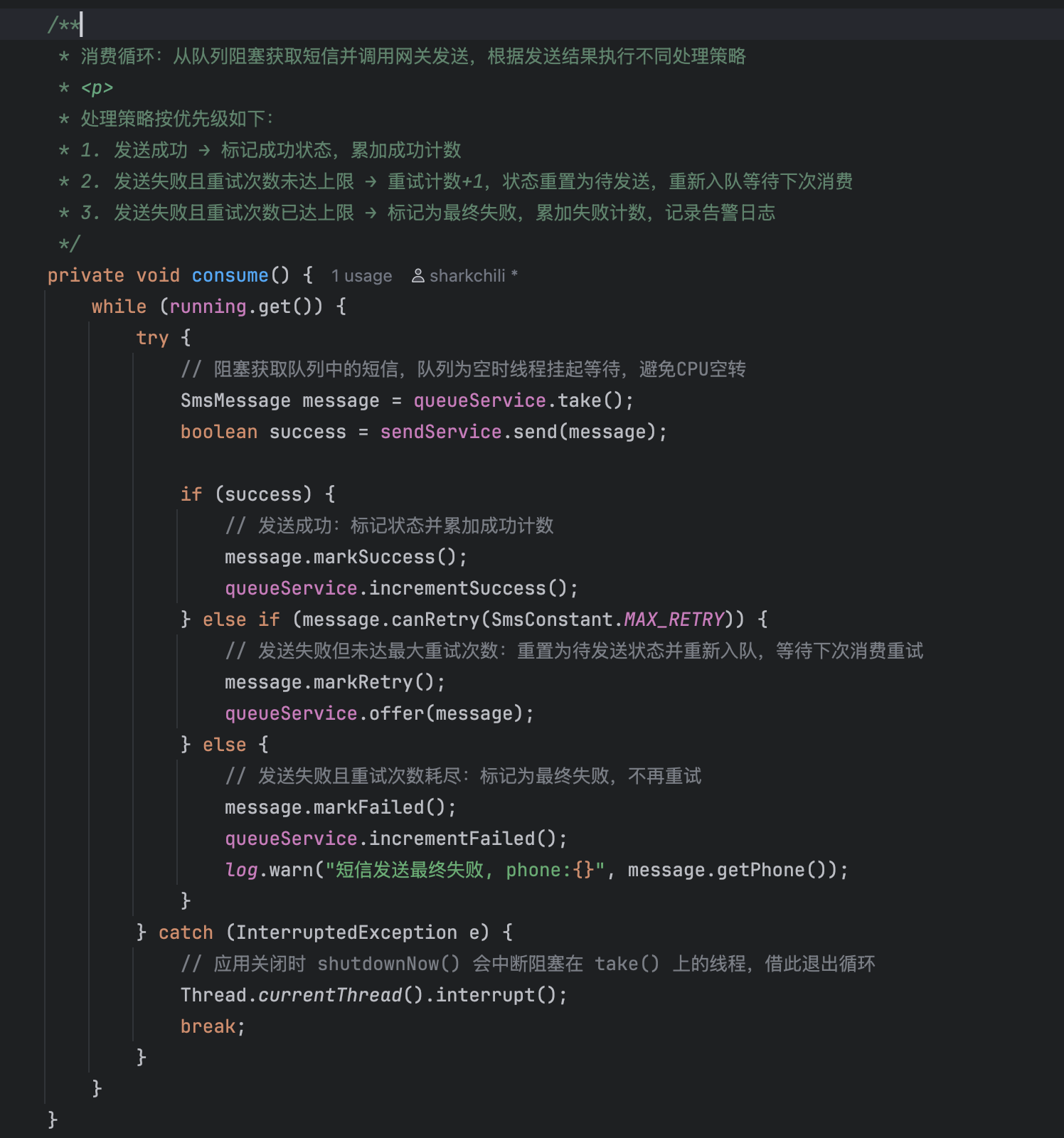
经过全局性的工程源码审查,claude很准确地指出了消费者逻辑的缺陷,即消费逻辑中存在非必要的空转和忙等待,对应代码如下逻辑,若阻塞队列poll方法没有返回元素时,消费者线程会固定休眠100ms,这种做法存在如下缺陷:
- 实时性问题:固定休眠100ms,导致休眠窗口内的消息无法完成实时消费造成延迟
- 空转开销:极端情况下,不是每个休眠后的窗口都存在消息,固定间隔的休眠轮询,会造成非必要的空转开销
private void consume() {
while (true) {
SmsMessage message = queueService.poll();
if (message == null) {
ThreadUtil.sleep(100);
continue;
}
boolean success = sendService.send(message);
if (success) {
message.markSuccess();
queueService.incrementSuccess();
} else if (message.canRetry(SmsConstant.MAX_RETRY)) {
message.markRetry();
queueService.offer(message);
} else {
message.markFailed();
queueService.incrementFailed();
log.warn("短信发送最终失败, phone:{}", message.getPhone());
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
于是,笔者整理该问题痛点,并让AI给出修改建议,在明确无误后进行迭代修改:
在当前项目中发现使用 poll() + sleep(100) 实现的忙等待机制存在问题,建议采用 take() 方法来解决此问题。请针对这个问题提供具体的解决方案和代码改进建议。
# 学会复盘
在经过既有规则与交互过程中,我们势必经历如下过程:
- 方案评审:针对既有需求痛点,与AI进行探索性沟通
- 迭代后功能验收:明确执行步骤后,让AI进行实际编码落地和测试验收
- 编码质量走查:结合既有编码进行必要的代码走查和微调,并进行必要的测试回归
最终,我们就会得到一份标准的版本代码,为了确保后续AI能够基于这份正确的实践进行功能推进,我们建议让AI进行自我复盘总结,得出rules的修改方案:
对应提示词如下,需要补充说明的是,这份提示词并非笔者完全手写,而是结合个人预期理念,将其放到qoder或者trae等IDE中进行提词优化的来的:
结合我们本轮的沟通以及对项目代码的分析,请全面评估我们现有的开发规范(rules)有哪些需要改进的地方?请重点关注以下方面:
1. 现有规范是否存在矛盾或不一致之处
- 检查不同规范文件之间是否存在冲突的要求
- 验证规范与实际代码实现是否一致
- 识别规范描述模糊或容易产生歧义的地方
2. 规范是否覆盖了实际开发中遇到的问题点
- 分析当前代码中存在的潜在问题是否在规范中有对应指导
- 评估规范对常见开发场景的覆盖完整性
- 识别规范空白区域,即缺乏明确指导的开发环节
3. 是否有新的最佳实践需要补充到规范中
- 基于当前项目架构和技术栈,提出需要新增的最佳实践
- 参考行业标准和现代Java开发趋势,建议规范更新
- 针对并发编程、错误处理、日志记录等方面提出改进建议
4. 现有规范的可执行性和实用性如何优化
- 评估规范条款是否具体明确,便于开发者理解和执行
- 分析规范实施过程中可能遇到的实际困难
- 提出使规范更易执行的具体措施
5. 当前规则作用域是否需要进一步调整
- 评估各规范文件的职责划分是否合理
- 分析规范的适用范围是否需要扩大或缩小
- 建议规范组织结构的优化方案
请提供具体的改进建议,并说明每项建议的理由和预期效果。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
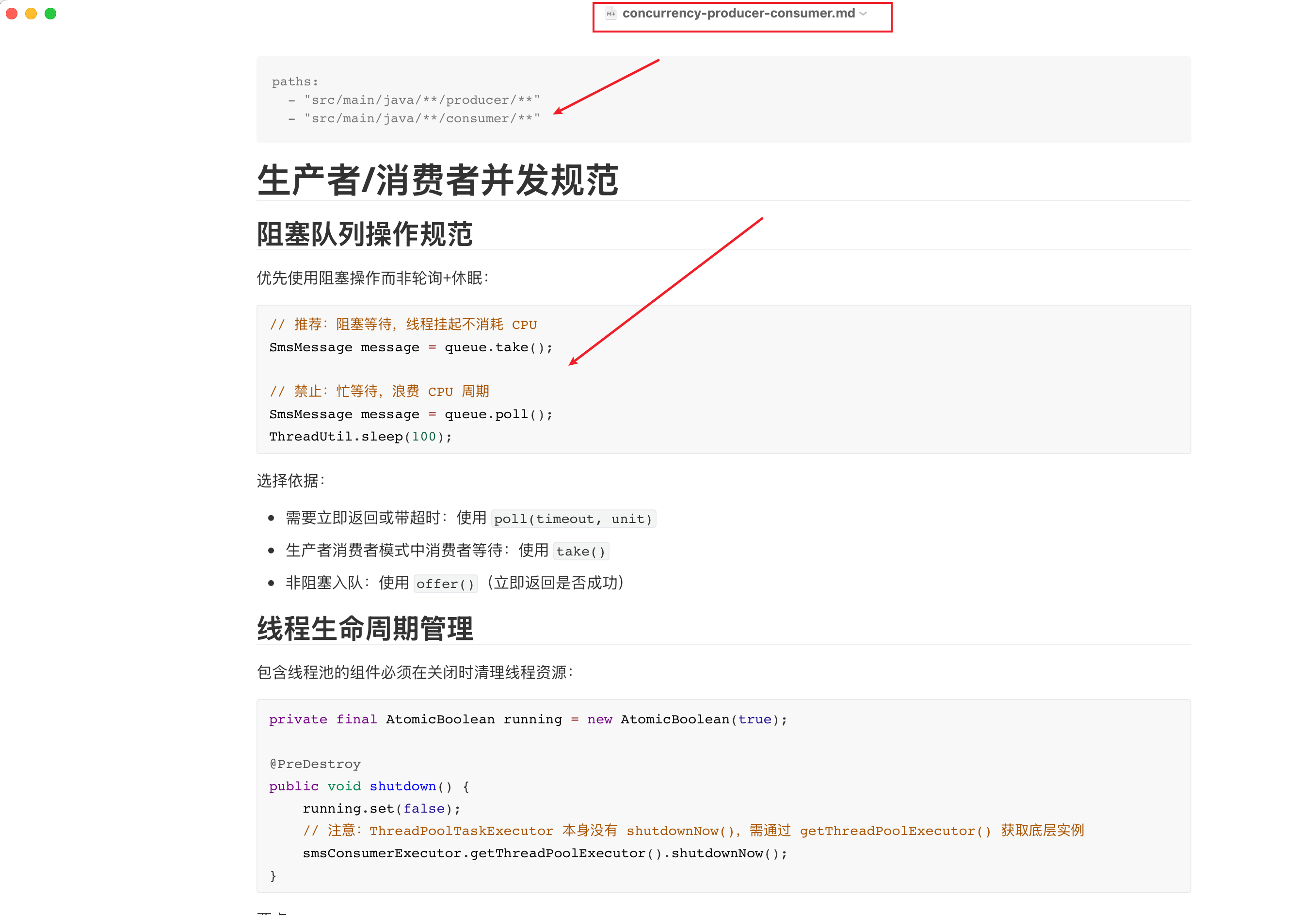
最终AI也准确的针对本轮交互总结出最佳实践,并针对既有规则进行拆分:

如下图,最终我们在既有并发编程规则基础之上,更进一步划定的当前项目的生产者和消费者的最佳实践,后续针对既有需求的迭代拓展,我们就无需重复赘述相同的提词,即可高效完成功能的迭代更新:
# 详解规则的一些常见问题
# 规则是不是写的越细越好
这一点和之前claude.md一文教程中说明的一致,即精确优先于具体,对于优化性需求,笔者非常不建议给出模糊的规则指令例如:
针对并发工具的使用,注意性能和开销问题
我们更希望通过如下具体指令和规则示例,让模型能够准确推理出最相关知识向量进行决策:
在需要使用并发编程工具时,必须根据性能开销和具体应用场景的实用性来选择合适的工具。例如,在写操作较少而读操作频繁的统计场景中,应优先使用LongAdder而非原子类(如AtomicLong)以获得更好的性能表现。
# 如何高效维护规则
这一点上文已经提到,建议先统一维护一份规则文档,通过实际工程场景完成验收后,再让AI完成职责划分、规则迭代升级和匹配模式调整。
需要注意的是,按照Claude Code官方的说法,超过200行的文件会消耗过多的上下文并降低指令遵循度。因此,我们需要在保证规则精准的同时,避免非必要的规则文件造成噪声干扰。这也是笔者专门用一篇完整文章来阐述规则维护技巧的原因。
# 小结
本文以CLAUDE.md文件的痛点为入口,由此引申出rules这一模块化上下文管理机制,并结合rules基本使用、拆分原则和实践详细介绍了规则的理念和使用技巧,希望对你有帮助。
最近笔者也准备了一个免费赠送Claude Code实战书籍的活动,感兴趣的读者可以移步如下链接到评论区踊跃参与:
本本爆款的咖哥,带着首本Claude Code实战书来了! (opens new window)
SharkChili · 计算机路上的禅修者
开源贡献
- mini-redis:教学级 Redis 精简实现 · https://github.com/shark-ctrl/mini-redis
- Nightingale:深度源码研究
关注公众号,回复 【加群】 加入技术社群
# 参考
TRAE 规则(Rules)配置指南:个人习惯、团队规范与最佳实践:https://mp.weixin.qq.com/s/eoSVDBCNssS4m7ul9BGHfA (opens new window)
如何让 AI 更"听话"|Rules 高效使用指南:https://mp.weixin.qq.com/s/60SzfUpnSe5MIKlPwV8FmA (opens new window)
How Claude remembers your project:https://code.claude.com/docs/en/memory (opens new window)
- 01
- Windows 10 下的 Maven 安装配置教程05-11
- 02
- 基于 Claude Code 复刻 Redis 慢查询指令实践05-11
- 03
- VSCode与Claude Code后端开发环境搭建与AI编程工作流实践05-09
