 基于 Claude Code 复刻 Redis 慢查询指令实践
基于 Claude Code 复刻 Redis 慢查询指令实践
# 写在文章开头
写于一个单休的周末,写这篇文章的时候,笔者的心情也是有些唏嘘的,毕竟一直以来经过所谓刻意训练 练就的编码功底,在 AI 时代变得有些贬值。
笔者这一年也在一直纠结这个问题,在这个时代下,我们这些从传统编程范式走来的开发者,是否还需要手写代码?
针对这个问题,笔者也查阅了很多资料,例如:笔者一直追随的一个不断复刻学习的开源中间件 Redis 作者 Salvatore Sanfilippo 也在深度使用 AI 之后,写出了《Don't fall into the anti-AI hype》一文,文章提及写代码已经不再重要,重要的是明白自己要做什么和怎么做,而针对怎么做这点,LLM 也可以深度参与成为我们的最佳助手:
It is now a lot more interesting to understand what to do, and how to do it (and, about this second part, LLMs are great partners, too).
按照作者的观点,基于学习编程付出努力所沉淀的代码、系统和知识,有了 AI 之后,我们反而可以做的更多、更好的作品,我们从繁琐的编码流中抽离,感受软件层级更高层次的设计那种灵感爆发和推动行业进阶发展的快乐:
Yes, maybe you think that you worked so hard to learn coding, and now machines are doing it for you. But what was the fire inside you, when you coded till night to see your project working? It was building. And now you can build more and better, if you find your way to use AI effectively. The fun is still there, untouched.
结合这篇文章在知乎引发的讨论,笔者看到一位名为笙囧同学的回答:

他认为 Salvatore Sanfilippo 只是把自己的理念说出了一半,因为他没有很好地结合自己的背景去阐述自己的理论。要知道,写出 Redis 这样一个能够极致压榨计算机资源的中间件,其背后不仅仅是将想法转为编码那么简单。它不仅需要深厚的计算机知识背景,还需要:
- 理解一个问题
- 拆解一个系统
- 在各种不确定性中做出绝对准确的选择
这就体现了 AI 时代最可贵的一个核心能力:这份代码是否合格
虽然仅仅是 8 个字,这背后隐含着开发者无数的沉淀和经验,即那些通过刻意编码训练和真实生产环境拷打的元能力。
同时,作者还提出,代码这种天然结构化的文本,且自带清晰明确的反馈(可通过编译、测试感知正确与否)的特性,使其具备了非常强大的代码生成能力。
所以,AI 编码只是降低了入行的门槛,但是,在一个复杂的系统中设计、拆解和线上故障排查的决策能力,AI 依然不具备——这才是"写代码已经不重要了"背后那句需要补充的话。
结合这些文章和论点,笔者依然以一个折中派的方式给出自己的见解,即:
- 学习时:采用主动检索思考和动手刻意训练,轻度 AI 辅助梳理保证个人能力的成长
- 实际工作时:将学习阶段的沉淀,引导 AI 更精准地推理和输出,并适时和 AI 进行复盘总结,了解自己的不足之处并加以学习补充
于是也就有了这篇折中的文章,针对笔者一直以来维护的开源项目 mini-redis,近期复刻的慢查询功能也都是依靠 AI 完成的,为了让读者着重于学习 Redis 这一理念,笔者还是以学习的视角完成 Redis 慢查询功能的讲解,再以企业级开发的方式,介绍笔者日常针对这种异构语言复刻的实践。
希望这个百家争鸣的时代,这篇折中的文章,对你有所帮助。
SharkChili · 计算机路上的禅修者
开源贡献
- mini-redis:教学级 Redis 精简实现 · https://github.com/shark-ctrl/mini-redis
- Nightingale:深度源码研究
关注公众号,回复 【加群】 加入技术社群
# 详解慢查询的设计与实现
# 慢查询指令基本设计
Redis 本身就是为了高效读写而生,所以对于监控这方面,也给出了慢查询这一解决方案。即针对每次指令读写,都进行前后打点,判断本次执行耗时是否超过给定阈值,如果超了则缓存到内存列表中,并提供查询指令供使用者查询从而进行进一步的决策。
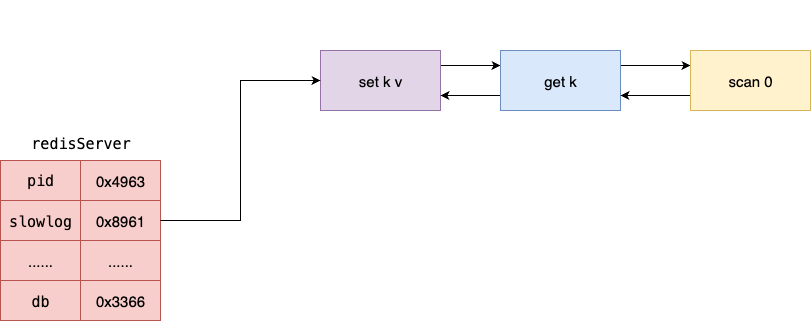
如下图所示,Redis 服务端在启动时,会初始化一个 slowlog 列表指针,用于维护后续超过阈值的慢查询指令信息。
# 核心参数介绍
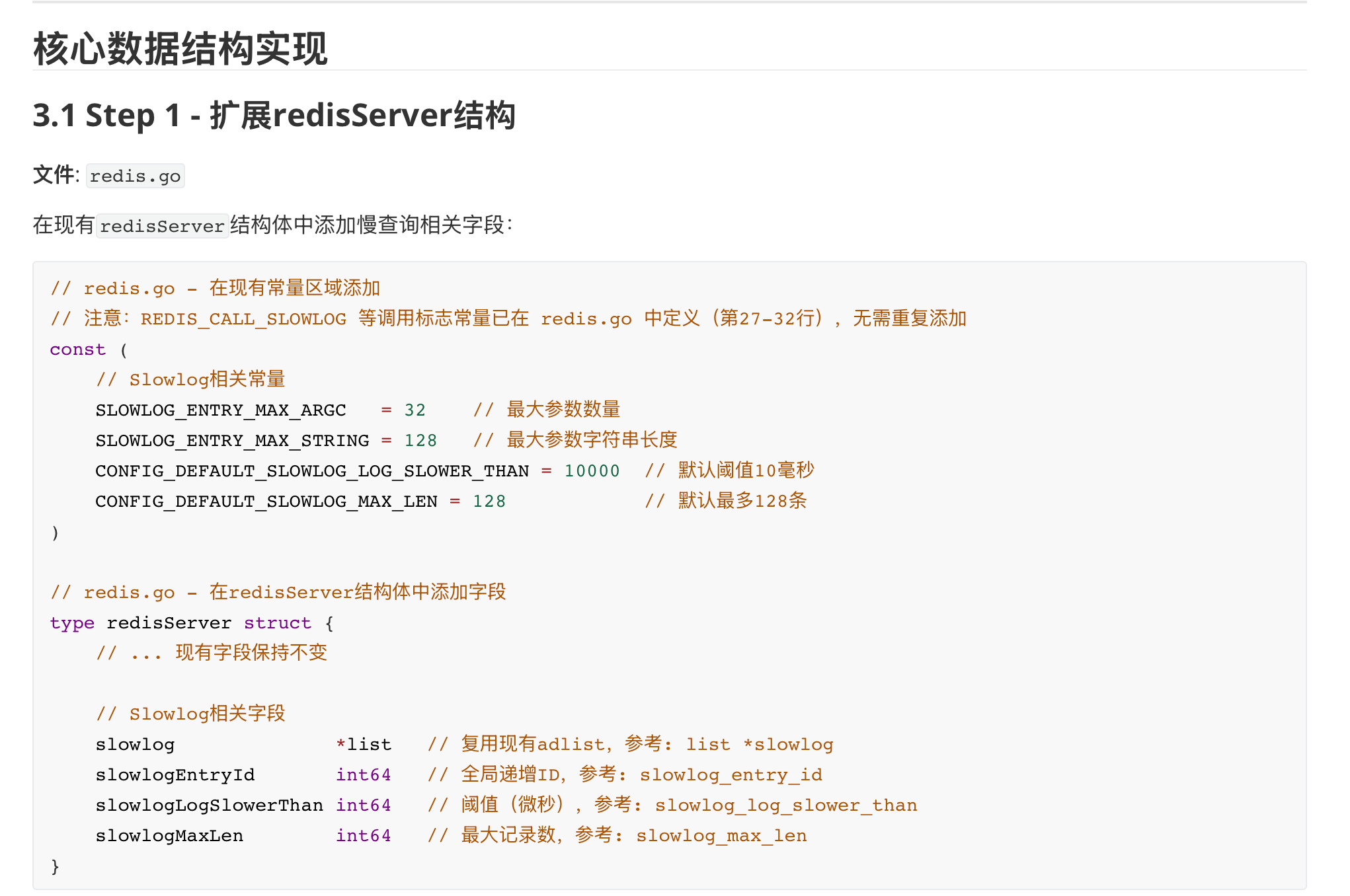
对应的笔者也给出 redisServer 结构体的源代码,可以看到针对慢查询这一个功能,Redis 围绕着这 4 个核心参数实现:
- slowlog:慢查询列表,用链表的形式记录所有慢查询指令
- slowlog_entry_id:为了表示每一条慢查询指令,Redis 全局统一地维护了一个变量 slowlog_entry_id,采用自增的方式维护下一条慢查询信息的 id
- slowlog_log_slower_than:判定为慢查询的时间阈值,单位微秒
- slowlog_max_len:记录慢查询的链表的长度
struct redisServer {
//保存慢查询日志的链表
list *slowlog; /* SLOWLOG list of commands */
//下一条慢查询的日志id
long long slowlog_entry_id; /* SLOWLOG current entry ID */
//慢查询日志的阈值
long long slowlog_log_slower_than; /* SLOWLOG time limit (to get logged) */
//慢查询链表的最大长度
unsigned long slowlog_max_len;
//......
}
2
3
4
5
6
7
8
9
10
11
12
笔者着重强调一下 slowlog_max_len 这个参数,为避免物理内存被耗尽,Redis 通过该参数设定了列表的上限,默认为 128,对应代码如下所示:
#define CONFIG_DEFAULT_SLOWLOG_MAX_LEN 128
//初始化时,设置为128
server.slowlog_max_len = CONFIG_DEFAULT_SLOWLOG_MAX_LEN;
2
3
4
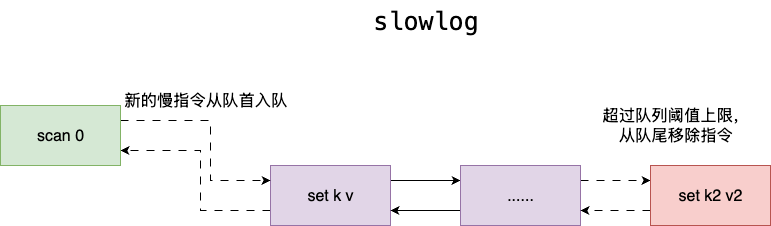
该列表按照 FIFO 算法维护,即最新的慢指令在队首,所以在删除时也是从队尾进行删除,这样做的好处就是尽可能保证慢查询排查的准确性和时效性:
# 核心数据结构说明
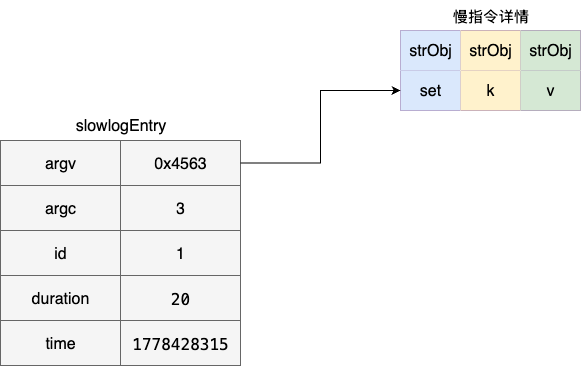
了解了宏观的概念之后,我们展开说明一下慢查询的队列,Redis 底层通过 slowlogEntry 这个结构体维护每个慢指令元素,该结构体包含以下信息:
- argc:慢指令参数个数,例如:set k v,对应的参数个数就是 3
- argv:慢查询指令结构体,记录指令以及指令的一些类型、编码格式等信息,为降低读者的理解负担,这里我们就可以理解为用户提交的一条指令,例如:set k v
- id:慢指令的唯一标识,由上文提到的全局变量 slowlog_entry_id 统一分配
- duration:一条慢指令查询所消耗的时间,辅助开发者进一步判断决策这条慢指令的严重情况
- time:慢指令的执行时间,严格来说应该是记录这条指令的时间,具体笔者会在后文补充说明,不过时间上相差不大,理解为慢查询指令的执行时间也是可行的
对应的数据结构示例如下:
同时,笔者这里也贴出了源代码,读者可结合上述说明学习理解:
/* This structure defines an entry inside the slow log list */
typedef struct slowlogEntry {
//命令以及命令的参数
robj **argv;
//参数的数量
int argc;
//慢查询日志的唯一标识符
long long id; /* Unique entry identifier. */
//查询所花费的时间,以微秒为单位
long long duration; /* Time spent by the query, in microseconds. */
//命令执行的时间,也就是时间戳
time_t time; /* Unix time at which the query was executed. */
} slowlogEntry;
2
3
4
5
6
7
8
9
10
11
12
13
14
# 慢指令的添加
Redis 通过统一的 proc 函数处理所有客户端键入的指令,所以慢指令的监控就设置在该函数前后,执行前记录开始时间 start,在指令执行结束后,基于开始时间计算本次执行是否超过阈值,如果超过则直接将该指令打包成 slowlogEntry 写入慢指令队列 slowlog 中:

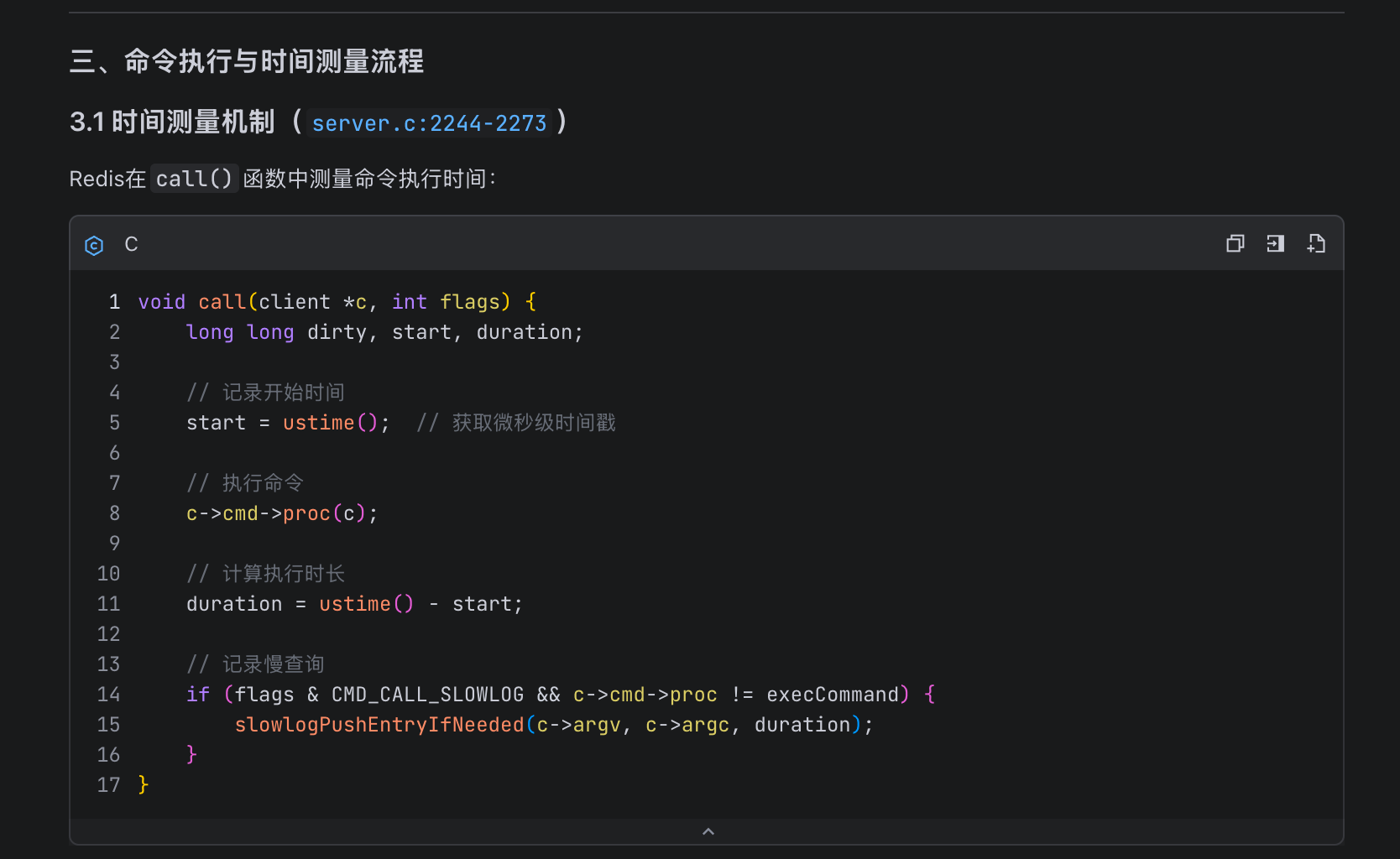
对应我们也给出慢指令记录和写入的逻辑,即位于 server.c 的 call 方法,对应核心代码段如下:
//记录开始时间
start = ustime();
//执行客户端提交的指令
c->cmd->proc(c);
//计算执行时间
duration = ustime()-start;
//......
if (flags & CMD_CALL_SLOWLOG && c->cmd->proc != execCommand) {
char *latency_event = (c->cmd->flags & CMD_FAST) ?
"fast-command" : "command";
//......
//传入执行耗时查看是否超出慢日志的阈值,超出则记录到慢日志中
slowlogPushEntryIfNeeded(c->argv,c->argc,duration);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
展开 slowlogPushEntryIfNeeded 函数,其内部本质要做的和函数名一样,进行必要的条目写入,对应函数的执行逻辑分为三大部分
- 判断 slowlog_log_slower_than 是否小于 0,若是则说明不记录慢查询指令信息,直接返回
- 查看执行耗时 duration 是否超出阈值 slowlog_log_slower_than,如果是则直接构建 slowlogEntry 记录该慢指令的信息,可以看到源代码中设置的time是当前时间,也就是为什么笔者上文强调time更具体来说是记录慢指令的时间,而非实际指令执行时间。
- 判断指令队列长度是否超出上限,若超出则直接将最早写入的元素淘汰
这里有个细节需要注意一下,进行慢指令淘汰时,对应代码用的是 while 而非 if,这个设计我们不妨结合执行表象进行渐进式推导:
- 是什么情况下会导致写入一次的慢指令入队操作需要多次淘汰
- 每次写入只会伴随一次的入队操作,需要多次淘汰说明,判定的规则发生变化
所以答案是 slowlog_max_len 可动态变更,从这里不难看出作者处理之细致。说句题外话,笔者认为这种处理也可能是因为使用过程中才会发现的 bug,这也符合软件开发一贯的说法,好的程序并非一蹴而就,而是需要时间不断迭代和打磨:
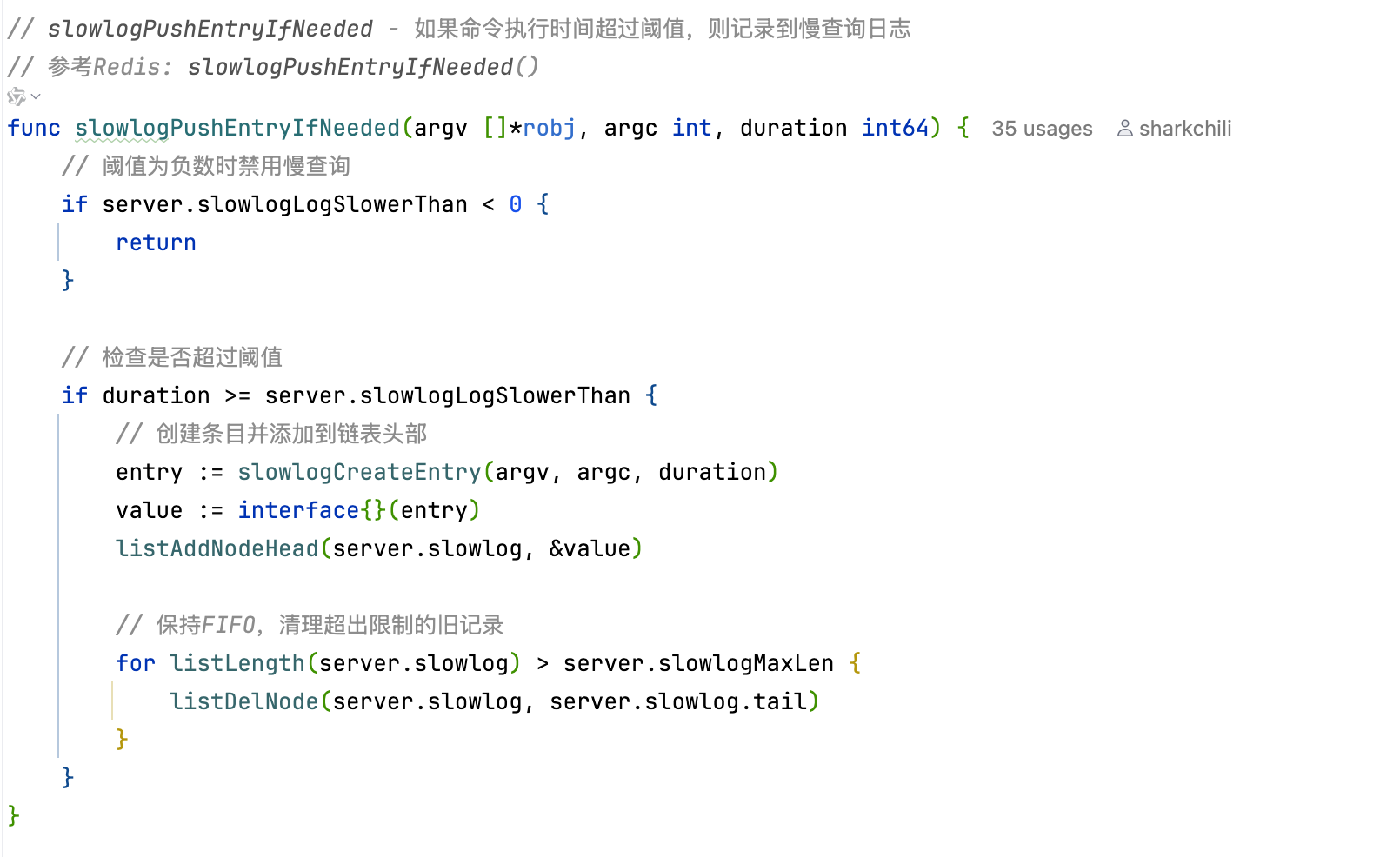
void slowlogPushEntryIfNeeded(robj **argv, int argc, long long duration) {
//如果没有超过慢查询的阈值则直接返回
if (server.slowlog_log_slower_than < 0) return; /* Slowlog disabled */
//超过阈值则通过头插法写入慢查询列表
if (duration >= server.slowlog_log_slower_than)
listAddNodeHead(server.slowlog,slowlogCreateEntry(argv,argc,duration));
/* Remove old entries if needed. */
//如果慢查询的长度超过阈值,则淘汰最早插入的那条(最早的慢查询日志,留着没什么意义)
while (listLength(server.slowlog) > server.slowlog_max_len)
listDelNode(server.slowlog,listLast(server.slowlog));
}
2
3
4
5
6
7
8
9
10
11
12
# 慢查询指令查询流程
按照 Redis 指令的维护风格,所有指令都会以指令名称 + command 的方式命名,所以慢查询的函数名则是 slowlogCommand,对应的源代码如下所示,逻辑也比较简单:
- 判断参数个数,如果为 3 则说明指令为 slowlog get n,n 为需要输出的近 n 条慢指令,反之则输出 10 条慢指令
- 遍历 slowlog,解析每个 slowlogEntry 的 id、时间戳、耗时、以及指令明细等信息
- 生成足够 n 组的慢指令之后,输出返回客户端

对应源代码如下:
/* The SLOWLOG command. Implements all the subcommands needed to handle the
* Redis slow log. */
void slowlogCommand(client *c) {
if (c->argc == 2 && !strcasecmp(c->argv[1]->ptr,"reset")) {
//......
} else if (c->argc == 2 && !strcasecmp(c->argv[1]->ptr,"len")) {
//......
} else if ((c->argc == 2 || c->argc == 3) &&
!strcasecmp(c->argv[1]->ptr,"get"))
{
//......
//count初始化为10,即默认输出10条慢指令
long count = 10, sent = 0;
//如果指令长度为3,则说明用户显示指定参数个数,需要正确解析修改count
if (c->argc == 3 &&
getLongFromObjectOrReply(c,c->argv[2],&count,NULL) != C_OK)
return;
//指向慢查询日志的指针,并采用头插法进行遍历
listRewind(server.slowlog,&li);
//得到用于写入响应结果的指针
totentries = addDeferredMultiBulkLength(c);
while(count-- && (ln = listNext(&li))) {
int j;
se = ln->value;
/**生成一条慢查询结果集参数,值为4
* 包含慢查询日志的唯一标识符、
* 命令执行的时间戳、
* 查询所花费的时间以及命令和参数列表
*/
addReplyMultiBulkLen(c,4);
//慢指令id
addReplyLongLong(c,se->id);
//慢指令执行的时间戳
addReplyLongLong(c,se->time);
//慢指令执行的耗时
addReplyLongLong(c,se->duration);
//按照argc 写入指令 例如 3 => set key value
addReplyMultiBulkLen(c,se->argc);
for (j = 0; j < se->argc; j++)
addReplyBulk(c,se->argv[j]);
sent++;
}
//将客户端从待写入列表删除
setDeferredMultiBulkLength(c,totentries,sent);
} else {
addReplyError(c,
"Unknown SLOWLOG subcommand or wrong # of args. Try GET, RESET, LEN.");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
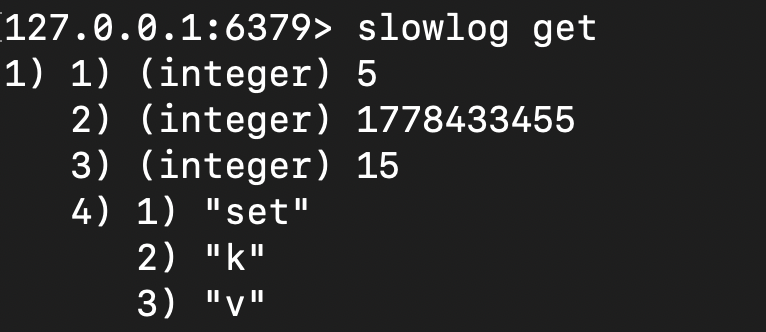
如下图,键入慢查询 slowlog get 指令之后,Redis 输出 id、时间戳、耗时和指令明细的信息:
# 慢查询数据删除
一款好的开源中间件势必会考虑到各个方面,例如 Redis 对于慢指令的维护不仅仅支持有界的写入,同时还支持用户手动清除,以手动挡的方式进行 Redis 内存的维护,对应指令如下:
slowlog reset
而底层的执行原理也非常简单,通过 listLength 判断当前慢指令队列长度,不为 0 则不断从尾部删除,直到队列为空
void slowlogReset(void) {
//判断即时队列长度是否为0,若不为0则删除最后一个节点,直到队列长度为0
while (listLength(server.slowlog) > 0)
listDelNode(server.slowlog,listLast(server.slowlog));
}
2
3
4
5
# 基于 Claude Code 的 slowlog 指令复刻
# 工作流说明
上述则是笔者在传统编程时代至今一直保留的源码梳理和阅读习惯,即宏观了解、执行调测、图文梳理复盘总结,再动手实践复刻,而有了 AI 之后,整个复刻工作则变得比较简单,正如笔者所说,这个时代我们知道自己要做什么。
所以,结合复刻 Redis 慢查询这一需求,我们可以理解为我们日常的逻辑迁移即软件重构之类的任务,本质上就是基于旧有的逻辑,在新的技术栈中进行复刻实现,同时可能还会进行一些适配和优化。
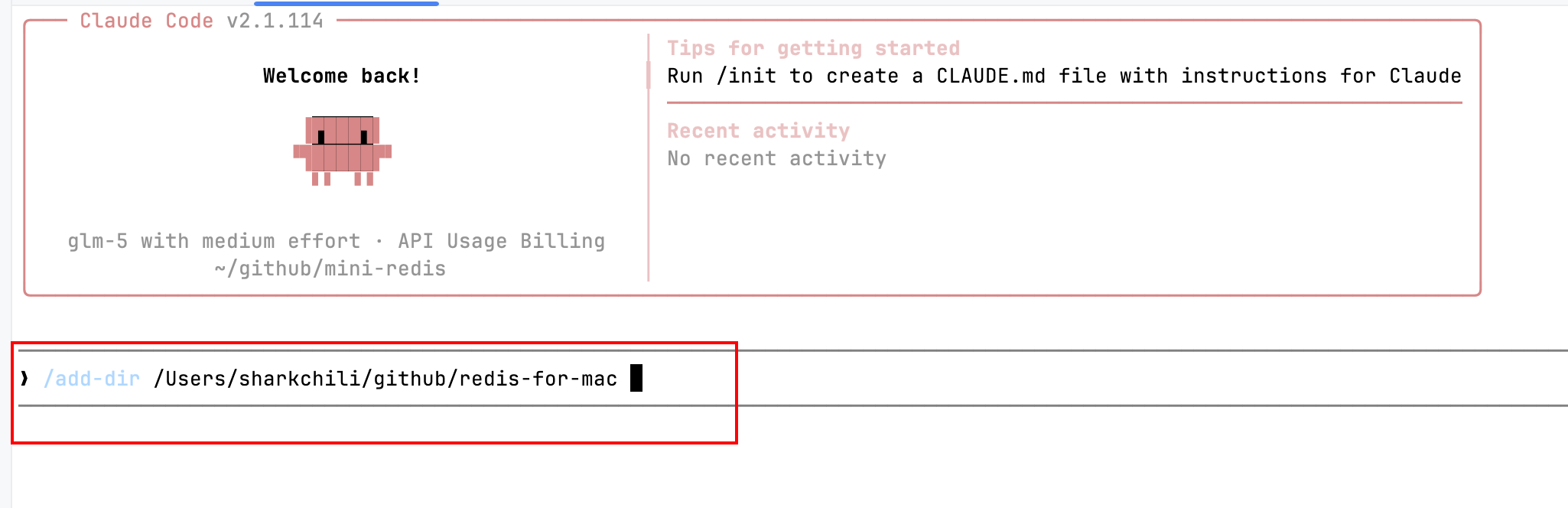
从 AI 编码的工作流来说,就是将两套系统作为上下文,让 AI 进行阅读旧有系统逻辑并着手进行梳理。这里笔者就以个人常用的 Claude Code 为例,对应的执行工作流则会建议在充分理解学习阅读 Redis 源码之后执行。即在笔者个人的开源项目 mini-redis 中用 /add-dir 指令将 Redis 上下文传入 mini-redis 的 Claude Code 工作流,让 Claude Code 能够读取和操作这些目录下的文件,使其具备更充分的上下文,理解本次任务的目标和实现思路,从而得出更准确的工程代码:
我们直接将 Redis 源代码上下文添加到 mini-redis 中,确保其具备足够的上下文信息,理解 Redis 慢查询的实现并结合当前项目风格完成复刻:
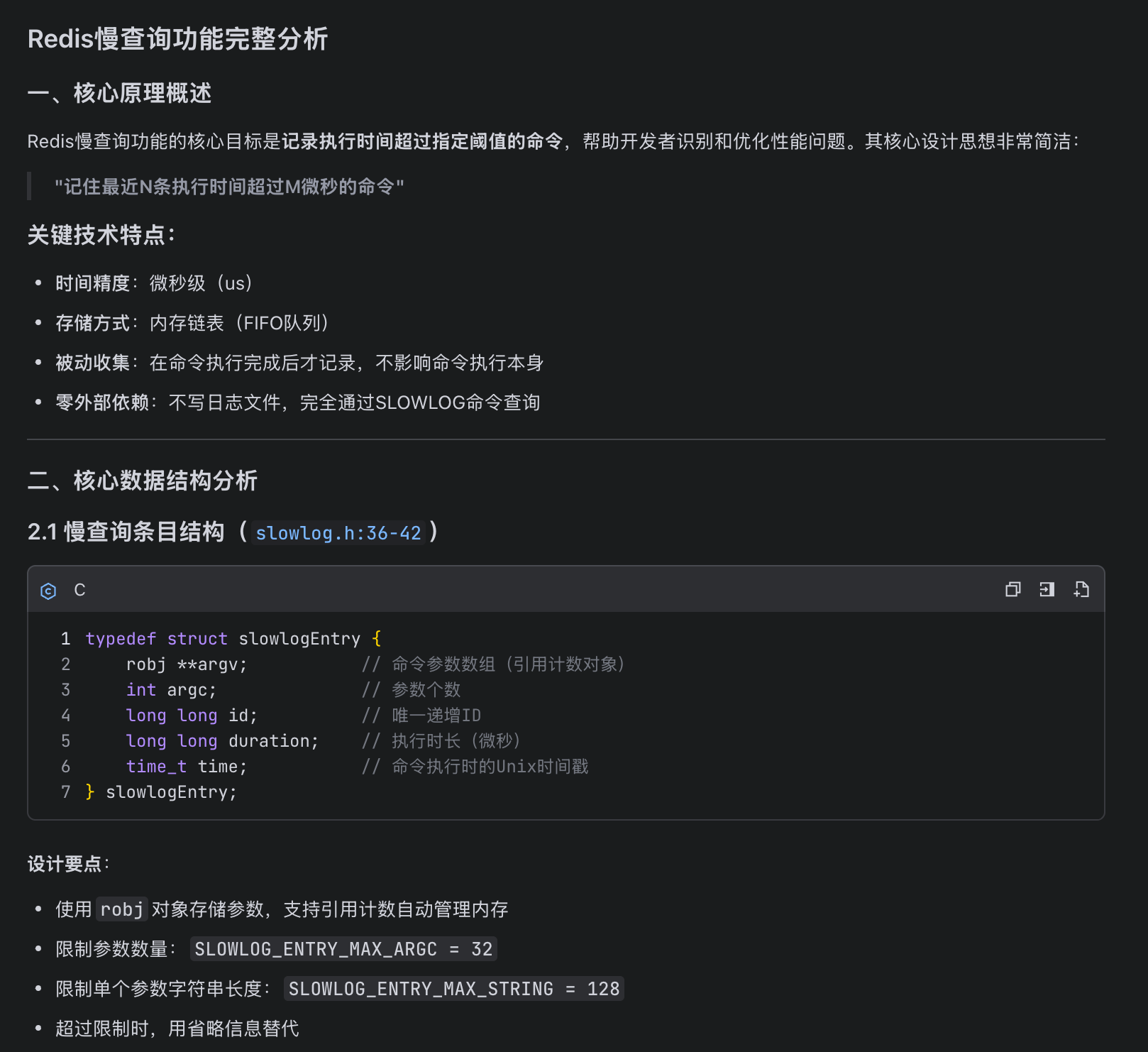
# 方案审查
因为有了之前源代码的阅读经验,所以对于它的输出信息,我们都能够进行准确的决策,可以看到 LLM 对于 Redis 的实现原理、参数细节和数据结构都进行了精准的定位和梳理分析:
对于慢查询的打点和写入,LLM 也非常准确地将非必要的代码枝干抹去,保留最核心的部分供我们阅读理解对齐:
明确思路无误之后,我们让其输出 spec 规格文档,这里笔者考虑到方案落地的准确性,要求其详细输出每一个步骤,这里笔者也给出 LLM 规范的第一步。可以看到,其落地也是非常有条理,先定义常量和结构体,然后再进行逐步的队列初始化、配置加载、逻辑填充等,具体可参考笔者项目的 mini-redis-slowlog-spec.md 文件:
# 代码验收
AI 之所以提效是因为它对于编码这种高度一致,且通过海量开源项目即可完成训练的任务非常擅长。所以在逻辑和思路清晰的情况下,代码质量是非常高的,这里的高不仅是指逻辑编码,还包括结构、注释等。
例如慢查询队列维护函数 slowlogPushEntryIfNeeded,对应代码截图如下,可以看到,LLM 不仅准确地按照 Redis 的逻辑完成复刻,也非常精准地结合当前上下文信息得出复刻工程为 Go 语言,从而非常准确地完成语法上的适配:
因为是开源项目,所以为了保证绝对的可用性,笔者还是会保持人工验收的习惯,为了更好地测试这一功能,笔者直接将慢查询的阈值和队列长度分别设置为 0、1,确保每次执行指令都会写入慢查询队列,且永远只维护最新的一条:
# 慢查询阈值(微秒)
# 执行时间超过此值的命令会被记录到慢查询日志中
# 负值表示禁用慢查询日志,0 表示记录所有命令
# 默认值:10000(10毫秒)
slowlog-log-slower-than 0
# 慢查询日志最大长度
# 慢查询日志使用 FIFO 队列,当超过此长度时,最旧的记录会被移除
# 默认值:128
slowlog-max-len 1
2
3
4
5
6
7
8
9
10
11
对应的输出结果如下,我们先进行 kv 键值对的设置,然后通过慢指令获取慢查询日志信息,可以准确看到我们的 kv set 指令:
127.0.0.1:6379> set k v
OK
127.0.0.1:6379> slowlog get
1) 1) (integer) 1
2) (integer) 1778465322
3) (integer) 29
4) 1) "set"
2) "k"
3) "v"
2
3
4
5
6
7
8
9
10
11
12
随后,我们再设置 k1 和 v1,进行一次日志查询。可以看到,日志被覆盖为最新的一次 set 操作,由此验收初步通过:
127.0.0.1:6379> set k1 v1
OK
127.0.0.1:6379> slowlog get
1) 1) (integer) 3
2) (integer) 1778465330
3) (integer) 14
4) 1) "set"
2) "k1"
3) "v1"
2
3
4
5
6
7
8
9
# 复盘与沉淀
正如人的学习一样,通过日常的复盘和沉淀提升知识的内化效果,为了让 AI 下次能够更精准地完成此类重构迁移的任务,我们可以通过对话的上下文让其分析本次工作的过程中它需要沉淀的上下文信息,确保其下次执行此类任务时,可以更加高效、快速、准确地完成,避免非必要的上下文推理开销和漫长的等待,同时还保证交付的准确性。
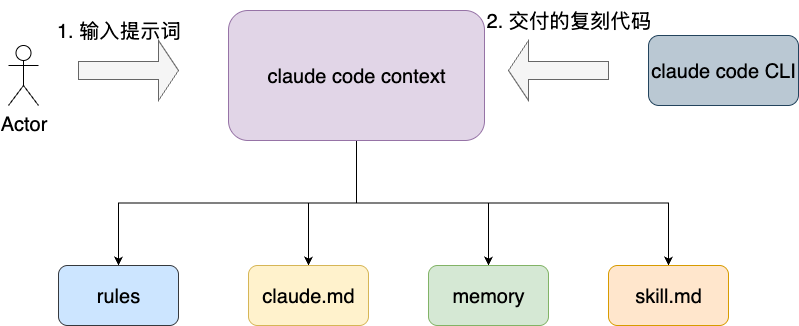
对应笔者也给出自己的提示词供读者参考:
@docs/mini-redis-slowlog-spec.md 基于我们梳理的mini-redis项目结构和代码实现所沉淀的spec文档请分析并总结在复刻Redis指令功能过程中可以沉淀哪些可复用的Claude.md、rules、memory或skill
最终 LLM 的输出结果如下,我们先来看看第一个复用资产即 claude.md 文件对应统一架构风格的规范,这些条目明确地指出架构风格和开发模式,确保模型下次编码的整体基调的准确性:

然后是 rules,可以看到,模型结合我们工作的上下文准确地提出 Redis 的命名规范和参数规约,以及一些统一的异常处理细节:

通过每次编码沟通的交互和迭代,按照工程化标准维护上下文,我们会得到一个不断强化怎么做的最佳拍档,这就是笔者给出的 AI 编程工作流的认知和实践。
# 小结
针对 AI 时代的软件开发范式的讨论,笔者结合一些主流观点和认知,按照折中的方式给出一种可持续进步的方向,即偏向古法的探究学习和偏向 AI 的落地验收,希望对你有所启发。
SharkChili · 计算机路上的禅修者
开源贡献
- mini-redis:教学级 Redis 精简实现 · https://github.com/shark-ctrl/mini-redis
- Nightingale:深度源码研究
关注公众号,回复 【加群】 加入技术社群
# 参考
Don't fall into the anti-AI hype:https://antirez.com/news/158 (opens new window)
Claude Code /add-dir:被低估的 Monorepo 神器:https://blog.vincentqiao.com/claude-code-add-dir/#:~:text=%2Fadd-dir 是 Claude Code 的一个斜杠命令,让你在对话过程中把额外的目录添加到 Claude Code 的工作范围中,让它能够读取和操作这些目录下的文件。,Code 看到更多代码。 %2Fadd-dir 有两种使用方式:一种是在对话中随时添加,另一种是启动时就指定好。 在 Claude Code 交互模式下输入: (opens new window)
Redis 之父称「手写代码不再必要」,你如何看待 AI 对编程的影响?:https://www.zhihu.com/question/1995213825918641040/answer/2010075171223013243 (opens new window)
黄健宏《Redis 设计与实现》
Redis SLOWLOG 命令:https://redis.com.cn/commands/slowlog.html (opens new window)
- 01
- Windows 10 下的 Maven 安装配置教程05-11
- 02
- VSCode与Claude Code后端开发环境搭建与AI编程工作流实践05-09
- 03
- Windows环境下JDK安装与环境变量配置05-09
