 记一次StarRocks源码级排错和既有架构优化实践
记一次StarRocks源码级排错和既有架构优化实践
# 写在文章开头
在AI飞速发展的时代,笔者还是会停下脚步进行复盘,例如这次要讲的一个项目架构上的优化,笔者也常想,借助此时的AI的知识语料和上下文推理的能力,如果再次面对这个问题。我会有什么样的决策?最终又会收获什么?
答案是未知的,我可能会在别的维度有所收获,也可能没有。不过好在这件事发生在过去,我合理的通过自己的元认知并协调各方资源维稳的修复这个问题。
所以,笔者今天还是非常乐意将这件事分享出来,希望让读者能够借助这个时间的资源,放大这份能力和工作理念。
SharkChili · 计算机路上的禅修者
开源贡献
- mini-redis:教学级 Redis 精简实现 · https://github.com/shark-ctrl/mini-redis
- Nightingale:深度源码研究
关注公众号,回复 【加群】 加入技术社群
# 背景说明
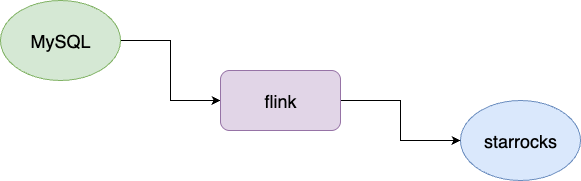
笔者所负责的一个核心平台涉及大量交易业务的聚合分析和报表查询,考虑到检索性能表现同时避免核心交易流水库受这些聚合查询的扰动出现严重的性能损耗,团队的业务建立初期就选用 StarRocks 作为业务库,对应的数据也是采用 Flink 监听 MySQL 变更进行同步:
随着业务的稳步拓展,交易流水稳步上升,与之带来的既有报表分析查询业务偶发出现如下问题报错:
The tablet write operation update metadata take a long time
# 排查过程
# 根因定位与推导
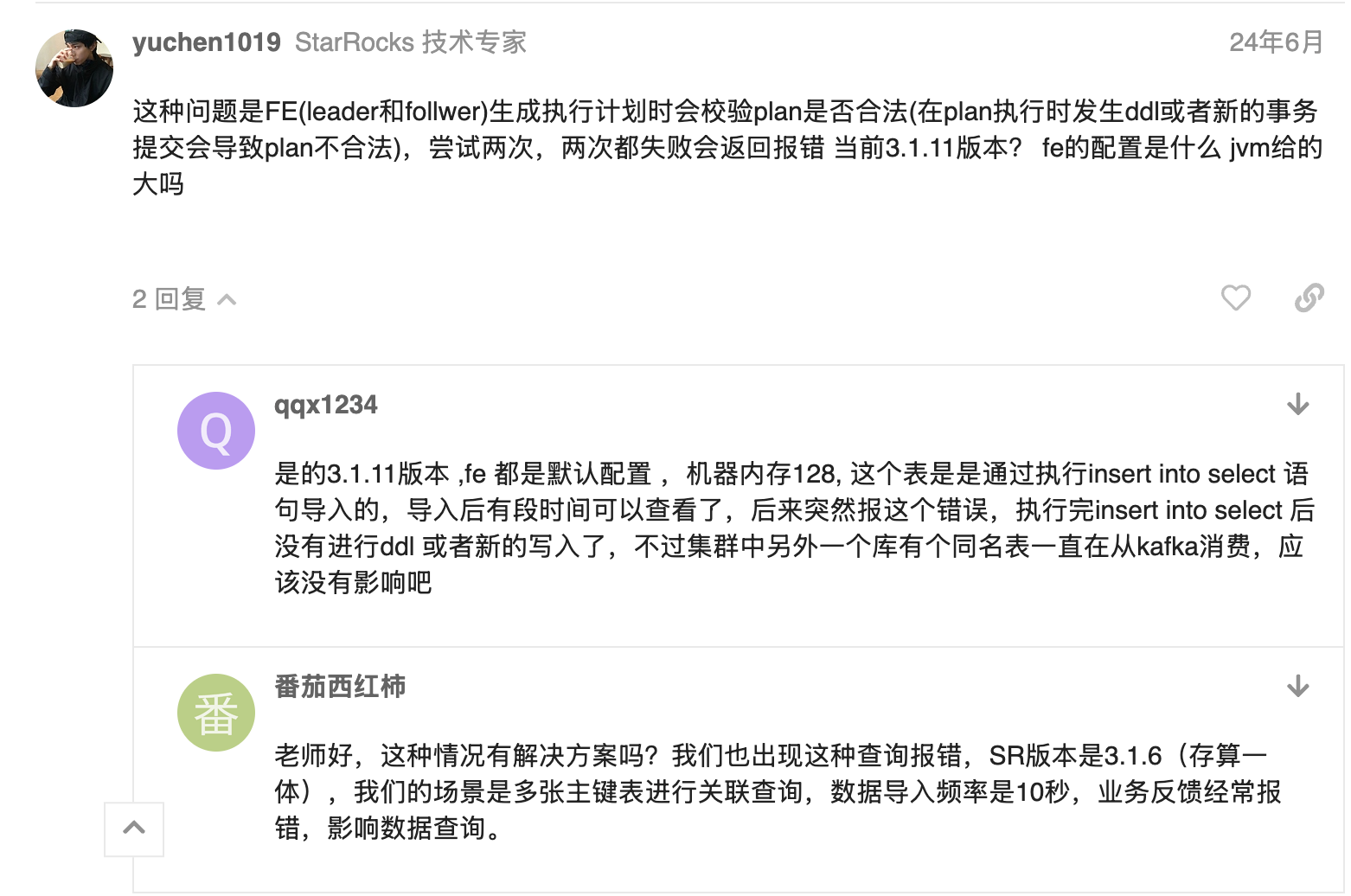
因为是初次遇到该问题,结合语义笔者也没有能得出一个大概,于是到官方社区检索下面这段回答:
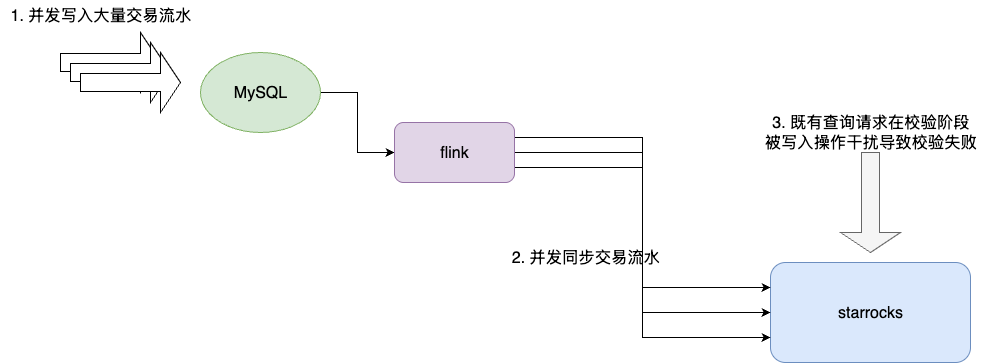
结合笔者在团队中看到的grafana面板上的指标综合分析,初步判断是近期攀升的交易流水频繁写入,导致平台上的实时查询计划在校验期间被这些写入请求所扰动,进而导致校验不合法从而导致检索失败:
# 临时止血
初步定位问题根因之后,本着风险点最小的方式先进行临时止血,再从长计议,针对既有表象和论坛上一些说法,我们协调的交易侧服务相关负责人进行一次技术会议,给出如下临时方案:
- 所有接口统一捕获该问题,并进行一次重试
- 若重试依然失败,直接降级到一个MySQL从库,牺牲一点查询效率,保证报表分析数据能够给到业务侧
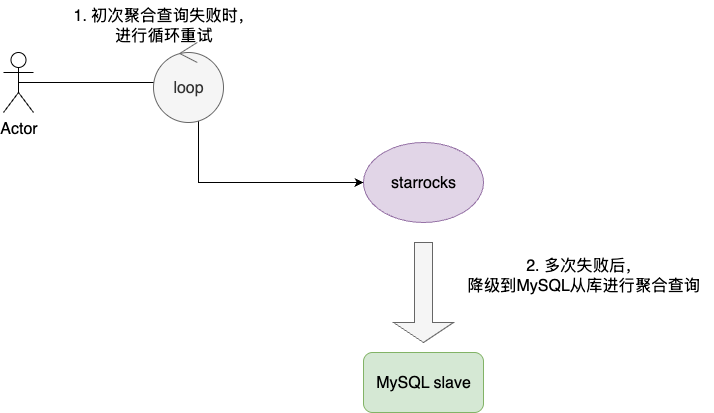
业务将该问题推导优先级,并花费三天时间完成临时改造并送到生产,期间笔者也针对既有问题,在grafana上面板上补充监控该问题的重试次数和落入MySQL的频率,以观察问题持续严重性并及时针对临时止血策略进行动态调整。
# 源码级优化
通过上述一系列策略,我们相对平稳的压住业务上的异常。本着定位根因有效根治的理念,笔者在上述方案落地后,结合ELK面板上既有问题的栈帧, 通读了 StarRocks 官方文档和既有版本的 StarRocks 源码,最终了解到的问题的全貌。
作为分布式列式存储数据库,starrocks将节点分为FE和BE,对于读写请求,starrocks都会交由FE节点校验该计划的合理性,明确无误之后,将执行计划分发给各个 BE 执行,其中会选定一个 BE 节点作为 Coordinator 负责调度执行并聚合结果返回给客户端:
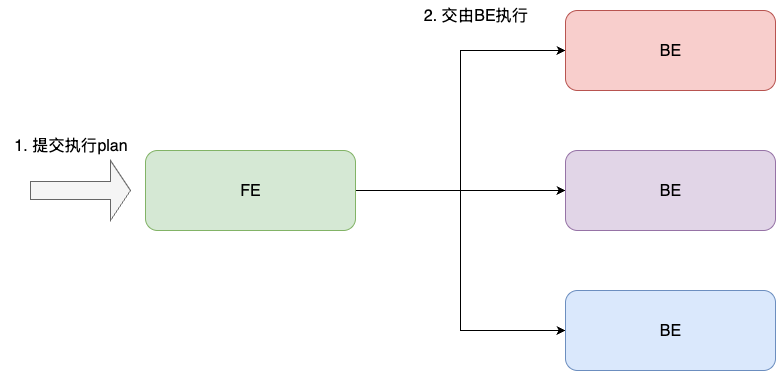
结合starrocks FE源码,笔者发现,在FE校验执行阶段,当明确感知执行计划收到干扰时,FE会休眠10ms之后进行重试,当再次重试失败后,就会抛出上述错误,对应的笔者也给出这段校验充实的核心逻辑,即 StatementPlanner 的createQueryPlanWithReTry方法核心逻辑,可以看到它会基于系统参数max_query_retry_time在plan校验失败后,进行短暂休眠在重试:
// StatementPlanner 核心逻辑
// 1. 执行计划重试循环,默认最多重试2次(由 max_query_retry_time 控制)
for (int i = 0; i < Config.max_query_retry_time; ++i) {
long planStartTime = OptimisticVersion.generate();
// 2. 生成逻辑计划
LogicalPlan logicalPlan = new RelationTransformer(transformerContext).transformWithSelectLimit(query);
// 3. 优化逻辑计划,生成物理计划
OptExpression optimizedPlan = optimizer.optimize(...);
// 4. 构建执行计划
ExecPlan plan = PlanFragmentBuilder.createPhysicalPlan(...);
// 5. 关键校验:检查计划生成期间表的 Schema 是否发生变化
isSchemaValid = olapTables.stream().noneMatch(t -> t.lastSchemaUpdateTime.get() > planStartTime);
// 6. 二次校验:检查表的版本更新是否在计划构建期间完成
isSchemaValid = isSchemaValid && olapTables.stream().allMatch(t ->
t.lastVersionUpdateEndTime.get() < buildFragmentStartTime &&
t.lastVersionUpdateEndTime.get() >= t.lastVersionUpdateStartTime.get());
if (isSchemaValid) {
return plan; // 校验通过,返回执行计划
}
// 7. 如果检测到有表正在更新中(开始时间 > 结束时间),等待10ms后重试
// 10ms 对应 publish_version_interval_ms 配置项
if (olapTables.stream().anyMatch(t -> t.lastVersionUpdateStartTime.get() > t.lastVersionUpdateEndTime.get())) {
Thread.sleep(10);
}
}
// 重试次数耗尽,抛出异常 → 页面崩溃
Preconditions.checkState(false, "The tablet write operation update metadata " +
"take a long time");
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
结合这段源代码,笔者顺着max_query_retry_time这个参数定位到参数定义加载相关代码段,看到其元注解存在一个mutable的语义且设置为true,大体推测这个参数是可以修改的:
@ConfField(mutable = true)
public static int max_query_retry_time = 2;
2
于是,笔者再次回到官网检索相关资料,最终印证了这个说法,于是,笔者提供了更进一步的止血策略,即调大最大重试次数。

借助上一轮预埋的监控,笔者让相关服务负责人调大接口层面的重试次数和降低的代码逻辑,最终看到在4次左右就,既有的 StarRocks 就可以完成聚合查询,所以我们尝试将该参数设置为5,初步保证的业务的稳定性。
# 架构调优
明确没有生产上的担忧之后,考虑到既有重试存在重新分析和延迟开销,可能对未来拓展的业务带来性能瓶颈,所以我们还是需要更进一步的去进行优化保证准实时性。于是,我们将目标指向了写入端。
我们写入端是通过 Canal 监听 MySQL binlog 写入 Kafka 让 Flink 进行批攒后进行写入操作:
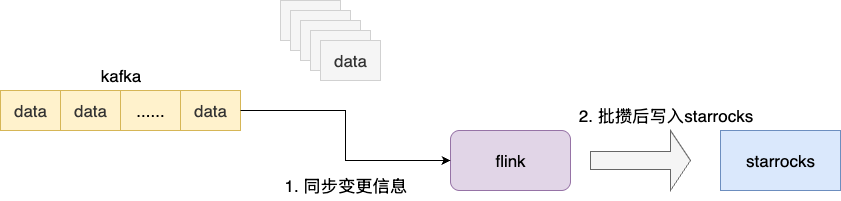
深入代码了解内部逻辑,我们就需要进一步了解为什么批攒的情况下还是会导致写入频繁。结合监控面板和代码逻辑,明确批攒在15000时触发写入,按照每分钟10w的量级,理论上批攒写入应该是控制在10次左右,但是grafana面板却出现50次左右。对此,进一步分析写入时的数据详情。
结合ELK的观测日志和 StarRocks 数据同步接口 Stream Load 的要求,我们最终定位到原因。由于 Stream Load 的 columns 参数要求单次请求中所有数据行必须包含相同的列集合,当批攒的数据来源于不同字段的变更操作时,必须按字段集合拆分为多个 Stream Load 请求。结合运维部一贯维稳将 MySQL 日志设置为 statement 级别的作风,笔者得出如下定论:
- 业务敏捷拓展,导致既有交易流水表涉及各种不同字段的插入和更新操作
- 运维部的同步组件只给出主键和变更列
- Flink 按照批攒时,对应15000条数据构建出多个请求
- 频繁写入,导致业务报表查询频繁报错
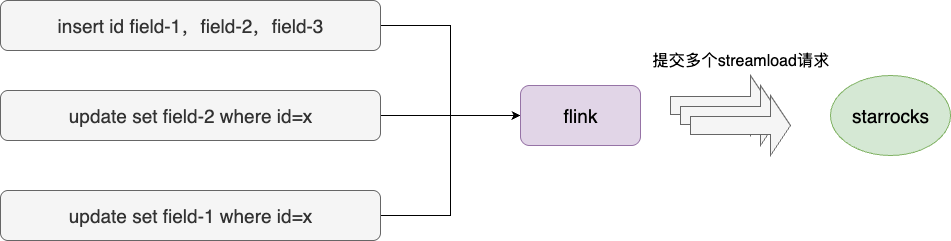
针对该问题,笔者的理念是在binlog同步段将字段打齐同步,当然,为了保证运维部所担忧的传输开销等资源占用问题,笔者提出监听slave rows数据的方式进行全列同步。由此,我们更进一步的降低写入的频率,随后我们稳步将参数进行缩小直至变为1,每日报错也仅偶发出现几次,于是将重试次数设置为3。
除此之外,因为写入由单接口即可完成,数据延迟这也有显著的降低。
# 版本升级
出于未来的考量,我们还是希望能够解决偶发重试的问题,结合starrocks社区和github的issues,我们发现在3.2的最高版本有一个分支修复了这个问题,它在plan阶段绕过执行计划的校验,仅校验schema这些变更:
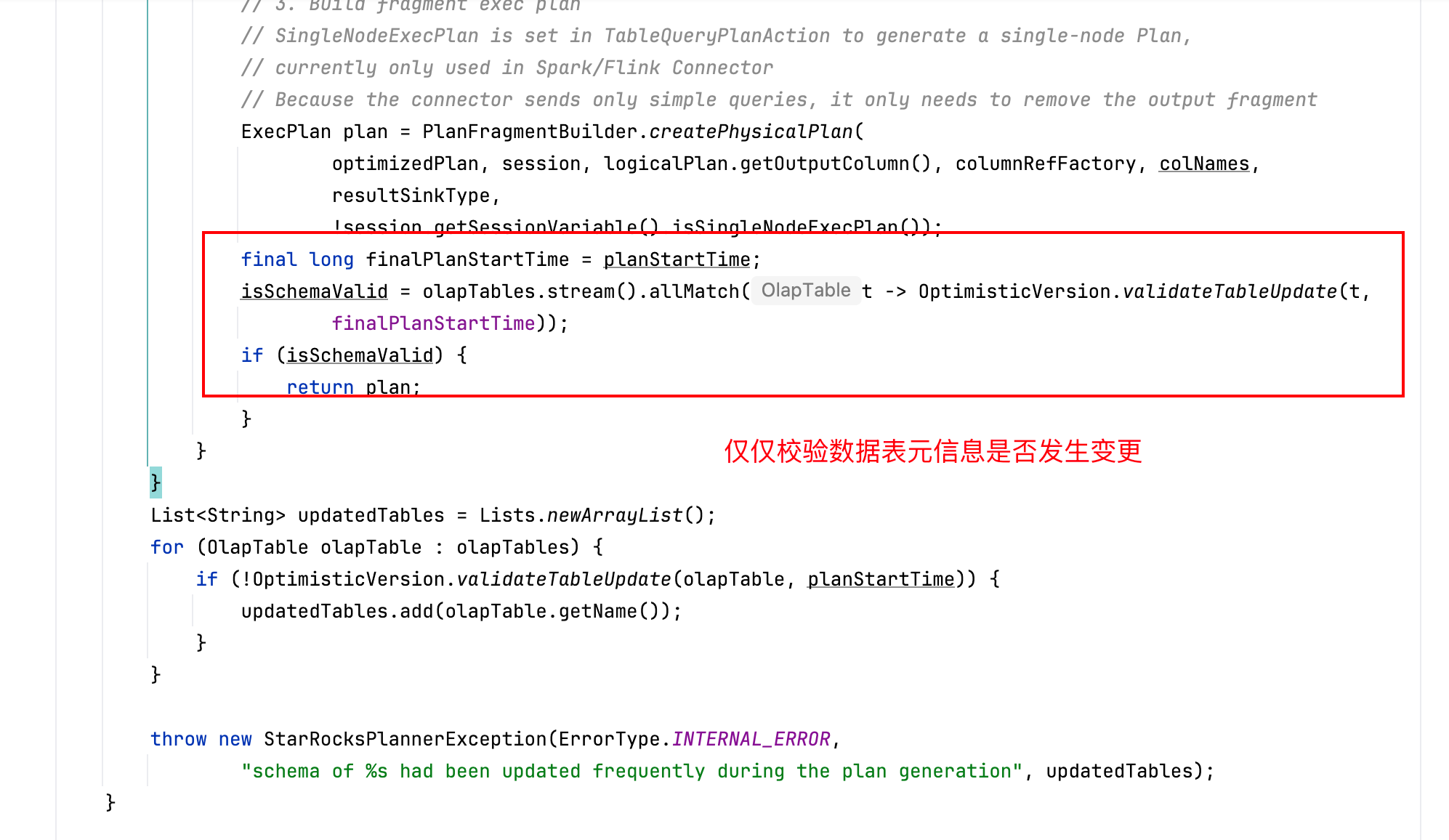
所以,在上述的一系列操作之后,我们构建一个备库搭建全新版本的数据库,并采用灰度的方式将部分流量移动到该库表下测试其查询稳定性。经过一段时间的运行后,除了一些SQL语法兼容性问题以外,不再出现查询报错。所以,我们最终将最新版本的库提上生产,并在一次深夜通过全量同步+离线补数和并调整flink偏移量完成订正,由此完成问题修复闭环。
# 线上验收结果
经过一个月的监控观测,我们完成的以下指标的推进:
- 经过一个月的监控观测,报表查询未再出现因 Plan 校验失败导致的报错,页面崩溃问题完全消除
- 意外收获:升级后 LIMIT 查询性能大幅提升,优化器支持先取 LIMIT 再关联
-- 查询交易流水表,关联支付参数表和客户信息表
-- 按交易时间降序、订单号降序排列,取前 10 条
SELECT t.column_list
FROM t_trade_detail t
LEFT JOIN t_pay_config pp ON t.order_no = pp.order_no
AND pp.created_time >= '20260106000000'
AND pp.created_time <= '20260106235959'
LEFT JOIN t_customer_info s ON t.cust_id = s.cust_id
WHERE t.trade_time >= '20260106000000'
AND t.trade_time <= '20260106235959'
AND t.status IN ('2')
ORDER BY t.trade_time DESC, t.order_no DESC
LIMIT 10
2
3
4
5
6
7
8
9
10
11
12
13
升级后优化器会先取出 LIMIT 结果再进行关联,避免全表关联后再截取:
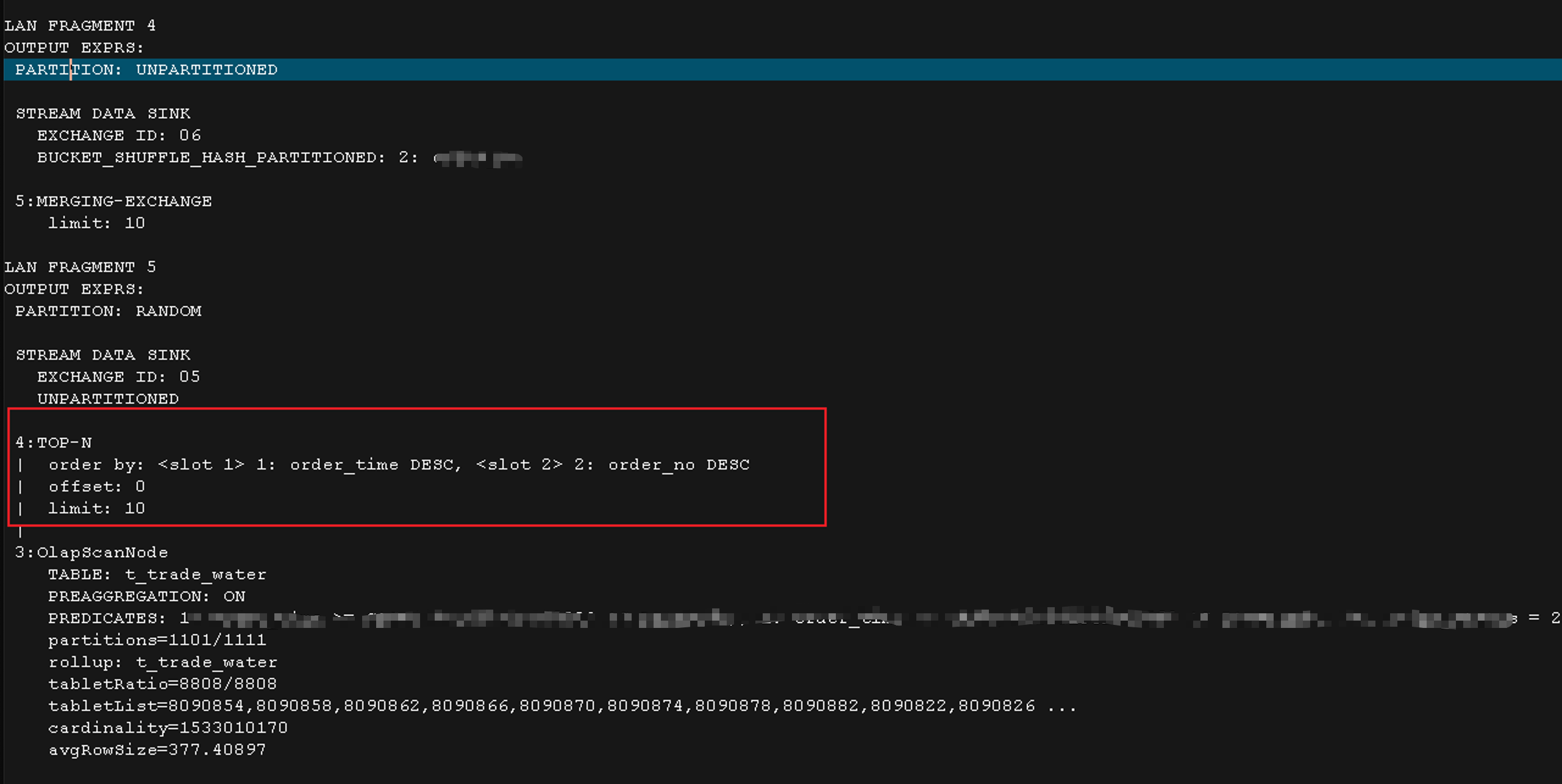
# 常见问题
# StarRocks 的 FE 和 BE 分别负责什么?查询 Plan 是在哪个节点生成的?
FE(Frontend)负责 SQL 解析、查询计划生成、元数据管理;BE(Backend)负责数据存储和查询执行。查询 Plan 在 FE 生成。
# 为什么写入会干扰查询 Plan?底层机制是什么?
StarRocks 的写入是通过发布版本(publish version)来实现的,每次写入会更新 tablet 的元数据。FE 在生成查询 Plan 时需要获取一致的版本快照,如果写入频繁导致版本持续变更,Plan 校验就会失败触发重试。
# 你们 StarRocks 的部署架构是怎样的?
3 FE(其中1个 Leader、2个 Follower)+ 3 BE,FE 负责查询计划和元数据管理,BE 负责数据存储和查询执行。
# 升级 3.x 版本有没有遇到兼容性问题?
系统层面没有太大问题,期间就是遇到一些官方优化后所导致的SQL语法兼容性问题,我们也都有在准生产环境稳步跟进
# 除了这个参数调优,StarRocks 还有哪些常见的查询优化手段?
- 物化视图、Colocate Group、分区裁剪、Bucket Shuffle Join 等。
# 复盘与总结
这是笔者在AI工具猛烈发展之前所遇到的一个问题,当然,读者也可以忽略这个背景。这篇文章笔者并没有过分去强调某个技术和原理,更着重去说明笔者如何推理思考既有问题的推理过程,如何基于信息拆解出子问题,然后去分析,再进行下一步决策,并结合风险评估维稳逐步推进,再完成验收。
SharkChili · 计算机路上的禅修者
开源贡献
- mini-redis:教学级 Redis 精简实现 · https://github.com/shark-ctrl/mini-redis
- Nightingale:深度源码研究
关注公众号,回复 【加群】 加入技术社群
# 参考
存算一体升级到3.1.6后 查询报错 The tablet write operation update metadata take a long time:https://forum.mirrorship.cn/t/topic/10579 (opens new window)
【3.1.10版本】查询报错The tablet write operation update metadata take a long time:https://forum.mirrorship.cn/t/topic/13976 (opens new window)
The tablet write operation update metadata take a long time:https://forum.mirrorship.cn/t/topic/13181 (opens new window)
starrocks:https://github.com/StarRocks/starrocks/tree/3.2.1 (opens new window)
FE 配置 - 用户管理、查询引擎和导入导出:https://docs.starrocks.io/zh/docs/administration/management/FE_parameters/user_query_loading/#max_query_retry_time (opens new window)
