 对账核销场景设计与重构实践
对账核销场景设计与重构实践
# 写在文章开头
近期一直在写一些AI相关的东西,遂与时俱进,但存量的知识储备总感觉有些不足,所以笔者还是本着复盘的想法,对个人近几年来的一些业务理解和设计进行必要的整理。通过自我梳理和反馈发现不足,并加以驱动完善。
也希望在这个浮躁的时代背景下,笔者的一些工作理念,会对你有所帮助。
SharkChili · 计算机路上的禅修者
开源贡献
- mini-redis:教学级 Redis 精简实现 · https://github.com/shark-ctrl/mini-redis
- Nightingale:深度源码研究
关注公众号,回复 【加群】 加入技术社群
# 业务背景和需求说明
为了让读者更直观了解业务,从而更准确地理解技术方案的思路和理念,笔者先交代一个业务背景。这是一个面向传统支付平台的系统,客户可通过商户POS机或者扫码的方式完成付款:
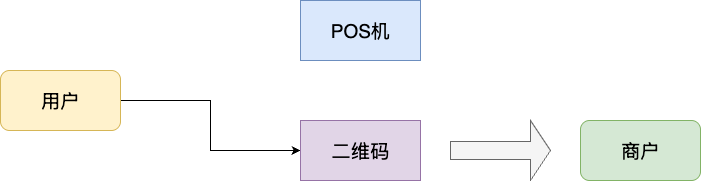
针对这一个完整的交易链,存在如下的利益关系:
- 服务商负责拓展商户完成机具投放维护等工作
- 商户基于这些机具和平台完成交易的管理
- 收单公司与服务商采用分润模式结算——即从每笔交易手续费中按比例分给服务商
如下图所示,一次完整的交易链,即服务商拓展商户之后,收单机构(也就是我们),赚取交易的毛利,并按照月结的方案分润给指定服务商:
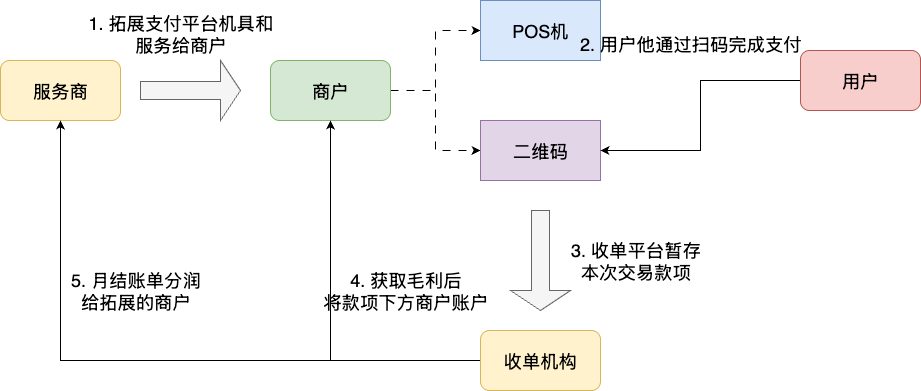
而本次的重构任务,则是针对服务商分润这一环节,即拓展商户后的分润结算部分的迁移和重构,不仅涉及平台、商户、服务商、财务、结算等多平台交互,还涉及新平台的核销规则维度的变更。核心变化在于核销算法的调整,具体要求如下:
- 核销维度由原有的A字段变为B字段,例如由原本的服务商名称改为服务商编号
- 核销严格要求账单和票据升序核销,例如:数据库存在3、4月份的票据,那么在核销时,必须先核销3月份的票据,再核销4月份的票据。
经过笔者初期对于数据体量的评估,大体可以推测存量的结算数据大约是千万级,所以在进行增量的核销前,我们需要完成存量数据的整理并按照新规则完成清洗核销,且保证核销结果最终的一致性:
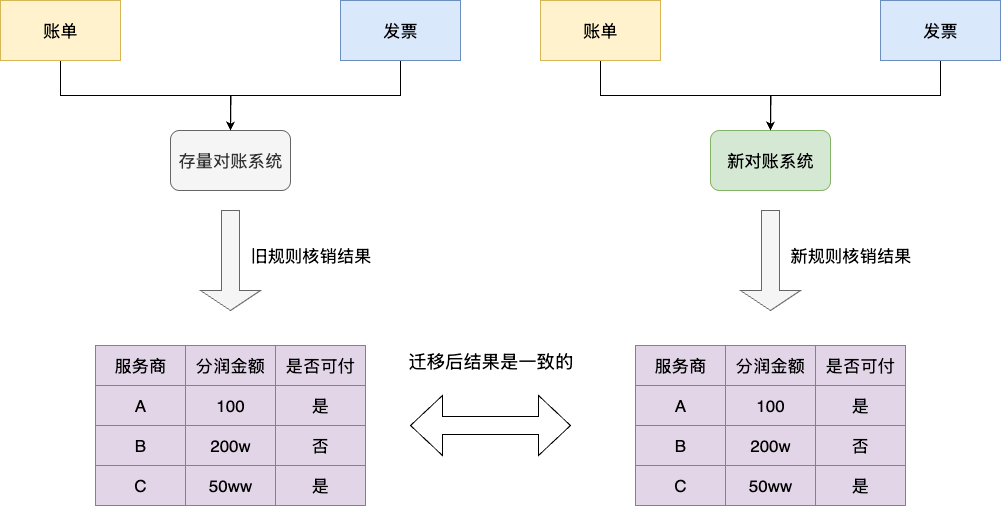
考虑到功能涉及比较重的交易,我们还是本着维稳的节奏将需求进行拆解,先通过准生产的方式完成存量数据清洗并按照新规则进行核销。按照试运行的节奏每日进行核对、调整,明确无误之后,再完成后续增量核销的步骤。
存量与增量的边界问题:存量核销执行期间(约10小时),增量业务也在持续产生数据,存在存量与增量同时操作同一笔账单的可能。对此,上游对接平台在切换时会重复给出一部分边界数据,我们在核销时会通过账单和发票编号判断是否存在历史核销记录,若已存在则直接跳过,以此保证幂等性。
# 存量对账的清洗与核销
# 宏观链路设计
考虑到无论是存量还是增量的账单,都存在核销规则上的交集,所以拆解之后的第一个开发版本周期可以完成业务的70%。
针对存量部分,笔者将其分为三个问题并进行分析和解决:
- 数据同步:初期历史账单和发票存储在旧有库表,无论是表结构还是核销规则完全不一致,且迁移过程涉及复杂的聚合查询,采用流式查询避免千万级数据内存溢出。
- 事务保障:核销涉及账单、发票、对账明细、税差、欠票5张表,将这些操作封装为原子事务,保证ACID。
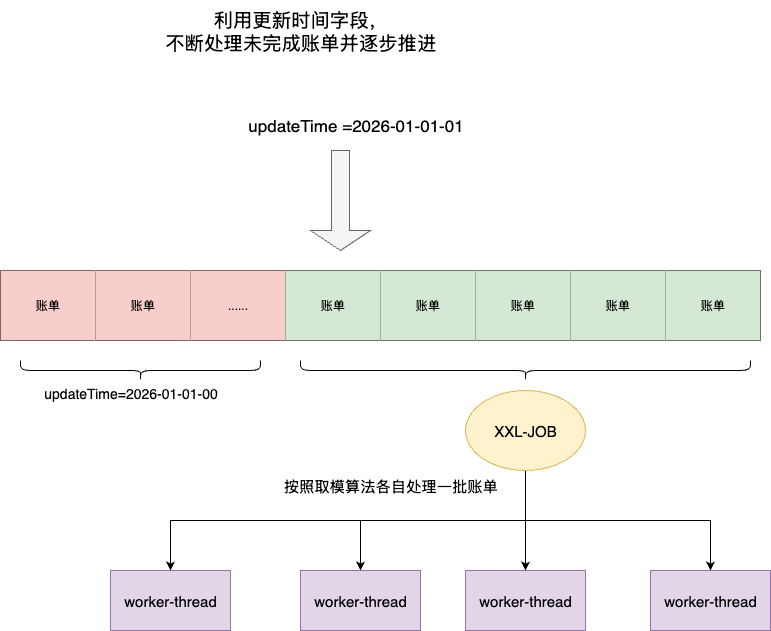
- 核销处理:考虑到业务体量和核销算法的可复用性,统一封装在分布式任务调度平台XXL-JOB上。且考虑到服务日常迭代的启停,为了保证一个涉及多核销动作的对账业务的原子性,我们将核销所涉及的账单扣减、状态更新、税差统计存放在一个事务注解下统一管控。
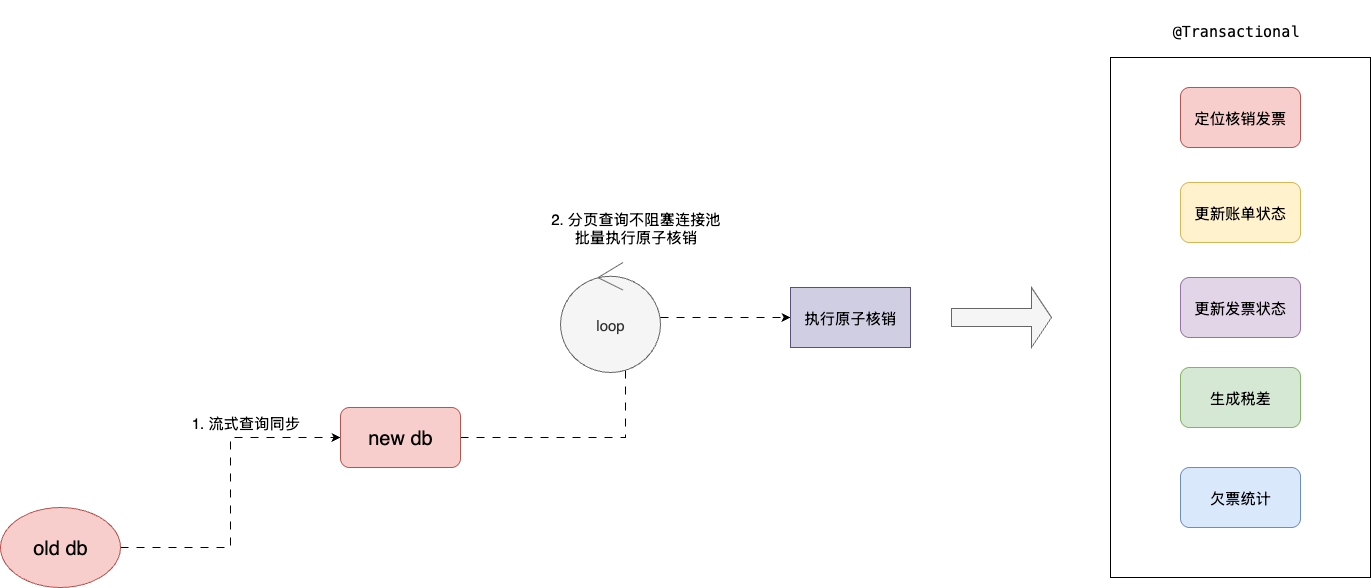
# 细节封装
在明确开发思路之后,我们需要针对技术细节进行梳理。整体分为两步:第一步通过流式查询将旧库数据清洗落库到新表;第二步从新表分页读取数据进行核销。按照团队一贯保守的风格,即为保证资源的维稳,此类非核心业务不允许使用长连接,这意味着清洗后的数据不能采用流式查询获取,所以我们只能采用分页查询的方式逐批次查询然后逐个原子账单进行核销。需要特别说明的是,后续性能优化中引入的多线程并发核销并不会产生竞态问题,因为每个线程都持有独立的分片键,各线程只处理属于自己分片范围内的数据,互不干扰。为了权衡性能和内存压力之间的取舍,笔者最终还是使用了如下方案:
- 设定本次循环的开始时间startTime
- 分页查询时间小于startTime的数据,按照存量数据就是所有数据
- 查询一批后逐条进行原子核销
- 完成后更新updateTime=startTime
- 如此往复,避免重复查询的同时,还能通过批次查询保证性能
# 性能优化
最后就是性能优化工作,通过上述的思路落地之后,发现存量核销存在如下问题:
- 原始方案逐条执行效率低,预估需3天
- 既有XXL-JOB集群数量有限,采用分片后,提升不大
经过整体的评估,发现单机资源尚有冗余,最终决定在非业务高峰期开启采用50线程并发进行并发处理每个批次的账单。需要说明的是,核销涉及的多表查询均已命中索引,单次查询响应非常高效,50线程并发下对数据库连接池的压力可控。同时,为了避免异步线程执行时日志信息在ELK链路丢失无法追踪,阅读zipkin源码后,通过withSpanInScope将主线程TraceContext透传到子线程
// 分片核销任务:按分片索引分批执行核销逻辑,避免单机全量处理导致性能瓶颈
// 利用 Tracer.SpanInScope 将当前分片任务纳入链路追踪,便于在监控系统中按 trace 查询核销进度
try (Tracer.SpanInScope ws = SpringUtil.getBean(Tracing.class).tracer().withSpanInScope(currentSpan)) {
log.info("当前分片: {} 总分片数: {}", shardIndex, shardTotal);
// 执行分片核销 - 账单核销
SpringUtil.getBean(BillVerificationService.class)
.processBillVerificationBySharding(shardIndex, shardTotal);
//......
} catch (Exception e) {
log.error("分片核销任务异常, shardIndex={}", shardIndex, e);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
最终效果:千万级数据10小时内完成,CPU负载控制在10%左右。线上实测观察到数据库idle time降低约5%,影响面在可接受范围内。
任务调度采用丢弃策略,5分钟执行一次,避免重复核销。
# 增量核销设计
# 痛点
在确保拆解后的存量功能维稳上线通过验收之后,我们就需要复用核销算法,将增量的线上实时业务引入。因为是增量场景,所以既有账单和发票存在如下问题:
- 发票状态需从业管部门实时同步,状态会动态变更,从而引发账单的核销、反核销以及部分核销的情况
- 除了用发票抵扣账单以外,增量的新业务支持打款等方式进行核销,需要一定的拓展性
- 多平台导入、修改存在状态并发变更,需保证对账的准确性和一致性
# 解决思路
所以,针对增量需求,笔者优先考虑将链路打齐,即将所有的状态变更都放到一个链路上,按照时间顺序先后变更。最终选择如下落地方案:
- 利用MySQL binlog的CDC模式,监听变更事件
- 通过日志驱动,串行获取对应账单、票据、打款,依次完成一个完整的核销动作
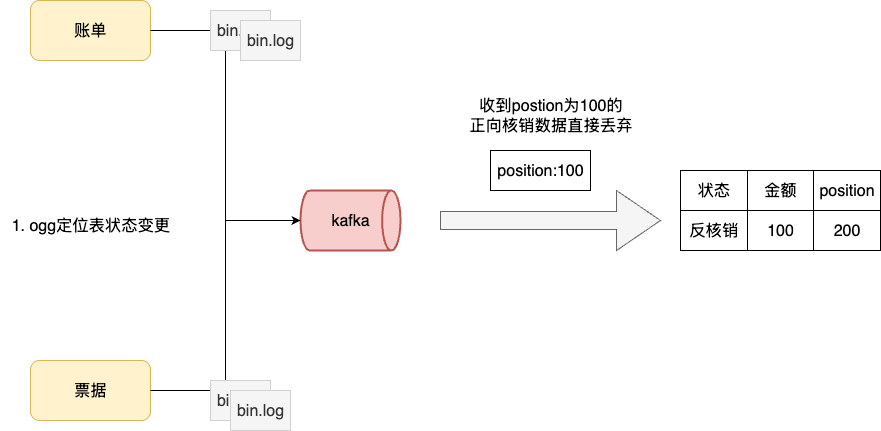
对于乱序消息,利用事件position感知这次状态变更是否过期,例如:因为网络波动、或者分区独立性等原因,原本的核销业务是先正常核销、后因为状态变更需要反核销。回放时出现先反核销再核销。
对此问题,笔者的思路是通过在业务数据上冗余一个偏移量字段判断消息的实时性,以上述例子为例,对应执行思路为:
- 业务上收到反核销时先查看对应票据是否被核销,发现没有,直接修改状态返回。
- 更新position字段为解析到的binlog值
- 收到正向核销时,发现position小于库表数据,判定为过期数据直接丢弃
# 代码实现
最终的实现代码如下,整体和上述一致,即通过一致性的binlog打齐链路并监听,结合偏移量进行有效消费完成原子核销:
@Component
public class IncrementalVerifyConsumer {
@Resource
private BillVerificationService billVerificationService;
@Resource
private InvoiceStatusService invoiceStatusService;
@Resource
private PaymentMatchService paymentMatchService;
/**
* 增量核销消费入口
* 监听Binlog变更事件,按时间线串行完成核销动作
*/
@XxlJob("incrementalVerifyJob")
public void consume() {
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList("bill-verify-topic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
records.forEach(record -> processChangeEvent(parseEvent(record)));
consumer.commitSync();
}
}
/**
* 处理单条状态变更事件
* 核心思路:通过binlog position判断消息时效性,丢弃过期事件
*/
private void processChangeEvent(BinlogChangeEvent event) {
// 1. 加锁保证同一业务单据串行处理(按主键Hash路由到同一分区后,消费端二次保障)
String lockKey = "verify:lock:" + event.getBizId();
try {
// 2. 获取当前业务数据的position
BillRecord currentRecord = billVerificationService.getByBizId(event.getBizId());
if (currentRecord == null) {
log.warn("业务单据不存在, bizId={}", event.getBizId());
return;
}
// 3. 【关键】通过position判断消息是否过期
if (event.getPosition() <= currentRecord.getBinlogPosition()) {
log.info("丢弃过期事件, eventPosition={}, currentPosition={}, bizId={}",
event.getPosition(), currentRecord.getBinlogPosition(), event.getBizId());
return;
}
// 4. 根据变更类型分发处理
switch (event.getChangeType()) {
case INVOICE_STATUS_CHANGED:
handleInvoiceChange(event, currentRecord);
break;
case PAYMENT_RECEIVED:
handlePaymentReceived(event, currentRecord);
break;
case INVOICE_REVERSED:
handleReverseVerify(event, currentRecord);
break;
default:
log.warn("未知变更类型, type={}", event.getChangeType());
}
} finally {
// release lock
}
}
/**
* 场景一:发票状态变更 → 触发正向核销
* 票据状态变为"可核销"时,匹配待核销账单完成抵扣
*/
private void handleInvoiceChange(BinlogChangeEvent event, BillRecord currentRecord) {
InvoiceInfo invoice = invoiceStatusService.getByInvoiceNo(event.getRefNo());
if ("VERIFIABLE".equals(invoice.getStatus())) {
// 执行正向核销:票据抵扣账单
billVerificationService.processBillVerificationBySharding(
currentRecord, invoice);
}
// 核销完成后,更新position为当前binlog位点
billVerificationService.updateBinlogPosition(
currentRecord.getBizId(), event.getPosition());
}
/**
* 场景二:打款到账 → 触发打款核销
* 增量业务支持打款方式核销,不依赖票据
*/
private void handlePaymentReceived(BinlogChangeEvent event, BillRecord currentRecord) {
PaymentRecord payment = paymentMatchService.getByPaymentNo(event.getRefNo());
// 匹配账单并核销
paymentMatchService.processArrearReconciliationBySharding(
currentRecord, payment);
billVerificationService.updateBinlogPosition(
currentRecord.getBizId(), event.getPosition());
}
/**
* 场景三:反核销处理(乱序核心场景)
*
* 乱序场景示例:
* 正常顺序: 正向核销(T1) → 状态变更触发反核销(T2)
* 乱序到达: 反核销(T2) 先到, 正向核销(T1) 后到
*
* 处理策略:
* 1. 收到反核销(T2) → 发现账单未被核销 → 直接修正状态返回
* 2. 收到正向核销(T1) → position < 库表position → 判定过期丢弃
*/
private void handleReverseVerify(BinlogChangeEvent event, BillRecord currentRecord) {
// 反核销前先检查:当前账单是否已被核销
if (!"VERIFIED".equals(currentRecord.getStatus())) {
// 账单未被核销,说明正向核销事件还没到(乱序场景)
// 直接将账单状态修正为最终状态,并更新position
log.info("反核销时账单未核销, 乱序场景, 直接修正状态, bizId={}, position={}",
currentRecord.getBizId(), event.getPosition());
billVerificationService.updateStatusAndPosition(
currentRecord.getBizId(),
"REVERSED", // 直接设为反核销状态
event.getPosition() // 更新position,后续到达的正向核销会被丢弃
);
return;
}
// 正常顺序:账单已核销,执行反核销逻辑
billVerificationService.reverseVerify(currentRecord);
billVerificationService.updateBinlogPosition(
currentRecord.getBizId(), event.getPosition());
}
/**
* 解析Binlog变更事件
*/
private BinlogChangeEvent parseEvent(ConsumerRecord<String, String> record) {
BinlogChangeEvent event = JSON.parseObject(record.value(), BinlogChangeEvent.class);
log.info("收到变更事件, bizId={}, type={}, position={}, offset={}",
event.getBizId(), event.getChangeType(), event.getPosition(), record.offset());
return event;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
# 报表统计的收尾
通过上述的设计,我们完成了存量和增量业务的迭代上线,最后需要在视图层做一些报表统计相关工作。按照业务反馈:
- 欠票统计涉及多张表聚合运算,数据体量持续增加,性能成为瓶颈
- 可付算法存在月份依赖规则:若服务商欠票超2个月,则所有欠票记录不可付
- 数据同步过程中可能因消费丢失或服务重启导致报表数据不一致
所以笔者解决思路如下:
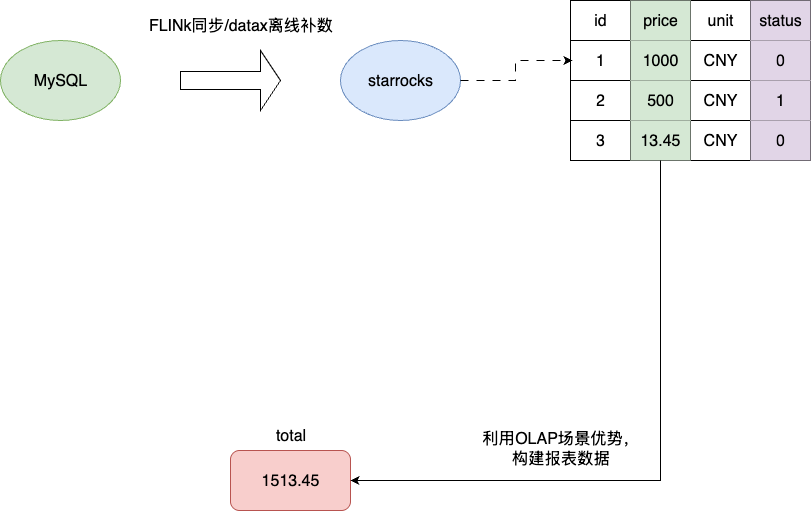
- 参考列式存储在OLAP场景的优势,结合公司技术栈引入StarRocks/ClickHouse
- 通过flink实时同步账单、发票、打款数据,支持实时统计
- 用离线补数,基于阿里DataX封装的离线同步平台调用完成数据订正
# 常见问题
# 为什么增量核销走binlog
该需求是要保证实时性和一致性,用rocketmq构建一个实时性的等待通知模型也是可以的,但是考虑该业务的一致性,如果由业务代码直接发消息,我们需要额外考虑:
- 异构事务的一致性:业务落库和发消息是两个动作,存在落库成功但发消息失败的可能
- 变更事件的完整性:业务代码只能覆盖已知的变更入口,如果有新的变更路径(如运维直接改库),就会遗漏事件
- 消息可靠性:需要额外保证每条变更都不遗漏
所以,使用binlog CDC模式(MySQL → Canal → Kafka → 消费端)监听变更事件,核心优势在于:binlog是数据库层面的变更日志,无论变更来自哪个入口都会被捕获,保证了变更事件的完整性。虽然中间仍然经过Kafka,但Kafka在这里只是传输介质,数据源头由binlog保证,不需要业务代码承担"不遗漏发消息"的职责。
# 为什么增量核销用XXL-JOB管理消费循环
读者可能会疑问:增量核销是一个常驻的Kafka消费循环,为什么不使用Spring Kafka的@KafkaListener注解来消费,而是放在XXL-JOB的调度任务里?实际上,@KafkaListener确实是更常见的常驻消费方式,但这里选用XXL-JOB统一管理,主要出于以下考虑:
- 调度策略的灵活性:业务上存在按时间段开启/关闭增量核销的需求(如月末结账期间暂停核销),通过XXL-JOB的控制台可以随时启停任务,而
@KafkaListener需要通过应用重启或动态开关来控制,运维成本更高。 - 统一的任务管理:存量核销和增量核销都注册在XXL-JOB上,便于在一个平台上统一监控任务状态、查看执行日志、配置告警规则。
- 资源隔离:将消费循环托管在XXL-JOB的独立线程中,可以与业务应用的主线程池隔离,避免Kafka消费线程占用业务线程资源。
# 数据清洗如何保证避免单机并发跑批的安全
初期进行数据清洗的时候,为了保证处理的可靠性我们将任务设置为4h跑一次,这其中就涉及跑批并发冲突的问题,为避免重复消费单笔核销数据,我们在调度策略和任务上都做了处理:
- 调度策略:每个任务在4h内只跑一次,调度策略选用最后一个,尽可能避免与其他任务造成过分的资源冲突
- 任务上做了处理:执行任务时,我们用Redisson设上一把分布式锁,确保清洗之后一个任务可以处理
# 乱序消息为什么用binlog position而不用时间戳
在增量核销中,判断消息是否过期是整个方案的核心。读者可能会问:为什么不直接用业务时间戳来比较,而是用 binlog position?主要有以下原因:
- 单调递增的确定性:binlog position 在同一个 MySQL 实例上是严格递增的,每一条变更事件都有唯一的位点。而业务时间戳来自不同服务器,受时钟同步、NTP偏差的影响,同一毫秒内可能存在多条变更,无法严格排序。
- 与消费模型一致:Kafka 自身的 offset 也是单调递增的,用 binlog position 判断过期与 Kafka 的消费语义天然对齐。如果用时间戳,还需要额外维护时间戳与 offset 的映射关系。
- 无需依赖外部时钟:position 完全由 MySQL 内部生成,不依赖应用层的时间戳字段,避免了业务代码遗漏更新时间戳导致误判的风险。
# 核销失败如何重试和补偿
核销作为涉及资金的操作,失败后的恢复机制至关重要。本文方案在存量和增量两个阶段分别采用了不同的补偿策略:
- 存量核销:由于是批处理模式,单条核销失败不会影响整批数据。失败的数据通过
updateTime不会被标记为已处理,下一次调度周期会重新拾取。同时,任务调度采用丢弃策略(5分钟一次),避免了重复调度的叠加执行。 - 增量核销:Kafka 消费端采用手动
commitSync,只有当前批次所有事件处理完成后才提交 offset。如果某条事件处理失败导致消费者重启,会从上次提交的 offset 重新消费,实现天然的重试。对于多次重试仍失败的事件,会记录到死信队列中,由人工介入处理。
# 为什么报表统计引入OLAP引擎而不直接用MySQL
报表统计涉及欠票、可付等多个维度的聚合运算,数据体量持续增长至千万级。为什么不直接在 MySQL 上做这些统计?
- 聚合查询的性能瓶颈:欠票统计需要关联账单、发票、打款、税差等多张表进行聚合运算,MySQL 作为行式存储,每次聚合都需要扫描大量数据行,在千万级数据量下响应时间会从秒级退化到分钟级。
- 不影响核心交易库:报表的复杂聚合查询如果直接打在交易库上,会与线上的核销、结算等核心操作争抢数据库资源,影响业务稳定性。引入 StarRocks/ClickHouse 将分析负载从交易库剥离,实现读写分离。
- 列式存储的天然优势:OLAP 场景通常只涉及少数几列的聚合运算,列式存储只需读取相关列的数据,I/O 量远小于行式存储的全行扫描,在聚合性能上有数量级的提升。
# 小结
本文以支付平台服务商分润结算为背景,完整梳理了一次对账核销系统的重构过程,核心思路可以总结为以下几点:
- 存量先行,增量跟进:面对千万级存量数据,采用"流式清洗落库 + 分页标位核销"的方案,通过分片键实现50线程安全并发,10小时内完成存量处理。
- CDC驱动,串行消费:增量核销通过binlog CDC模式捕获变更事件,利用binlog position解决乱序问题,保证核销的最终一致性。
- OLAP收尾,读写分离:报表统计引入StarRocks/ClickHouse,将聚合分析负载从核心交易库剥离,保证线上业务的稳定性。
当然,该方案也存在一些可以进一步优化的方向,例如:
- 增量核销中的分布式锁实现尚未给出完整代码,实际生产中需要结合Redisson等工具保证锁的可靠性。
- binlog position的跨文件比较问题,在MySQL主从切换场景下需要额外考虑GTID方案。
- 存量核销的分页标位方案在大批量并发下对数据库连接池的压力需要持续监控。
文章结束,希望对你有帮助。
你好,我是 SharkChili,禅与计算机程序设计艺术布道者,希望我的理念对您有所启发。
📝 我的公众号:写代码的SharkChili 在这里,我会分享技术干货、编程思考与开源项目实践。
🚀 我的开源项目:mini-redis 一个用于教学理解的 Redis 精简实现,欢迎 Star & Contribute: https://github.com/shark-ctrl/mini-redis (opens new window)
👥 欢迎加入读者群 关注公众号,回复 【加群】 即可获取联系方式,期待与你交流技术、共同成长!
- 01
- 记一次StarRocks源码级排错和既有架构优化实践05-13
- 02
- Windows 10 下的 Maven 安装配置教程05-11
- 03
- 基于 Claude Code 复刻 Redis 慢查询指令实践05-11
