 千万级交易流水慢查询综合治理实践
千万级交易流水慢查询综合治理实践
# 写在文章开头
SQL优化一直是传统web开发绕不开的话题,大部分人针对调优时总是针对索引优化这一角度探讨这个话题。实际上,无论是理性还是感性的角度,数据查询的优化并不聚焦于数据库底层工作机制的本身,在数据库以外的整个软件架构层面,也存在多种可优化的空间。
所以,笔者还是打算写这样一篇关于数据库以外的调优指南,针对以往的一个业务场景,从以下角度,逐步完成一个完整的慢查询优化:
- 问题定位与分析
- 索引优化
- 缓存预热关联
- 深分页查询优化
- 分页计数优化
- 增量字段打宽与业务规范制定
SharkChili · 计算机路上的禅修者
开源贡献
- mini-redis:教学级 Redis 精简实现 · https://github.com/shark-ctrl/mini-redis
- Nightingale:深度源码研究
关注公众号,回复 【加群】 加入技术社群
# 千万级交易流水深分页查询优化实践
# 背景说明
存量非报表BI大屏等查询还是基于传统关系型数据库进行查询,因为历史原因结合业务的敏捷迭代,核心的交易表查询涉及20张表的关联查询,字段差不多有八十几个,同时结合日均6000万笔的交易流水,即使通过一些结转的手段,和冷热备等手段,这张表在准实时的完整交易数据查询性能表现依然十分差劲:
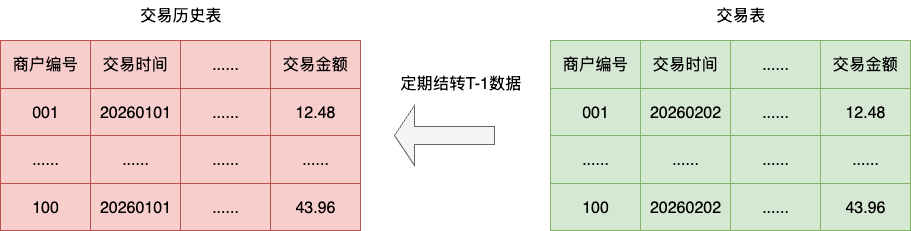
结合既有监控平台的分析和业务侧的反馈,以及对既有业务的发展趋势的推断,笔者还是打算针对该问题进行着重治理,以确保系统的稳定性。
需要强调说明的是,这篇文章整体思路是面向所有关系型数据库,包括但不限于 MySQL、Oracle 等,所以读者在阅读这篇文章时,更多是了解笔者分析和优化思路,而非拘泥于局部一个数据库技术栈使用,而这也是AI时代下我们需要提升的全局决策能力。
# 问题定位分析
明确对于问题的综合考量之后,笔者协同组内同事沟通后,非常快速的定位流水查询相关接口和实现,经过粗略的阅读分析并结合执行计划的综合推断后,我们大体得出初步的原因:
- 部分 LEFT JOIN 关联字段未命中索引,存在全表扫描
- 分页查询直接全表扫描,每日流水6000w笔,深分页大量超时
- 字段因为敏捷迭代的原因,并没有非常清晰的筛选,而是全量检索
- 增量业务也因为这些错误的规范,不断关联新的表,导致查询性能下降
SELECT
......
FROM
t_trade_record t -- 交易流水表
LEFT JOIN t_trade_pay_config pc ON -- 交易支付配置表
......
LEFT JOIN t_trade_settle ts ON -- 交易结算信息表
......
LEFT JOIN t_merchant_base mb ON -- 商户基本信息表
......
LEFT JOIN t_agent_org ao ON -- 代理商机构表
......
LEFT JOIN t_agent_org_rel a1 ON -- 代理商层级关系表(直归属)
......
LEFT JOIN t_agent_org_rel a2 ON -- 代理商层级关系表(顶归属)
......
LEFT JOIN t_pos_bind pb ON -- POS终端绑定表
......
LEFT JOIN t_device_model dm ON -- 设备型号表
......
LEFT JOIN t_terminal_brand tb ON -- 终端品牌表
......
LEFT JOIN t_bank_channel bc ON -- 银行通道信息表
......
LEFT JOIN t_sys_dict d1 ON -- 系统字典表(交易类型)
......
LEFT JOIN t_sys_dict d2 ON -- 系统字典表(交易状态)
......
WHERE
......
ORDER BY
t.trade_time DESC,
t.trade_no DESC
LIMIT offset, count;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# 详解千万级别慢查询综合治理步骤
# 方案说明
在经过初步的诊断和分析后,笔者最早的思路是协调所有服务负责人是否存在冗余字段打宽的可能性。经过技术评审和各个服务节点负责人评估之后,最终还是否决了该解决方案,原因如下:
- 涉及多处代码维护和状态机改动,存在遗漏风险
- 既有交易业务敏感且不接受存量的错误,不推荐这么大的改动
期间,笔者也尝试沟通过构建一张全新加宽的业务交易查询表,即使通过 binlog 结合 Flink 进行拼接同步,但整体还是可能存在某个服务节点异常导致数据不一致的风险,且后期离线订正风险也很大:
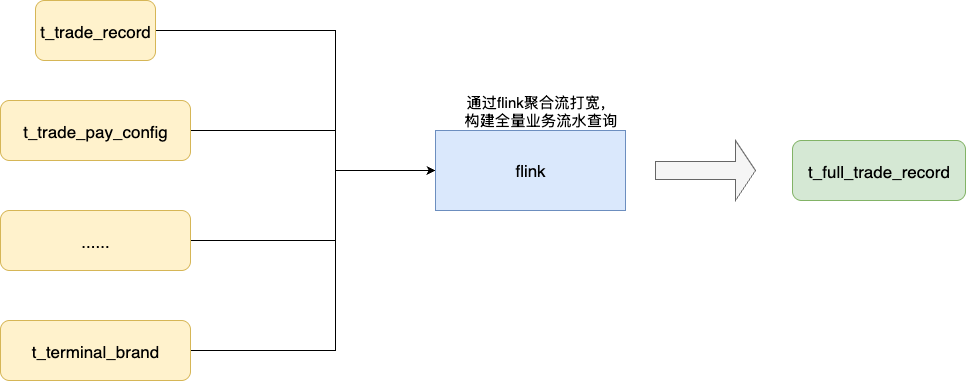
所以,本着业务维稳和最小化改动的综合考量,我们还是打算针对既有的查询接口进行专项整治。
# 索引优化
第一步我们优先还是考虑性价比亦或者说调优收益最大的索引优化,结合AI完成全链路分析,找到既有数据量大且关联不存在索引的表数据,协调所有关联侧同学针对既有关联字段加索引,确保进行关联查询时走索引(EXPLAIN 中 type 为 ref 及以上级别):
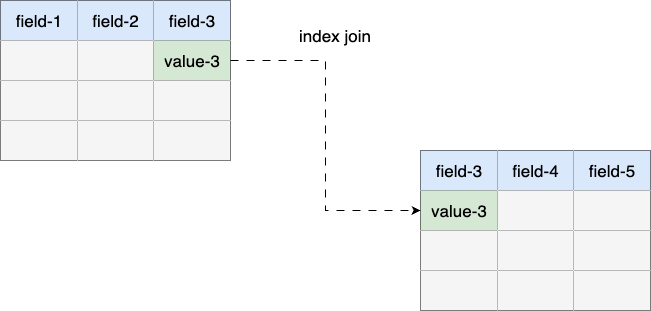
经过我们第一轮的优化,一次完整的交易业务流水信息查询,由原来的10s提升为6s,效果还是非常直观的。
# 缓存关联
在既有SQL上我们完成了第一轮优化之后,我们就需要针对查询进行下一个维度的优化,也就是拆。经过上一轮的分析,我们还发现了一些非必要的、耗时的关联语句可以拆分。例如:针对存量交易查询时,需要通过代理商编号获取所有三级代理商的层级关系信息
SELECT
t.trade_no,
t.trade_time,
t.trade_amount,
ao_lv1.agent_no AS lv1_agent_no,
ao_lv1.agent_name AS lv1_agent_name,
ao_lv2.agent_no AS lv2_agent_no,
ao_lv2.agent_name AS lv2_agent_name,
ao_lv3.agent_no AS lv3_agent_no,
ao_lv3.agent_name AS lv3_agent_name
FROM t_trade_record t
LEFT JOIN t_agent_org ao_lv3 ON t.agent_no = ao_lv3.agent_no
LEFT JOIN t_agent_org_rel r32 ON t.agent_no = r32.descendant_no AND r32.depth = 1
LEFT JOIN t_agent_org ao_lv2 ON r32.ancestor_no = ao_lv2.agent_no
LEFT JOIN t_agent_org_rel r21 ON r32.ancestor_no = r21.descendant_no AND r21.depth = 1
LEFT JOIN t_agent_org ao_lv1 ON r21.ancestor_no = ao_lv1.agent_no
WHERE t.trade_no = 'T20250101000001';
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
因为这些表需要到额外的大表进行关联后得到少量有效信息,再和流水表进行关联。经过笔者的评估,这些实际有效的关联数据,体量基本控制在千级别以内,所以,我们最终打算将这些数据通过服务启动时缓存预热加载,查询时在应用层通过内存拼接替代 LEFT JOIN。
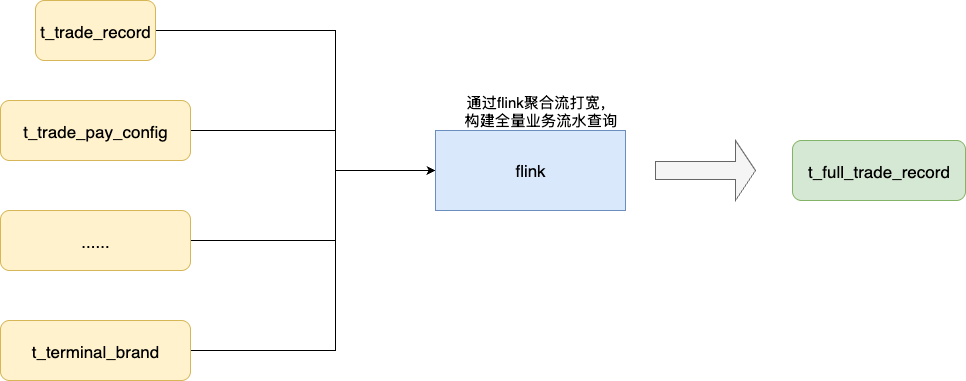
经过这一轮的调试,一次全量的业务交易流水查询速度提升到4~5s,效果还是很显著的。
需要补充的是,缓存预热方案在实际落地时需要考虑几个边界问题:代理商信息变更时缓存如何刷新(建议采用变更事件驱动的主动刷新,而非仅依赖定时刷新);未来数据增长到万级甚至十万级时对内存占用和启动时间的影响;多实例部署时的缓存一致性问题。在本场景中,由于关联数据体量控制在千级别以内且变更频率低,上述问题的影响可控。
# 深分页优化
明确单条 SQL 已经没有优化空间之后,开始着手深分页查询问题。核心思路是:先通过子查询在联合索引上完成筛选和分页(利用覆盖索引,只查主键 id,避免回表),然后通过 INNER JOIN 回表获取完整数据。
需要注意的是,覆盖索引生效的前提是子查询中 WHERE 的所有筛选字段 + ORDER BY 字段 + SELECT 字段(即 id)必须全部包含在同一个联合索引中。在本场景中,需要确保存在类似
(status, merchant_no, trade_time, trade_no)的联合索引(具体组合取决于实际的查询条件)。如果筛选条件组合不固定,可以考虑建立多个联合索引,或根据高频查询模式设计最合适的索引组合。
SELECT o.* FROM t_trade_record o
INNER JOIN (
SELECT id FROM t_trade_record
<where>
<if test="status != null and status != ''">
AND status = #{status}
</if>
<if test="merchantNo != null">
AND merchant_no = #{merchantNo}
</if>
<if test="startDate != null">
AND trade_time >= #{startDate}
</if>
<if test="endDate != null">
AND trade_time <= #{endDate}
</if>
</where>
ORDER BY trade_time DESC, trade_no DESC
LIMIT #{offset}, #{limit}
) tmp ON o.id = tmp.id
ORDER BY o.trade_time DESC, o.trade_no DESC
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
最终一次分页查询优化到 200ms 左右。
上述 SQL 仅为深分页优化的核心片段,仅对主表
t_trade_record做了延迟关联。在实际业务中,回表获取主表完整数据后,仍需 LEFT JOIN 其他表获取关联字段。但经过前两轮优化(索引优化 + 缓存预热替代部分 LEFT JOIN),剩余的 LEFT JOIN 关联数据量已大幅减少,对整体查询性能影响可控。完整的查询流程为:子查询筛选主键 → 主表回表 → 少量必要的 LEFT JOIN → 应用层内存拼接缓存数据。
# 分页计数优化
最后一个问题是 COUNT 查询,上述优化之后 COUNT 查询仍然会卡顿,运营反馈体验不好。结合当前业务架构给出两个方案:
- 通过 information_schema 获取近似行数(InnoDB 估算值,误差较大)
- 通过 Flink 同步到 StarRocks 的流水元表进行列式查询
了解到 StarRocks 已存在流水元表信息同步,延迟 5s 左右。协同运营沟通后确认 5s 延迟对业务 COUNT 影响不大,最终采用 StarRocks 方案。需要注意的是,information_schema 方案的根本局限在于无法按条件筛选,只能返回整张表的估算行数,而 StarRocks 的列式查询可以精确地完成带 WHERE 条件的 COUNT 统计,且性能优异:
<select id="countApproximate" resultType="java.lang.Long">
SELECT table_rows
FROM information_schema.tables
WHERE table_schema = DATABASE()
AND table_name = 't_trade_record'
</select>
2
3
4
5
6
注:以上为未采用的
information_schema兜底方案,其table_rows是 InnoDB 的估算值,误差可达 40%-50%,且无法按条件筛选,仅作为极端情况下的备选。最终线上采用 StarRocks 列式查询实现精确的条件 COUNT。
# 增量字段打宽
因为业务持续迭代,对于新增的字段维护比较方便,所以对于新业务的拓展,统一采用冗余打宽的方式维护到流水主表中,避免非必要的关联。
# 最终效果
| 指标 | 优化前 | 优化后 |
|---|---|---|
| 深分页查询 | 10s+ | 200-400ms |
| COUNT 查询 | 全表扫描,严重卡顿 | StarRocks 列式查询,毫秒级返回 |
# 小结
本文从一次千万级交易流水查询的实际性能问题出发,介绍了不局限于数据库底层的综合优化思路。整体优化路径为:索引优化(10s → 6s) → 缓存预热替代部分 LEFT JOIN(6s → 4~5s) → 深分页延迟关联(4~5s → 200ms) → COUNT 查询迁移至 StarRocks(毫秒级)。核心经验在于:数据库查询性能问题的治理不应只盯着 SQL 本身,而应从索引设计、应用层缓存、查询模式改造、甚至引入其他存储引擎等多个维度综合施策,在业务维稳和最小化改动的原则下逐步推进。
SharkChili · 计算机路上的禅修者
开源贡献
- mini-redis:教学级 Redis 精简实现 · https://github.com/shark-ctrl/mini-redis
- Nightingale:深度源码研究
关注公众号,回复 【加群】 加入技术社群
# 参考
MySQL LEFT JOIN 性能优化策略:https://mp.weixin.qq.com/s/FpDEPC3HRTFZI1tuZ2iETA (opens new window)
