 基于快照合并修复Seata AT回滚补偿与Flink批攒导致StarRocks数据不一致最佳实践
基于快照合并修复Seata AT回滚补偿与Flink批攒导致StarRocks数据不一致最佳实践
# 写在文章开头
针对既有场景设计和架构这个话题,一直是笔者近几年的工作课题,也一直想写,但是没有时间。还好,最近因为个人一些原因刚刚好需要针对这些场景进行一下复盘。而这篇文章正是基于上一篇starrocks架构优化前所遇到一个存量问题,即一个分布式架构下各个软件中间件局限性所导致的数据一致性问题。
同样的,这篇文章笔者不会过分深入代码细节,更着重去强调笔者的分析和解决思路,这也一直是AI时代背景下,笔者所一直强调的核心能力。
SharkChili · 计算机路上的禅修者
开源贡献
- mini-redis:教学级 Redis 精简实现 · https://github.com/shark-ctrl/mini-redis
- Nightingale:深度源码研究
关注公众号,回复 【加群】 加入技术社群
# 业务背景说明
因为需要进行一些聚合报表分析,某个新业务上线之后需要通过flink将数据同步至starrocks,出于对核心业务的可靠性的保证,团队通过"比数"监控平台监听异构同步库的数据量一致性来分析flink处理的一致性。该业务稳定运行一段时间,某段时间线上监控频繁出现数据不一致,结合业务侧的反馈报表平台存在大量脏数据:
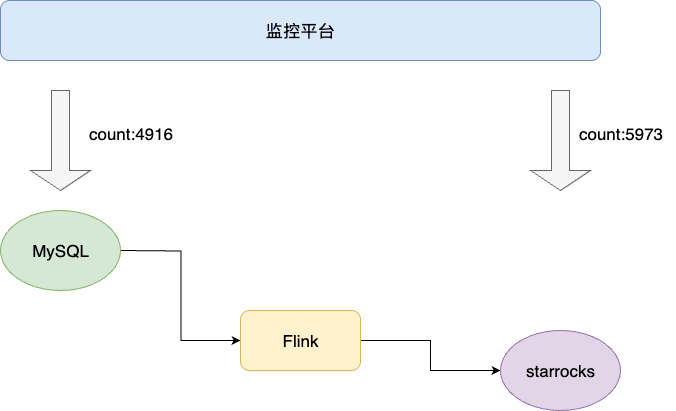
在基于前置可靠性通用排查后发现一条数据链路中kafka以及Flink数据都存在且都可靠消费后,我们就着重于在业务链路进行进一步的排查分析。
# 问题排查与修复方案
# 问题定位与根因分析
通过数据库离线比对我们定位到了几条问题数据,再通过kafka消息回放的方式我们发现这几条数据都是在毫秒级以内完成insert和delete操作。结合Flink job上的数据流算子,最终我们发现了问题。
出于设计理念上的考量,starrocks给自身定位就是需要基于同步流作为聚合报表分析的数据库。在当时的业务场景和表类型(非主键表)下,stream load仅支持批量数据upsert操作,删除需要通过jdbc完成。所以,这使得Flink算子在进行批攒和同步操作时,是通过两个动作实现。改造前的原始同步逻辑如下:
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
doExecuteData();
}
public void doExecuteData() throws SQLException, InterruptedException {
//jdbc删除
executeBatchDelete();
//stream load保存
executeBatch();
}
2
3
4
5
6
7
8
9
10
11
12
于是就导致本次问题的出现:在MySQL端正常插入后删除的语句,在单位时间内被Flink批攒后回放时,因为executeBatchDelete()先于executeBatch()执行,导致删除操作先于插入操作生效,最终starrocks多出一条源端已删除的数据:

结合相关数据流负责人的同事沟通后,笔者终于了解了问题的全貌。原来,这位同事最近上新了一个功能,为保证全局数据的一致性,这条相关数据被加入seata at模式和其他数据流统一管控治理。因为某些业务上的异常导致全局事务回滚,Seata在二阶段根据undo log执行反向补偿,使得这条数据在瞬时出现insert和补偿delete操作,最终被Flink批攒导致误插入。
之所以之前没有出现该问题,原因也很简单,存量业务的删除操作大部分都不是瞬时发生的,通常是先插入数据,经过一段时间后再因业务调整进行删除,亦或者通过标识的方式进行软删除。而本次业务因为seata的管控治理,并没有在业务上进行维稳控制,最终导致该问题的暴露。
# 快照合并方案的设计
明确事故问题和根因之后,我们就针对既有数据流进行改造,本质上该问题就是不应该插入的数据在事件回放时被插入了,所以笔者本着业务维稳的方式进行拓展修复,对应思路为:
- 在批攒期间增加一个缓存,key为数据id,value是一个列表,记录这条数据的事件类型和position位点,位点值越大则说明事务提交时间越靠后
- 执行同步前,遍历检查每个key对应的事件是否大于1,若大于1则说明存在瞬时存在多个SQL操作
- 判断delete事件position是否大于insert事件,若大于则将这条数据从待同步数据集中移除
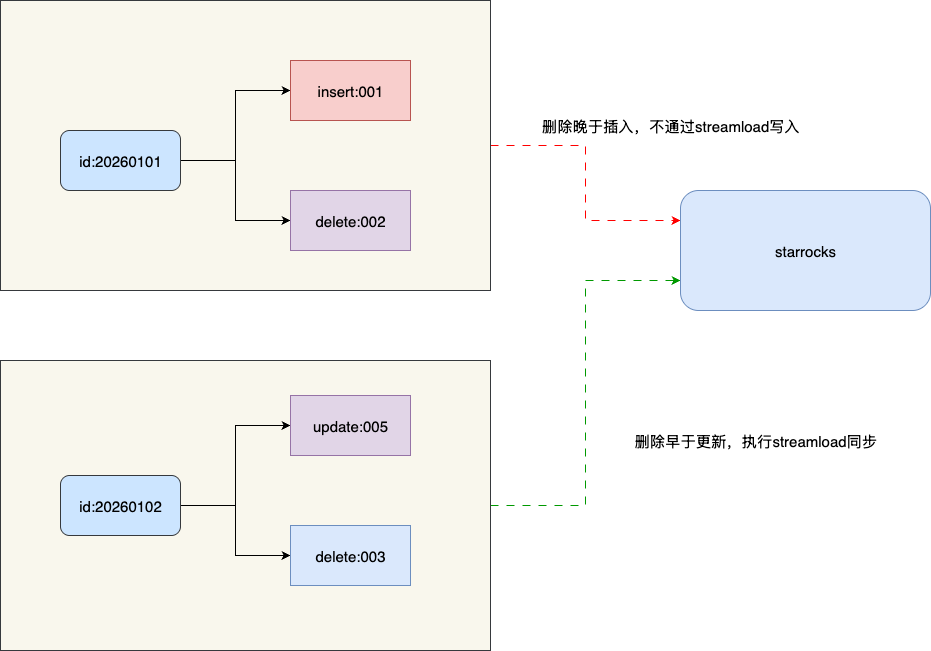
# 方案落地与验证
所以最终的做法还是要保证当前数据流不改动的情况下,在窗口内插入后秒删的数据集揪出来并剔除,于是就在同步窗口前的删除操作增加一个快照合并的逻辑,即每次进行同步检查删除操作中的数据集是否存在于更新或者插入数据集中,过滤出存在的,并比对position,将删除的position大于插入的从中剔除:
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
/**
* 根据配置决定是否进行快照合并,大体思路为:
* 1. 遍历删除的快照集
* 2. 查看插入操作中是否存在,如果有则判断删除的偏移量是否大于插入
* 3. 如果情况2返回true,则将快照清单中的删除、插入、更新(有插入大概率有更新,所以通用性加入处理)清理掉
* 4. 后续的同步只要判断是否存在于清单中,如果存在则直接同步写入到starrocks中
*/
deleteOffsetMap.entrySet().stream()
.filter(e -> (insertOffsetMap.containsKey(e.getKey()) &&
e.getValue() > insertOffsetMap.get(e.getKey())) ||
(updateOffsetMap.containsKey(e.getKey()) &&
e.getValue() > updateOffsetMap.get(e.getKey())))
.map(Map.Entry::getKey)
.collect(Collectors.toSet())
.forEach(k -> {
deleteOffsetMap.remove(k);
updateOffsetMap.remove(k);
insertOffsetMap.remove(k);
});
doExecuteData();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
完成代码改造之后,并在测试环境完成验收之后,考虑到该操作需要增加内存级别的批攒,期间我们针对堆内存gc情况和延迟都进行详尽的覆盖测试。因为这几种场景的数据表每分钟的数据量都不大,且我们同步的阈值都是基于监控指标采集到的阈值进行动态变更的(不会超过5M 不超过Region的大小,约1万条),所以不会导致堆内存飙升。
然后就是延迟方面,结合生产排查和观测情况来看一切良好,因为只是加了一层内存层面的过滤删除操作,且数据集都是采用设计良好的哈希集来存放,无论是定位还是删除效率都很高,耗时都是可以忽略不计的。甚至更进一步地说,我们减少了非必要的jdbc和streamload开销,同步效率甚至比以往更加出色。
明确业务一致性和压测验收都通过后,在从库跑了一个月后(主库期间采用离线订正方式先顶着),主库完成升级并通过业务一致性验收,正式解决问题。
# 常见问题
# Flink Checkpoint 机制
定期为流处理任务中的所有算子状态创建全局一致的快照,并将这些快照持久化存储到外部系统(如 HDFS、S3 等)。其核心机制基于 Chandy-Lamport 分布式快照算法,通过在数据流中注入 Barrier(屏障)将数据流切分为 Barrier 前后的记录,算子收到所有上游 Barrier 后触发状态快照,当所有 Sink 算子完成快照后即完成一次 Checkpoint。
Source → Operator1 → Operator2 → Sink
↓ ↓ ↓ ↓
状态 1 状态 2 状态 3 状态 4
└────────┴───────────┴─────────┘
↓
Checkpoint 快照
↓
持久化存储 (HDFS/S3)
2
3
4
5
6
7
8
9
# At-Least-Once 与 Exactly-Once 语义
At-least-once(至少一次)
时间线:
T1: 收到订单 A,计数从 0 → 1 ✓
T2: 准备更新计数时,任务故障 ✗
T3: 任务恢复,从 checkpoint 恢复状态
T4: 重新消费订单 A,计数从 0 → 1 ✓
T5: 继续处理订单 B,计数从 1 → 2 ✓
最终结果:计数 = 2(但实际只有 2 个订单,看似正确)
但如果:
T1: 收到订单 A,计数 0 → 1 ✓
T2: 更新成功后故障 ✗
T3: 恢复后重新消费订单 A
T4: 计数 1 → 2(重复累加!)
最终结果:计数 = 3(错误!实际只有 2 个订单)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
Exactly-once(精确一次)
使用 checkpoint + 两阶段提交(2PC):
T1: Checkpoint 开始,注入 Barrier
T2: 收到订单 A,预处理(未提交)
T3: 所有算子对齐 Barrier,准备提交
T4: 两阶段提交确认,正式写入 MySQL
T5: Checkpoint 完成
故障恢复:
- 从 checkpoint 恢复,重放数据
- 通过 Checkpoint 协调 + 事务机制确保数据只被提交一次
- 跳过已处理的订单 A
最终结果:计数 = 2(正确!)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# Flink GC 调优实践
S0 S1 E O M CCS YGC YGCT FGC FGCT CGC CGCT GCT
0.00 100.00 71.28 35.74 85.20 75.08 243030 23660.875 0 0.000 79150 1719.807 25380.682
2
3
从GC日志来看,FGC(Full GC次数)为0,说明没有发生Full GC;老年代使用率(O)为35.74%,元空间使用率(M)为85.20%,均在合理范围内。Young GC次数较多(243030次),但总耗时约23660秒,单次Young GC平均耗时约0.097ms,属于正常水平。不过S1(Survivor 1)使用率达到100%,说明Survivor区偏小,存活对象可能直接晋升老年代,存在一定的优化空间。
针对上述情况,我们适当增大了年轻代的空间比例(调整-XX:NewRatio),同时增大Survivor区(调整-XX:SurvivorRatio),减少对象过早晋升老年代的情况:
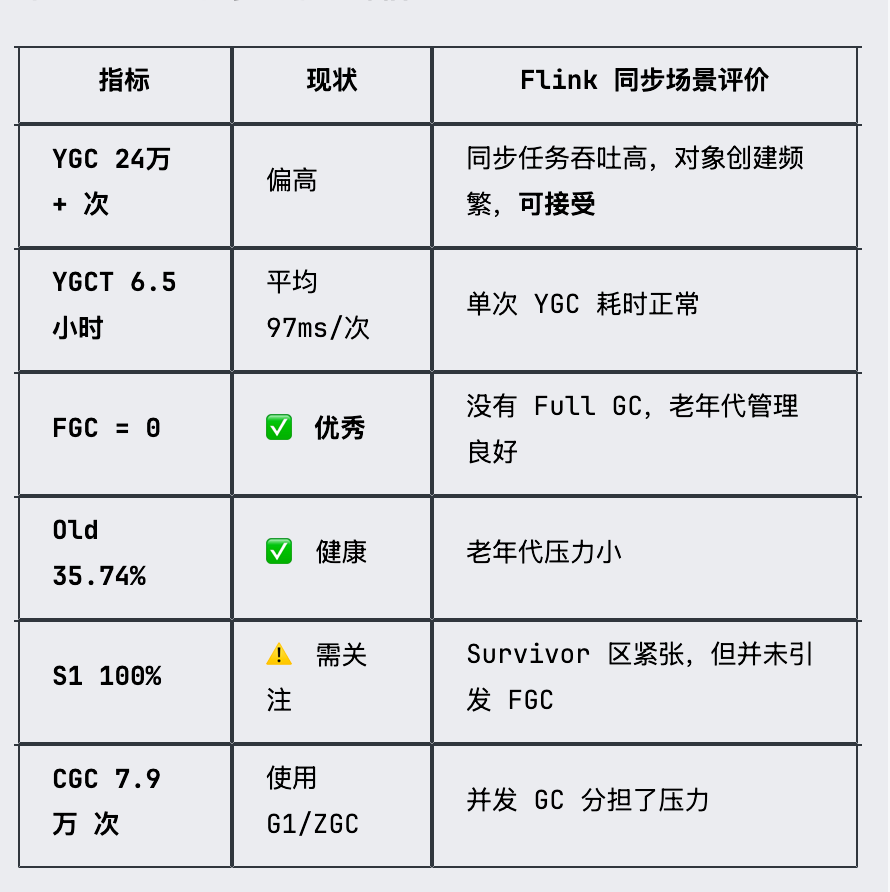
# 小结
本文是笔者近几年处理过的一些相对棘手的问题之一,因为涉及全链路的追踪排查,所以针对这种问题笔者排查思路永远是:
- 先针对组件可靠性角度出发看看是否存在严重缺陷,在明确没有严重问题无需进行止血之后。
- 我们再着重到业务层面进行代码推断分析,然后尝试复现,再将问题整理并协调资源进行进一步明确。
- 完成问题的闭环之后,再根据根因进行方案设计与落地。
- 稳步推进在测试环境针对逻辑和性能进行完整覆盖之后,推进上线。
可以看到,这篇文章笔者没有非常深入强调技术细节,而是出于架构层面考量进行思考、决策、落地,也希望对大家架构层面上的认知有所帮助。
SharkChili · 计算机路上的禅修者
开源贡献
- mini-redis:教学级 Redis 精简实现 · https://github.com/shark-ctrl/mini-redis
- Nightingale:深度源码研究
关注公众号,回复 【加群】 加入技术社群
# 参考
- Seata AT 模式官方文档:https://seata.apache.org/docs/dev/mode/at-mode/ (opens new window)
- StarRocks Flink Connector 官方文档:https://docs.starrocks.io/docs/integrations/streaming/flink/ (opens new window)
- 通过导入实现数据变更:https://docs.starrocks.io/zh/docs/loading/Load_to_Primary_Key_tables/ (opens new window)
- Stateful Stream Processing:https://nightlies.apache.org/flink/flink-docs-master/docs/concepts/stateful-stream-processing/ (opens new window)
