 AI时代的Go语言基础语法认知
AI时代的Go语言基础语法认知
# 写在文章开头
这是笔者很早写的一篇文章,刚好近期在帮助guide哥整理Go语言面试相关的知识点,于是也对这篇文章进行进一步的整理和复盘。
笔者认为在AI时代下,对于初学者而言,我们可以适当降低对于编程语言语法学习的比重,毕竟经过大量语料训练的模型,基本不会出现一些语法表达上的错误。我们更多的应该是是学会建立语言的认知框架。
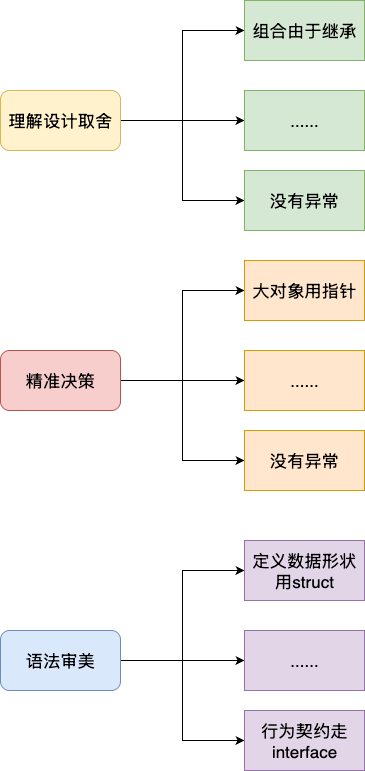
能够从以下角度思考比使用AI工具完成研发工作:
- 理解设计取舍:了解Go为什么这样设计
- 完成工程决策:将语法表达交给AI,开发者着重于在适当场景给出,编码细节上的决策,例如:什么时候用值?什么使用使用指针
- 建立编程审美能力:AI时代弱化了开发者编码的比重,但软件开发毕竟是一个长期的工程,建立代码审美能力依然很重要,例如:GO鼓励小函数、不提倡过度封装层层继承等,这些都是决定开发者在AI时代下能够高效写出易于维护系统的关键:
SharkChili · 禅与计算机程序设计的艺术
开源贡献
- mini-redis:教学级 Redis 精简实现 · https://github.com/shark-ctrl/mini-redis
关注公众号,回复 【加群】 加入技术社群
# 第一行go代码
以下面这段代码为例,我们介绍一下Go语言的编码基本套路:
1. 指明运行文件的包为main: Go用包来组织代码,同一个包属于同一个编译单元
2. 导入fmt包: 因为我们要输出语句,所以需要导入fmt包(即format包),这一点与Java不同,Go本着代码简洁的原则,不允许任何多余的信息,一旦导入没有用到的包,Go语言则会编译报错
3. main函数: Go的main函数不接收任何参数也没有任何返回值,这一切都是本着简洁的原则
对应第一行代码示例如下:
// 文件中所有其余代码都属于main包
package main
//导入包
import "fmt"
// main方法,程序运行的入口
func main() {
//用fmt包的Println输出一段话
fmt.Println("hello world")
}
2
3
4
5
6
7
8
9
10
11
12
完成上述编码之后,我们通过go run main.go运行程序,即可在终端上得到打印的输出语句:

# 命令行入参
我们再来展开说明一下Go语言为什么,没有main函数没有任何的出入参:
- 标准化原则: 语言只负责负责计算和逻辑处理上的事情,一切外部介质的读写操作都应该交由标准库执行
- 避免非必要的异常:
- 职责分离:C函数需要显示return 0,这使得main方法承载太多标准程序应该关心的事情
总的来说,Go语言的理念,就是摈弃一些非必要的仪式感做到简洁和标准化,对应我们也给出命令行入参的处理代码示例,如下所示,默认情况下GO语言索引0是程序名,1参数我们的参数:
import (
"fmt"
"os"
)
func main() {
fmt.Println("程序名:", os.Args[0])
fmt.Println("参数列表:", os.Args[1:])
}
2
3
4
5
6
7
8
9
10
输出结果如下:

# 工具类的使用
可以看到当我们需要用到相应的工具就得导入对应的包,然后通过包名.函数即完成调用。以下面这段代码为例,我们希望打印出2.6向下取整和hello go转大写的字符串,那么我们就需要依次导入:
- fmt包。
- 数学相关的math包。
- 字符串操作的strings包(这里我们用
ToUpper将字符串转为大写)。
所以我们的导入包的语法格式如下:
package main
import (
"fmt"
"math"
"strings"
)
func main() {
//向下取整,math.Floor返回float64类型
fmt.Println(math.Floor(2.6))
//字符串转大写
fmt.Println(strings.ToUpper("hello go"))
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
完成后我们运行程序,得到下面这段输出:
2
HELLO GO
2
# 变量扫盲
# 基本类型
对于任何一门编程语言来说,变量都会通过类型来决定内存分配和编译优化,Go语言也一样,总的来说,Go语言大抵有以下几种类型:
- 数字类型:
int、int8、int16、int32、int64、uint、uint8、uint16、uint32、uint64等,其中int为整型,后面跟着的数字代表位数,例如int8即8位(1个字节)的整型,而uint则无符号整型后面数字的含义一样,默认情况下int的字节数由平台决定,例如笔者使用的是64位架构的系统,那么int默认就是64/8即8个字节。 - 字符串类型:
string - 布尔类型:
bool - 复数类型:
complex64、complex128,complex64即复数类型,这有一些数学的概念,例如下面这段complex64即实部虚部都是32位浮点数,complex128即实部和虚部都是64位浮点数,左边为实部右边为虚部,这里我们就先简单介绍一下complex64:
// 使用复数类型 complex64
var z1 complex64 = 3 + 2i
fmt.Println("Complex number:", z1)
fmt.Println("Real part:", real(z1))
fmt.Println("Imaginary part:", imag(z1))
2
3
4
5
输出结果如下,可以看到打印出来的实部为3,虚部为2:
Complex number: (3+2i)
Real part: 3
Imaginary part: 2
2
3
4
再来看看complex128这个类型:
func main() {
// 使用复数类型 complex128
var z2 complex128 = 4 + 5i
fmt.Println("Complex number:", z2)
fmt.Println("Real part:", real(z2))
fmt.Println("Imaginary part:", imag(z2))
}
2
3
4
5
6
7
8
对应打印结果是一致的,只不过complex128是64位浮点数,精度更高一些:
Complex number: (4+5i)
Real part: 4
Imaginary part: 5
2
3
4
# 字面量与字符串
对于Go语言来说,描述字符的有字符串和字面量,而两者的区别是:
- 字面量在
Go语言中称为rune,是Unicode码点,即用数字表示字符的编码值,所以在打印时会输出对应的数字。 - 字符串声明时通过双引号包围,打印时直接输出字符串。
对此我们给出一段代码示例,最终常量输出位65,而字符串则原样输出:
func main() {
//打印字面量
fmt.Println('A')//65
//打印字符串
fmt.Println("A")//A
}
2
3
4
5
6
7
这一点我们也可以看到Go语言,由此可以看出Go语言默认rune本质上就是一个int32值,存储的则是unicode的码点:

# 获取变量的类型
Go语言的reflect包下提供各种反射的操作,其中TypeOf方法可返回变量类型,这种编写各种需要进行类型检查的高级场景中非常常见。
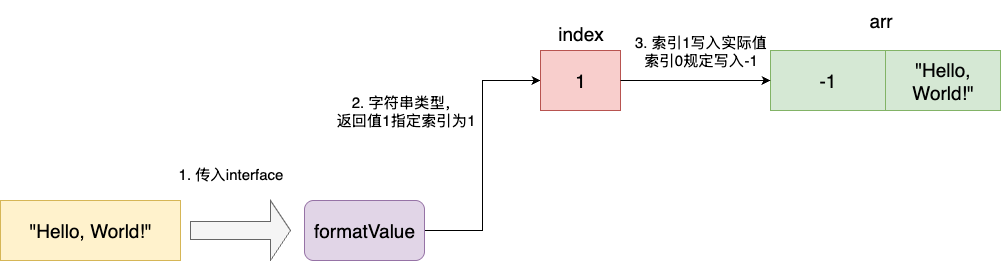
举个例子,我们现在需要将通过的interface按照原生类型进行转换,类型可能是字符串也可能是数字,对应我们的处理逻辑为,设定三个返回值:
- 返回值1决定取值空间,我们将后续两个返回值在逻辑上看做一个数组,数组0代表数字,数字1代表字符串
- 返回值2 记录转换后的数字,若非数字类型写入-1
- 返回值3写入字符串,若非字符串写入空串
如下图,我们传入字符串,对应返回值1写入索引1,返回值2为-1,返回值3为转换后的字符串:
对应转换代码如下:
/*
*
将interface类型进行格式化转换
返回值0:代表当前类型为数字类型
返回值1代表 字符串类型
返回值-1代表 类型转换失败
*/
func formatValue(v interface{}) (int, int, string) {
switch reflect.ValueOf(v).Kind() {
case reflect.Int: //整数类型,返回0,整数空间返回强转数字
return 0, v.(int), ""
case reflect.String://字符串类型,返回1,字符串空间返回原值
return 1, -1, v.(string)
default://其他类型,返回-1
return -1, 0, ""
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
输出结果如下:

# 变量赋值
Go语言对于变量的赋值比较灵活,这里笔者介绍一下最基本的赋值语法,通过var声明变量后,再用等号对变量进行赋值:
import (
"fmt"
)
func main() {
//声明变量
var num int
//赋值
num = 1
//使用
fmt.Println(num)
}
2
3
4
5
6
7
8
9
10
11
12
当然go也支持一次性声明多个变量再赋值:
import (
"fmt"
)
func main() {
//一次声明多变量
var num, num2 int
//赋值
num = 1
num2 = 2
//使用
fmt.Println(num, num2)
}
2
3
4
5
6
7
8
9
10
11
12
13
当然你也可以一次性声明多个变量在进行赋值操作:
import "fmt"
func main() {
//声明变量并赋值
var num = 1
fmt.Println(num)
var num2, num3 = 2, 3
fmt.Println(num2, num3)
}
2
3
4
5
6
7
8
9
上文笔者说过,Go之所以灵活是因为,在内部函数级别的变量声明时,可以直接通过:=进行初始化,让Go语言再编译时获取变量类型完成内存分配和优化的工作,这也是Go语言一贯的原则:让开发者少写,让编译器多做:
func main() {
//短变量声明一个int类型
num := 1
//打印值
fmt.Println(num)
//打印类型
fmt.Println(reflect.TypeOf(num))
}
2
3
4
5
6
7
8
9
对应的输出结果如下,可以看到对应类型打印是int,可以看出Go语言的短变量声明是非常简单且优雅的:
1
int
2
# 变量的默认值
go语言的变量默认有值的,例如数字默认为0,布尔默认为false,其他类型同理,这里笔者简单演示一下没有进行任何赋值操作的int和bool类型默认值的打印代码:
func main() {
//声明变量并赋值
var num int
fmt.Println(num)
var b1, b2 bool
fmt.Println(b1, b2)
}
2
3
4
5
6
7
可以看到结果和笔者说的一样,整型默认输出0,而bool默认为false:
0
false false
2
# 类型强转
与其他的编程语言(Java)有所不同,Go语言对不同的精度数字类型计算时不会进行自动的类型升级,所以在进行整数和小数的运算时,我们需要进行一下强转,强转的语法如下即类型(变量):
func main() {
//不同类型无法通过编译
length := 2
width := 3.2
//将length强转为float
lengthFloat := float64(length)
fmt.Println(lengthFloat * width)
}
2
3
4
5
6
7
8
9
最终得到正确的计算输出结果:
6.4
2
当然如果带小数的类型转为int时,还是需要考虑精度丢失问题,这里笔者就不输出演示了:
import "fmt"
func main() {
//强转精度丢失问题
width := 3.6
fmt.Println(int(width))
}
2
3
4
5
6
7
8
# 条件分支
# if语法
与Java和C这类编程语言不同,Go的if语句条件不需要加括号,直接在if后面带上条件即可:
func main() {
num := 8
if num < 0 {
fmt.Println("num < 0")
} else if num < 5 {
fmt.Println("num < 5")
} else {
fmt.Println("num > 5")
}
}
2
3
4
5
6
7
8
9
10
11
12
与之对应Go还有一个强大之处,Go语言支持在逻辑判断前加一个初始化语句,它无需像Java那样进行类型声明,这使得if表达式变得十分简洁和强大。
如下代码所示,我们希望根据函数是否存在异常判断是否执行成功,对应就可以在if语句前加一个逻辑处理并接收返回值,在通过err变量判断处理结果决定输出:
func main() {
//if判断前执行逻辑,在通过err判断是否执行
if res, err := doSomething(); err == nil {
fmt.Println("res:", res)
}
}
func doSomething() (int, error) {
return 1, nil
}
2
3
4
5
6
7
8
9
10
11
12
# switch判断
和其他编程语言不同的是,Go语言中switch是非常常用的判断,它时常和channel进行配合控制协程调度,这一点笔者会在后续的实际案例中演示,这里先介绍一下switch的语法格式,可以看到go语言的switch也是很清爽的,无需添加break即可完成分支:
func main() {
num := 3
switch num {
case 1:
fmt.Println("num = 1")
case 2:
fmt.Println("num = 2")
case 3:
fmt.Println("num = 3")
}
}
2
3
4
5
6
7
8
9
10
11
12
13
需要注意的是,Go的switch默认不穿透,这是一个 安全默认值的设计——C 的 switch 穿透是无数 bug 的来源,Go 直接改了默认行为。如果确实需要穿透,必须显式写 fallthrough ,让意图清晰,就像下面这样:
func main() {
num := 1
switch num {
case 1:
fmt.Println("匹配到1")
fallthrough
case 2:
fmt.Println("穿透到2")
fallthrough
case 3:
fmt.Println("穿透到3")
default:
fmt.Println("穿透到default")
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
输出结果如下:

# 循环分支
与其他语言相比Go语言没有while和do-while这种循环,取而代之的都是for循环,通过一个关键字衍生覆盖所有的循环场景,通过少即是多的设计,统一开发者认知框架,降低学习成本:
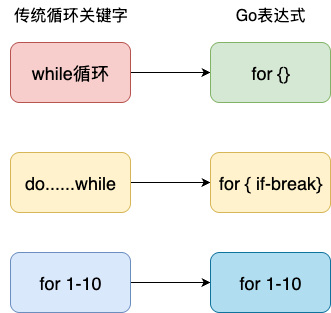
下面这个例子等同于while(i<10)这种编程习惯:
func main() {
i := 0
sum := 0
for i < 10 {
sum += i
i++
}
fmt.Println(sum)
}
2
3
4
5
6
7
8
9
10
11
对于那些习惯了Java或者C的开发来说,Go语言的无限循环语法可能会让你感到别扭,语言如下所示,即不带任何条件的for:
func main() {
for {
fmt.Println("无限循环")
}
}
2
3
4
5
6
7
唯一让读者感到亲切的应该就是下面这种fori格式的有界循环了,这里笔者就不多做赘述了:
func main() {
sum := 0
for i := 0; i < 10; i++ {
sum += i
}
fmt.Println(sum)
}
2
3
4
5
6
7
8
9
10
# 函数
# 基本语法
函数的基本语法如下,我们希望传入两个int的值得到一个返回int的函数,Go语言的语法格式如下:
func main() {
fmt.Println(add(1, 2))
}
func add(num1 int, num2 int) int {
c := num1 + num2
return c
}
2
3
4
5
6
7
8
不过有时候也可以这样写,看起来没有精简到哪里去,对于笔者而言这种语法基本很少用,读者了解一下即可:
func main() {
fmt.Println(add(1, 2))
}
func add(num1 int, num2 int) (c int) {
c = num1 + num2
return c
}
2
3
4
5
6
7
8
9
10
# 多返回值
多返回值算是Go语言让读者感到惊艳的地方了,很多编程语言为了得到多返回值,都会采用传入引用进行复制或者像C这种传入指针的操作,非常不优雅,与之相比,Go语言就比较方便了,只需用括号声明多返回值的列表,然后按需返回多个返回值即可:
func main() {
sum, str := add(1, 2)
fmt.Println(sum)
fmt.Println(str)
}
// add 返回int和string类型的函数
func add(num1 int, num2 int) (int, string) {
c := num1 + num2
return c, "计算成功"
}
2
3
4
5
6
7
8
9
10
11
12
对应的输出结果如下:
3
计算成功
2
3
# 函数与方法
与Java不同,Go语言是带有面向过程和面向对象等多种编程方式的语言,通过函数前是否带有接受者决定判断使用方式。
例如 Go语言的fmt.Println输出,则是采用面向过程式的函数,其函数定义就没有任何接受者:

使用方式也是通过包名.函数名即可:
func main() {
fmt.Println("Hello world")
}
2
3
4
而方法则是说明函数名前带有接收者,带有对象属性封装意味的一种编程风格,如下所示,一个专属于Person类型的sayHello方法:
import "fmt"
type Person struct {
Name string
}
func (p *Person) sayHello() {
fmt.Println("Hello my name is" + p.Name)
}
func main() {
p := &Person{"John"}
p.sayHello()
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
当然,从设计角度我们也很好理解这种语法的理念,它本质是将函数的入参提前到方法名前,通过这种简单的移动,将面向过程式的函数与面向对象式的封装隔离,以确保多编程方式的Go语言能够让开发者快速理解和运用:

# Go语言常见命令
一般情况下,我们现在编写Go语言程序都会采用Goland,通过点击界面运行指令,所以对于下面这些常见命令我们需要简单了解一下,便于后续在Linux上操作以及了解Goland的各个界面中提供的指令的含义:
1. go build 将源代码文件编译为二进制文件
2. go run 编译并运行程序,而不保存可执行文件
3. go fmt 使用GO标准格式重新格式化源文件
4. go version 显示当前Go版本号
2
3
4
# 小结
本文从零出发,快速梳理了Go语言的核心语法要素:
- 程序结构:Go以包为编译单元,
main包中的main函数是程序入口,编译器强制要求导入的包必须被使用,从机制上杜绝冗余代码。 - 变量体系:Go提供了完整的类型系统(整型、浮点、字符串、布尔、复数),支持
var声明和:=短变量声明,不同类型之间不会隐式转换,需要显式强转。 - 控制流:Go用
if、switch、for三个关键字覆盖所有分支与循环场景,去掉了while和do-while,switch默认不穿透,这些设计都体现了Go"少即是多"的理念。 - 函数设计:Go原生支持多返回值,通过接收者机制区分函数与方法,在同一种语言中兼顾面向过程和面向对象两种编程风格。
正如文章开头所说,学习一门语言的关键不在于死记语法,而在于理解其设计取舍——Go的简洁不是简陋,而是经过深思熟虑后的取舍。笔者会在后续的系列中继续深入Go语言各个常用包的源码级原理解析。
SharkChili · 禅与计算机程序设计的艺术
开源贡献
- mini-redis:教学级 Redis 精简实现 · https://github.com/shark-ctrl/mini-redis
关注公众号,回复 【加群】 加入技术社群
# 参考
Head First Go语言程序设计:https://book.douban.com/subject/35237045/ (opens new window) Go语言实战:https://book.douban.com/subject/27015617/ (opens new window)
- 01
- Go语言常见面试题解析(上)语言基础与核心概念05-20
- 03
- AI 写的企业级组件不敢用?我替你验过了05-19
