 AI时代不可替代的底层思维:位运算与逻辑运算实战
AI时代不可替代的底层思维:位运算与逻辑运算实战
# 写在文章开头
AI时代下笔者还是保持对于优秀理解学习和实践的习惯,这是从断墨寻径观后一直保持的个人理念,甚至可以说是既有知识学习的底限,即想象和观察可以刺激部分的神经细胞,最有效刺激学习神经元的方式是动手执行:

这篇文章是笔者在AI编程之前整理的一篇位运算的实践,因为近期接触到redis底层某些出色的理念,所以想着再次进阶并梳理一下这篇文章。关于位运算的学习,笔者也是深有感触,因为笔者的数学水平不是特别优秀,所以在早期学习位运算时,大部分是通过笔算、推导结合理论理清算法思路,在结合上下文分析设计优良并加以内化:
SharkChili · 禅与计算机程序设计的艺术
开源贡献
- mini-redis:教学级 Redis 精简实现 · https://github.com/shark-ctrl/mini-redis
关注公众号,回复 【加群】 加入技术社群
# 常见位运算技巧与实践
# 移位运算实现高效计算
移位运算从工作的角度来看就是直接将所有位置的数字简单移动x位,这个x就是我们要移动的位数,假设我们二进制数2,对应二进制就是0010,通过移位运算<<1得到的结果就是4,不难看出移位运算移动x位,就相当于乘2^x的数学运算,同理右移运算就相当于除法,这里就不多做赘述了:
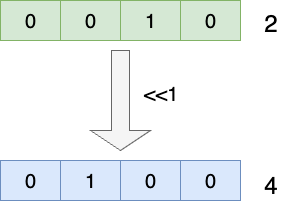
这种运算技巧笔者在线程池配置中是比较常用,例如我们需要配置一个IO密集型任务的线程池,对应的线程池最大数一般都是配置CPU核心数的2倍,而不同的服务器的CPU核心数不同,我们一般都是通过获取核心数然后进行乘2,此时我们完全就可以通过左移运算符完成这种逻辑运算:
@Bean("ioThreadPool")
public ThreadPoolExecutor ioThreadPool() {
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
Runtime.getRuntime().availableProcessors(),
//通过位运算计算线程池最大数
Runtime.getRuntime().availableProcessors()<<1,
60,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(200),
ThreadFactoryBuilder.create().setNamePrefix("worker-").build(),
new ThreadPoolExecutor.CallerRunsPolicy());
return threadPoolExecutor;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 按位与和移位运算实现时间区间判断
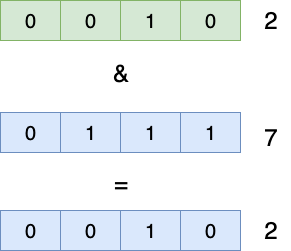
按位与运算只有两个bit都为1的情况下才为1,如下所示2和7的按位与运算,只有低2位的bit都是1,所以最终的与运算只保留这一位,最终的结果就是2:
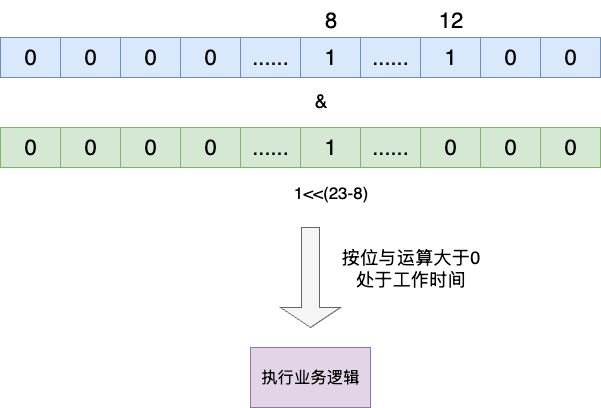
这里笔者给出一个比较经典的例子,假设我们的功能支持在8点到12点才能运行,我们希望能够判断当前时间是否是工作时间,这时候我们可以使用一个int的低24位做到这一点,我们使用24
个bit,自左向右为0~23点。
假设当前时间是8点,那么我们就可以自右向左将第8个bit设置为1,按照也就是自右向左的第16位,由此得出左移的位置为16,即需要左移15位也就是<<15,由此得出不同时间点的移动位数为1<<(23-当前时间),于是就有了下面这样一个按位与和移位运算的综合示例:
最终我们就有了下面这一段代码:
public static void main(String[] args) {
//时间二进制转整数
int timeBit = Integer.parseInt("000000001111100000000000", 2);
for (int i = 0; i < 23; i++) {
//当前时间
int curTimeBit = (1 << (23 - i));
//按位与
if ((curTimeBit & timeBit) > 0) {
log.info("{}:位于工作时间", i);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
对应输出结果如下:
22:37:34.599 [main] INFO com.sharkchili.Main - 8:位于工作时间
22:37:34.602 [main] INFO com.sharkchili.Main - 9:位于工作时间
22:37:34.602 [main] INFO com.sharkchili.Main - 10:位于工作时间
22:37:34.602 [main] INFO com.sharkchili.Main - 11:位于工作时间
22:37:34.602 [main] INFO com.sharkchili.Main - 12:位于工作时间
2
3
4
5
# 按位或实现多状态高效判断
在二进制运算之中,按位或运算只要是1个bit上为1,那么运算结果就为1,如下图所示,可以看到2的二进制数和1的二进制数的按位或运算结果就是3
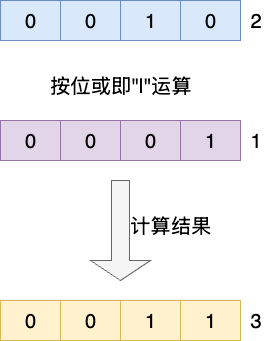
这一技巧在JDK6版本的FutureTask中的任务状态就有着非常经典的用法,当我们需要取消FutureTask执行时就会调用cancel方法,其内部的AQS队列会判断当前任务状态是否为运行完成RAN(值为2)或者已取消CANCELLED(值为4),如果符合其中一种情况则不允许取消任务。
按照我们常规的写法,最终的写法可能是这样:
//判断是否可以取消任务
private boolean ranOrCancelled(int state) {
//如果状态为运行完成或者取消则返回false,不允许当前线程打断任务
if (state == RAN || state == CANCELLED) {
return true;
}
return false;
}
2
3
4
5
6
7
8
但是Doug Lea不是这样做的,它用到了更加高效的位运算,接下来笔者就对此进行逐步推理:
- 由上文可知
RAN的值为2,CANCELLED的值为4,对应的是二进制的低二位。 - 通过或运算,将这两个状态的值拼接起来,构成
0110。 - 我们希望判断当前状态是否符合其中的一种情况,实际上就可以通过按位与运算,只要我们状态的二进制值和
0110相与大于0就说明符合其中某种状态
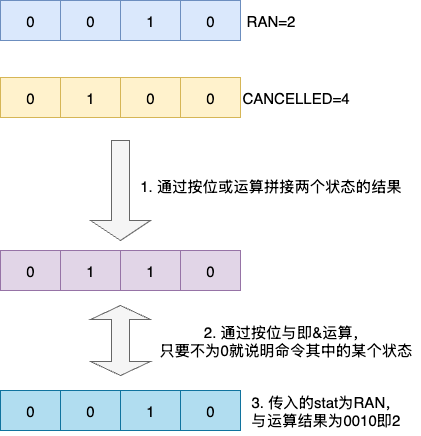
于是最终的位运算代码就变成了这样,可以看到作者先通过按位与拼接所有要判断的状态值,然后通过按位与判断是否符合其中一种情况,如果不为0说明命中某种状态,返回true:
private boolean ranOrCancelled(int state) {
return (state & (RAN | CANCELLED)) != 0;
}
2
3
# 逻辑或短路运算简化条件分支
逻辑或运算也是一个比较常用的运算符,它的工作原理是碰到一个运算结果为true则直接短路,不再进行后续的逻辑判断。
即if(表达式1||表达式2),如果表达式1为true,那么直接返回不再进行表达式2的计算。反之如果表达式1为false,则继续进行表达式2的计算:
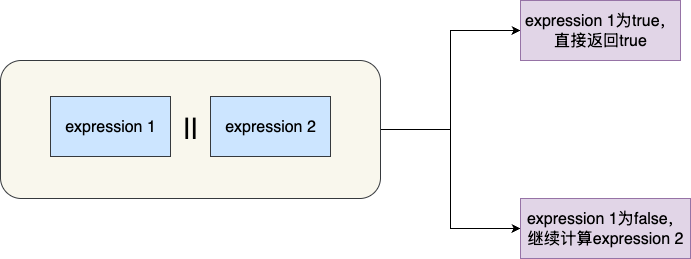
这其中最经典的使用场景就是ConcurrentSkipListMap的putIfAbsent逻辑,这个方法会判断当前key是否存在,如果不存在才进行put操作:
new ConcurrentSkipListMap<>().putIfAbsent("key", "value");
而putIfAbsent和put方法底层都复用了putVal方法,只不过putIfAbsent的onlyIfAbsent传的是true,而put是false,所以后者遇到相同的key会覆盖value。
于是当ConcurrentSkipListMap进行put操作时遇到相同key时,就会有这样的逻辑:
- 如果
onlyIfAbsent为false,说明是put操作,直接通过CAS原子操作覆盖掉value,如果失败则继续循环进行CAS操作。 - 如果
onlyIfAbsent为true,则说明则说明是putIfAbsent,不进行修改直接返回当前map中的value。
假设我们现在就需要编写这样一段逻辑,我们的写法可能是这样:
//如果设置空才允许插入则直接返回原值
if (onlyIfAbsent) {
@SuppressWarnings("unchecked") V vv = (V) v;
return vv;
} else if (n.casValue(v, value)) {//反之就是put逻辑,直接原子修改然后返回修改后的v的值
@SuppressWarnings("unchecked") V vv = (V) v;
return vv;
}
2
3
4
5
6
7
8
实际上这种看看第一段逻辑是否为true,若不为true则进行第二段的逻辑完全可以通过本小节所提及的逻辑或运算:
//如果onlyIfAbsent为true则说明只有key为空情况下才可赋值,不执行后续逻辑直接返回map中的vv
//反之进行原子操作然后将修改后的vv返回
if (onlyIfAbsent || n.casValue(v, value)) {
@SuppressWarnings("unchecked") V vv = (V)v;
return vv;
}
2
3
4
5
6
7
8
同理我们再给出这样一个例子演示一下笔者的重构思路,在著名的java度量框架micrometer中有一个非常实用的timer计时器,其底层有个时间窗口工具,它会并发传入最新的样本值sample和我们当前维护的原子类max进行比对,对应逻辑为:
- 如果
max大于sample,则直接返回 - 如果
max小于sample,则通过cas的方式将其修改为sample,因为可能涉及并发更新原子类,所以失败后就必须重新拉取原子类的最新值进行比对,明确sample依然大于这个值才能进行更新。
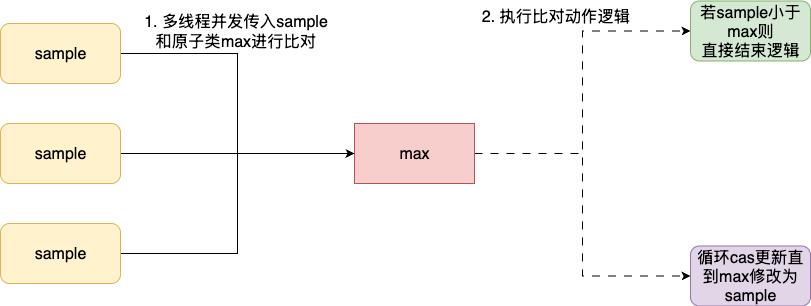
于是我们就可以编写出下面这样一段代码:
private void updateMax(AtomicLong max, long sample) {
long curMax = max.get();
//传入sample小于当前维护的原子类直接返回
if (curMax >= sample) {
return;
}
//sample大于当前维护的max则不断cas,若失败则比对再进行cas
for (; ; ) {
//cas成功则直接返回
if (max.compareAndSet(curMax, sample)) {
break;
}
//cas失败则重新获取max,进行比对
curMax = max.get();
if (curMax >= sample) {
break;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
我们先来第一步重构吧,review一下这段代码,可以发现代码稍显啰嗦,循环上下都涉及sample的比对,稍加思索,我们就可以发现将循环内部的sample比对逻辑移除,同时直接将循环上方的比对逻辑直接放到循环内部。
这样一来比对逻辑和循环cas并发更新都共享一段比对逻辑:
private void updateMax(AtomicLong max, long sample) {
//sample大于当前维护的max则不断cas,若失败则比对再进行cas
for (; ; ) {
long curMax = max.get();
//传入sample小于当前维护的原子类直接返回
if (curMax >= sample) {
break;
}
//cas成功则直接返回
if (max.compareAndSet(curMax, sample)) {
break;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
结合这段逻辑,我们发现这段逻辑本质上就是:
- 比对sample小于max直接结束,反之进入步骤2
- cas更新,若成功则结束循环,反之继续循环回到步骤1
这本质上就是通过短路运算符精简这段逻辑,确保比对逻辑可以复用的情况下,通过短路运算符保证将两端逻辑合并到一个if分支上,以简化代码:
private void updateMax(AtomicLong max, long sample) {
for (; ; ) {
long curMax = max.get();
//若sample小于max则直接短路结束循环,反之cas尝试更新max的值
if (curMax >= sample || max.compareAndSet(curMax, sample)) {
break;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
# 逻辑与短路运算实现条件守卫
和逻辑或有所不同,逻辑与运算必须两者都为true才能返回true,这意味着即使第一个表达式为true,第二个表达式依然会参与运算。反之如果第一个表达式为false,第二个表达式就没有计算的必要了:
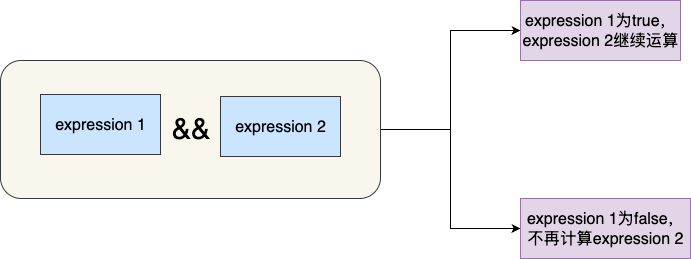
这其中比较经典的用法就是FutureTask源码中cancel方法的运用,它的逻辑是FutureTask状态必须为NEW的情况下,才能进行CAS状态修改,按照常规的写法,我们可能会这样写:
//如果状态为new
if (state==NEW){
//使用CAS将状态修改为中断态,如果失败则返回false
if (!UNSAFE.compareAndSwapInt(this, stateOffset, NEW,
mayInterruptIfRunning ? INTERRUPTING : CANCELLED)){
return false;
}
}
2
3
4
5
6
7
8
这明显这种if条件1为true,就执行条件2并查看条件2执行结果的逻辑进行后续逻辑处理的我们完全可以通过逻辑与运算替代:
if (!(state == NEW &&
UNSAFE.compareAndSwapInt(this, stateOffset, NEW,
mayInterruptIfRunning ? INTERRUPTING : CANCELLED)))
return false;
2
3
4
# Netty中按位与实现高效轮询索引
为了保证线程的公平调度,我们通常会采用轮询算法,假设我们有8个线程,按照轮询算法一次调用顺序为:线程0、线程1 ........线程7,然后才从线程0开始:
按照正常的写法,我们可以通过原子类进行递增,然后和线程数进行取模运算即可获取到当前事件通过那个线程执行:
假设我们的计算的值来到16,按照取模算法它对应的索引为0,此时新来一个事件需要线程处理,于是原子类原子自增1得到17,通过取模运算最终得到索引1:

对应的源码实现实现如下:
//原子子类记录当前索引值
private final AtomicLong idx = new AtomicLong();
@Override
public EventExecutor next() {
//idx自增和线程长度进行取模
return executors[(int) Math.abs(idx.getAndIncrement() % executors.length)];
}
2
3
4
5
6
7
8
取模运算的性能表现明显是没有位运算出色的,所以Netty提出了一种更加高效的方案,即当线程数为2的次幂时,通过原子类自增和线程数-1进行按位与运算。
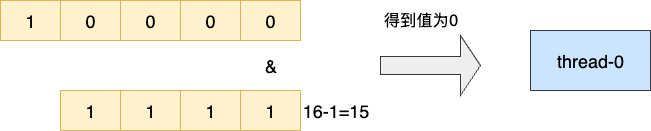
举个例子,假设当前索引值还是16,也就是的4次方,换算成2进制就是10000,然后2的次幂减去1即可得到小于2的次幂且低位全为1的二进制1111,这样一来我们idx无论怎么变化和这个减去1后的结果都会得到1个小于2的次幂,这个值永远小于等于线程索引。
所以索引16&15=0,当自增到17时得到的结果也很上文一样为1:
最终我们就得到了这样一个负载均衡算法:
@Override
public EventExecutor next() {
return executors[(int)(idx.getAndIncrement() & (executors.length - 1))];
}
2
3
4
# 进阶实践——Redis 二进制翻转算法
# 二进制翻转算法简介
该算法是笔者近期梳理redis scan源码时发现的一个优秀设计,即二进制翻转,也算是结合一些常见位运算的综合算法,该算法要实现的效果也很简单,就是将二进制完全反向翻转:
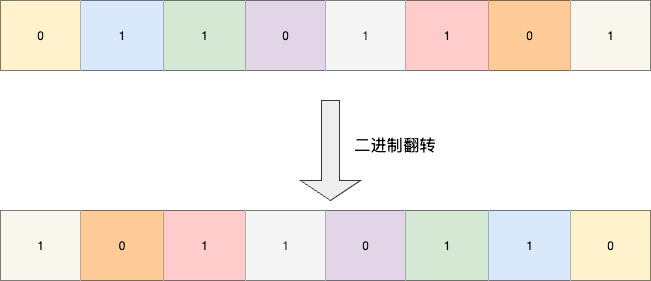
# 二分交换法原理推导
对于大部分Java开发而言,对于此类需求一般都会通过空间换时间的方式专门维护一个变量,从高位读取原二进制数值,完成二进制翻转。这也就是我们常说的朴素循环,该算法虽然也能够准确实现二进制翻转,但却在如下缺陷:
- 需要额外维护一份空间
- 翻转次数和数据大小有关,若是int则是32次,long类型则是64次
- 每一轮数据结构都依赖上一轮,且该算法是逐位推进,导致数据冒险链路变长
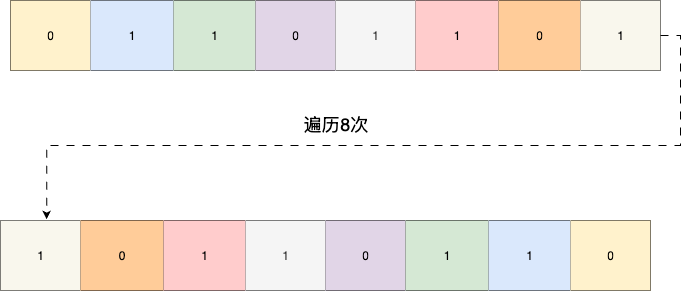
由此就有了我们要介绍的rev算法,该算法的工作原理本质就是一种二分交换法,通过二分思维减小上述算法循环次数,且避免了创建额外变量的开销,提升CPU缓存的局部性概率和执行效率:
原文地址:http://graphics.stanford.edu/~seander/bithacks.html#ReverseParallel (opens new window)

我们还是以上述二进制数0110 1101为例,演示一下翻转过程,假设这是一个8bit的整数,对应第一次翻转则是8/2也就是4位一个翻转,由此我们完成第一次翻转:
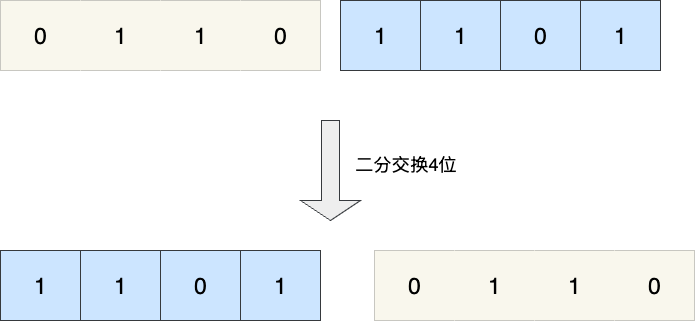
完成4位翻转后,翻转位数再除2,也就是二位一次翻转,一次类推,最终一位翻转,就构成完整的二进制翻转:
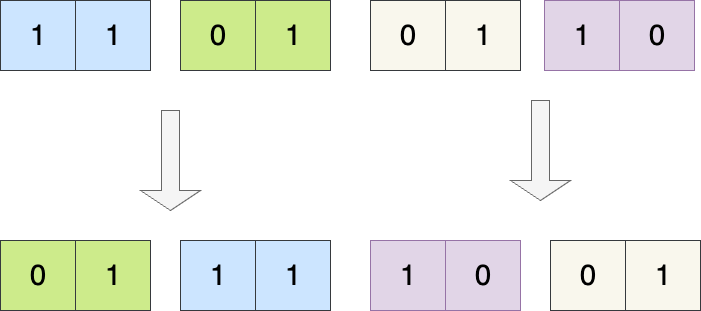
# rev 算法实现与逐行解析
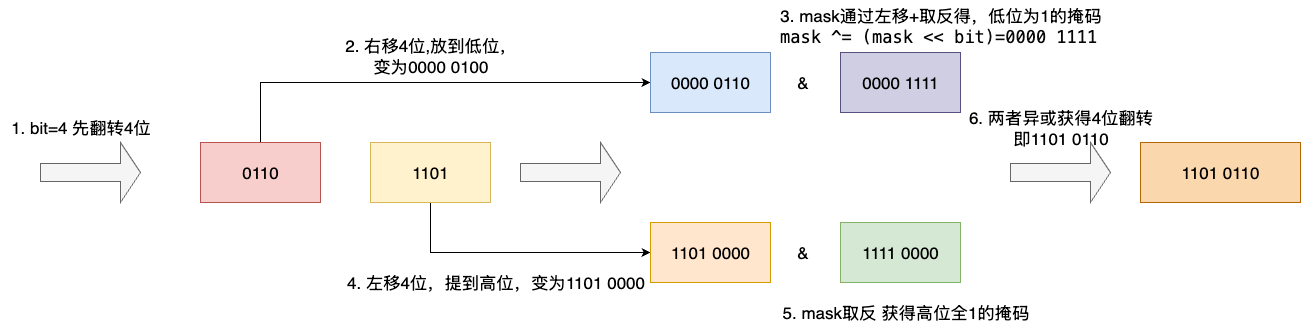
明确算法原理之后,我们就给出对应的代码实现,因为涉及比较多的位运算,所以看起来比较抽象,所以我们还是带入实际数据给读者说明一下,我们假设:
- 待翻转数值为0110 1101
- 数值对应bit为8
在代码层面的第一轮翻转过程为:
- bit除2得到4,也就是第一轮翻转4整位
- 高位0110通过右移放到低位,获得0000 0110
- 低位1101通过左移放到高位,获得1101 0000
- mask通过右移4位配合异或运算获得低位为1的掩码 0000 1111,和高位翻转后的0000 0110 进行按位与获得0000 0110
- 1101 0000 和mask取反后的值进行按位与,获得 1101 0000
- 二者按位或拼接,完成四位翻转 1101 0110
对应图解过程如下:
源代码如下,读者也可以结合注释了解算法的工作过程:
/**
* 反转64位long的每一位
* @param v
* @return
*/
public static long rev(long v) {
//获取long的位数,等价于C语言的 8 * sizeof(v),即64位
int bit = Long.SIZE;
//获得一个全1的掩码,例如:0000 0000 => 1111 1111
long mask = ~0L;
/**
* bit数不断除2,进行 bit位的循环反转,
* 假设bit为8 则本次位运算bit为4,进入循环处理
*/
while ((bit >>= 1) > 0) {
/**
* 左移位+异或,获得低位1 高位0的mask,
* 例如:传入1111 1111 对应的计算结果为:
* 1. mask << bit = 1111 1111 << 4 = 1111 0000
* 2. mask ^= 1111 0000 = 1111 1111 ^ 1111 0000 = 0000 1111
*/
mask ^= (mask << bit);
/**
* 完成bit位的翻转,例如:传入v 0110 1101 对应的计算结果为:
* 1. 将高位翻转到低位:(v >> bit) & mask = (0110 1101 >> 4) & 0000 1111 = 0000 1101 完成高4位翻转
* 2. 将低位翻转到高位:(v << bit) & ~mask = (0110 1101 << 4) & 1111 0000 = 1101 0000
* 3. 0000 1101 | 1111 0000 = 1111 1111
*/
v = ((v >> bit) & mask) | ((v << bit) & ~mask);
}
return v;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
测试用例和输出结果如下:
//测试用例:0x0123456789ABCDEFL 二进制模式清晰,便于验证反转结果
long v = 0x0123456789ABCDEFL;
System.out.println("反转前: " + toBinaryString(v));
long reversed = rev(v);
System.out.println("反转后: " + toBinaryString(reversed));
2
3
4
5

# 小结
在AI时代手写算法仍然是必要的,不必为此感到负担,我们需要理解核心思+少量实现经典范例,就像数学的微积分一样,将来你可能会通过已封装好的函数直接使用,但只有你自行推导和运算,才能真正理解,并精准的使用它。
记住,AI只是你的工具,而你脑中的算法直觉,才是决定你能走多远的核心能力。
SharkChili · 禅与计算机程序设计的艺术
开源贡献
- mini-redis:教学级 Redis 精简实现 · https://github.com/shark-ctrl/mini-redis
关注公众号,回复 【加群】 加入技术社群
# 参考
浅谈CPU流水线的艺术:https://mp.weixin.qq.com/s/7MegvNsPeVOW_ejUIg0lvw (opens new window)
从断墨寻径浅谈程序员的元学习能力 :https://mp.weixin.qq.com/s/ZoABDjQakJQDiigsOVBVMw (opens new window)
- 02
- 深入Redis SCAN源码:反向迭代算法的设计与实现06-01
- 03
- Go语言常见面试题解析(上)语言基础与核心概念05-20
