 AI时代视角下聊聊Go语言的编译过程
AI时代视角下聊聊Go语言的编译过程
# 写在文章开头
近期一直在梳理AI时代前,笔者写的一些文章,记得当时笔者本着效率和工作效率上的考量,对于知识密度的考量现在看来远远不够。
笔者认为AI时代下,对于编程语言的学习因弱化对于语法细节的比重,毕竟经过大量语料的训练的模型,基本不会出现语法表达的上的错误,这是不断在犯错的人类(尤其是没有智能IDE时代的时代)所无法做到的,所以AI时代下,我们应学会弱化这部分的工作的参与比重:
我们应着重在以下层面完成个人核心能力的升级:
- 设计决策:理解语言的本质,了解对于语言具体落地方式,例如:编写一个Go语言函数的时候,学会什么时候用值,什么时候用指针
- 原理分析:经过大量的优秀的语料分析,AI对于逻辑代码的编写是非常标准且规范的,但是它无法每时每刻帮你做到极致,即只能给你保证能用 ,对于性能上如果开发者没有一定的认知,无论多么出色模型,都会因为你的上限而受限制,例如:对于函数编写细节上的逃逸分析和GC压力推理分析
- 架构选择:AI可以非常高效帮我们完成编码的工作,对于系统的全局推理决策和未来的规划和人为的不可抗力因素是无法做到完美的权衡。所以,我们也要学会在架构设计上具备准确的技术选型和全流程架构设计能力,界定软件系统边界和能力,做到既能保证现状,又能对未来各种变化进行预埋,例如:在核心流程的互斥层面,用接口的形式构建一个标准的分布式互斥行为定义,将来若系统升级由单体架构升级为分布式架构,只需基于接口构建一个签名一致的工具类,即可完成架构升级
所以,这篇文章,笔者将不再拘泥于编译实现的各个中间层的细节,而是着重于强调读者如何基于这些输出,完成如下工作:
- 快速得出自己的需求,协同AI获得合适的输出
- 学会判断AI的准确性、合理性
- 基于AI看透本质,完成个人认知沉淀和进阶
希望我的理念对你有所帮助。
SharkChili · 禅与计算机程序设计的艺术
开源贡献
- mini-redis:教学级 Redis 精简实现 · https://github.com/shark-ctrl/mini-redis
关注公众号,回复 【加群】 加入技术社群
# 从历史了解Go语言的诞生
实际上,每一个技术的诞生,都是伴随一个历史的痛点,以本文所要讲的Go语言的编译过程为例,在计算机行业发展初期,2007年Google团队一直采用C++进行软件研发工作,由于系统工程的敏捷迭代,一个2000源文件、4.2MB的源代码项目在分布式编译集群下需要45分钟才能完成,即使经过各种极致的优化,也需要25分钟:
In 2007, build engineers at Google instrumented the compilation of a major Google binary. The file contained about two thousand files that, if simply concatenated together, totaled 4.2 megabytes. By the time the #includes had been expanded, over 8 gigabytes were being delivered to the input of the compiler, a blow-up of 2000 bytes for every C++ source byte. [1]
所以,Google团队就有了设计一门新语言的想法,即一种编译快、编程简单抑易于维护且性能表现出色的小而美的编程语言——于是就有了Go语言 [2]。所以这也是笔者为什么要讲解Go语言编译这一知识点的原因,即学会了解痛点并得出最佳解决方案,并学会汲取方案后面优秀的设计。
# Go语言编译过程详解
# 词法分析
国内大部分的教程都喜欢强调突兀的定理和结论,然后让读者带头毫无用处的结论进行后续的阅读和理解,这是笔者完全不能接受的。所以在讲解Go语言编译的时候,笔者还是希望从一个实际的场景出发,逐步推导得到结论,再进行总结,辅助读者感知理解,最后获得一个全局视角的知识体系:
回到文章课题,为了能够让读者对编译这个相对抽象的知识本身有着直观的理解和认知,我们给出本文的代码示例,即一段简单的计算函数和main传参调用:
package main
import "fmt"
func main() {
sum := calc(1, 2, 3)
fmt.Println(sum)
}
func calc(a int, b int, c int) int {
return a + b*c
}
2
3
4
5
6
7
8
9
10
11
12
13
14
完整的编码交给编译器之后,词法分析器会按照最小语义化单位将其切割为token序列,对应的我们的代码,将被拆解为如下子序列,因为有了AI,笔者对于这些词法解析的细节不做过度展开,大体描述一下这步的内容,本质上词法解析是将我们的编码按照既有关键字例如:
- PACKAGE关键字:记录声明的包名
- IDENT关键字:开发者定位的名字,例如main函数和add函数
- FUNC关键字:func关键字,定义函数
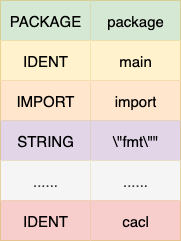
通过这种标准化关键字,将所有的编码转为标准化token,为后续的语法解析形成树结构做好准备。
# 语法解析
结合词法解析得到的基本token序列,语法解析阶段会通过高效的递归向下+运算符优先级的混合解析器,构建出AST树。以我们的代码所生成token序列为例:
- 看到func关键字,知道要解析函数,故调用parseFuncDecl
- 看到return关键字,了解知道返回值,调用parseReturnStmt
- 看到Return后面的a+b知道这是一个运算表达式,于是调用parseExpr
就这样逐层递归,于是就有了下面这棵宏观上的语法树:

与之对应还有一个运算优先级的分析,按照数学先乘除后加减的逻辑,我们的运算也会构建出一个AST树,如下所示,结合AST树自下而上的规律,该数学会先完成子树的乘法,然后递归向上完成加法运算:
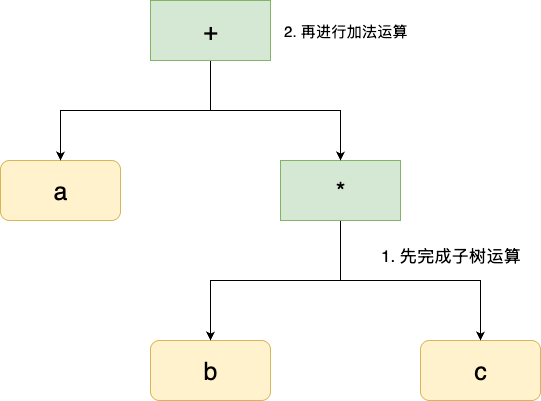
# 语义分析
语义分析阶段,主要完成类型检查、接口满意度检查和常量求值等细节优化工作。以我们的代码为例,因为入参a、b、c进行计算后求值也是int类型,所以类型检查是通过。
然后是接口满意度检查,因为我们代码比较简单,所以没有这一步骤,假设我们有个类要继承Writer接口,对应就需要编写和Writer接口签名一致的Write方法,即入参为byte数组,出参为int和error类型:
Write(p []byte) (n int, err error)
所以笔者在实现myWriter,就会按照签名约定指定签名格式保持一致,如下代码,反之若不存在该方法的实现,则会出现编译报错:*myWriter does not implement io.Writer (missing Write method)
// myWriter 实现了 io.Writer 接口(有 Write 方法)
type myWriter struct{}
func (w *myWriter) Write(p []byte) (n int, err error) {
fmt.Println(string(p))
return len(p), nil
}
2
3
4
5
6
7
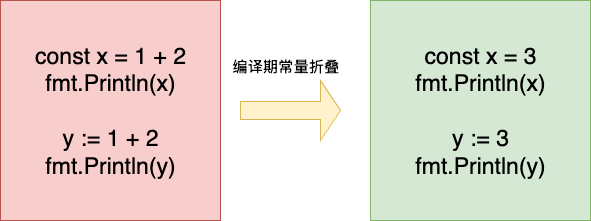
最后就是常量折叠了,这一步的工作就是Go语言执行高效的原因所在,和大部分高级语言一样,在编译阶段为了避免后续非必要的CPU运算开销,若存在常量级的显示运算,GO语言会在编译期直接完成常量折叠工作,例如我们存在一个运算代码:
const x = 1 + 2
fmt.Println(x)
y := 1 + 2
fmt.Println(y)
2
3
4
5
Go语言感知到运算操作是常量,则会直接在编译期进行常量折叠,在编译期完成计算,并写入到对应的变量上:
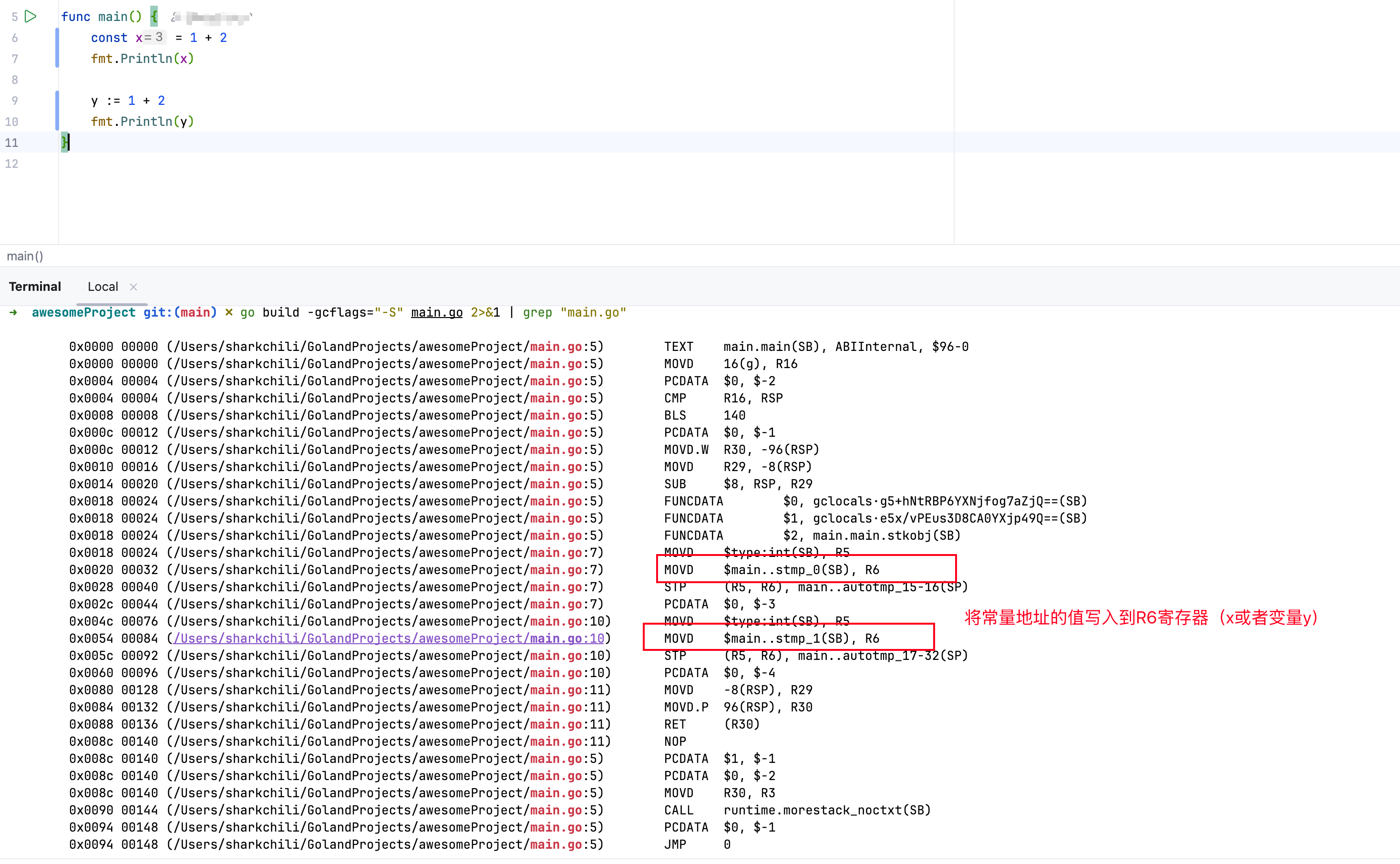
对应可通过如下指令完成汇编输出:
go build -gcflags="-S" main.go 2>&1 | grep "main.go"
输出结果如下,可以看到,编译器将常量计算结果直接在汇编码中体现,即直接将常量结果放到寄存器R6地址上,并没有add操作:
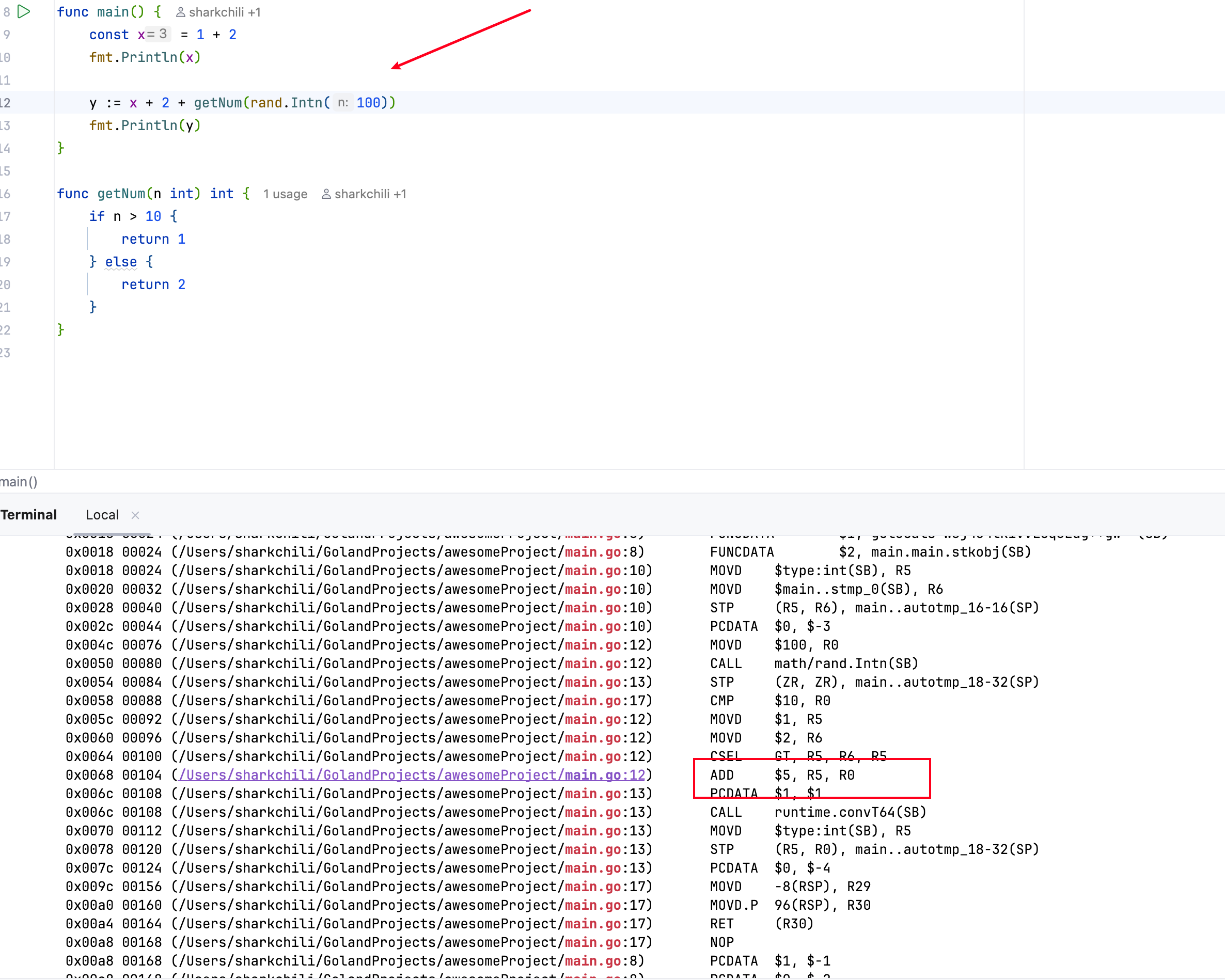
反之若无法在编译期感知变量实值的情况下,则会执行add操作:
# 中间端优化
中间端优化会执行一些函数内联和逃逸分析的操作,这也是一个非常经典的设计,函数内联顾名思义就是将简单函数编译优化为简单指令,避免栈帧跳转的开销,以我们的计算函数为例,则是直接将calc方法优化为一段函数指令:

还是以我们的运算函数为例,执行go build -gcflags="-m" main.go 2>&1查看汇编:
import (
"fmt"
)
func main() {
sum := calc(1, 2, 3)
fmt.Println(sum)
}
func calc(a, b, c int) int {
return a + b*c
}
2
3
4
5
6
7
8
9
10
11
12
可以看到在编译期针对add函数执行了内联操作,不再进行函数跳转调用,而是直接在当前栈帧完成运算:
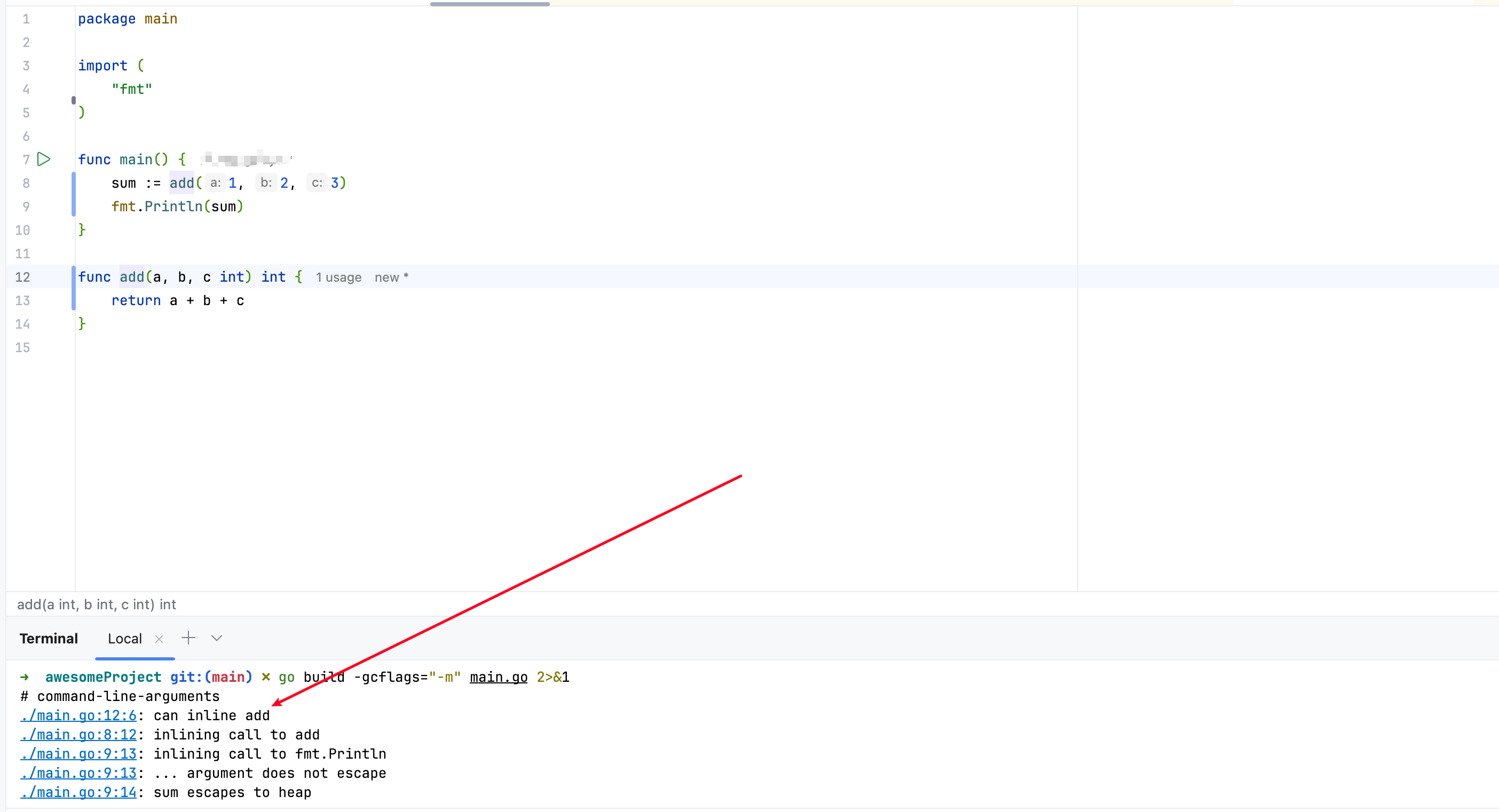
另外一个则是逃逸分析,这也是一个非常经典的设计,传统对象都是在堆上分配,这就涉及到内存申请等操作系统级别写入的开销,Go为了避免这一动态非可控的操作系统级别调用,进行了逃逸分析的优化操作,若发现对象并没有发生函数逃逸则直接在栈上分配,避免内存申请的开销(栈编译期即可知道分配大小)和非必要的GC操作:
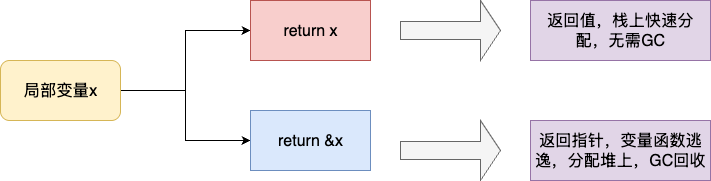
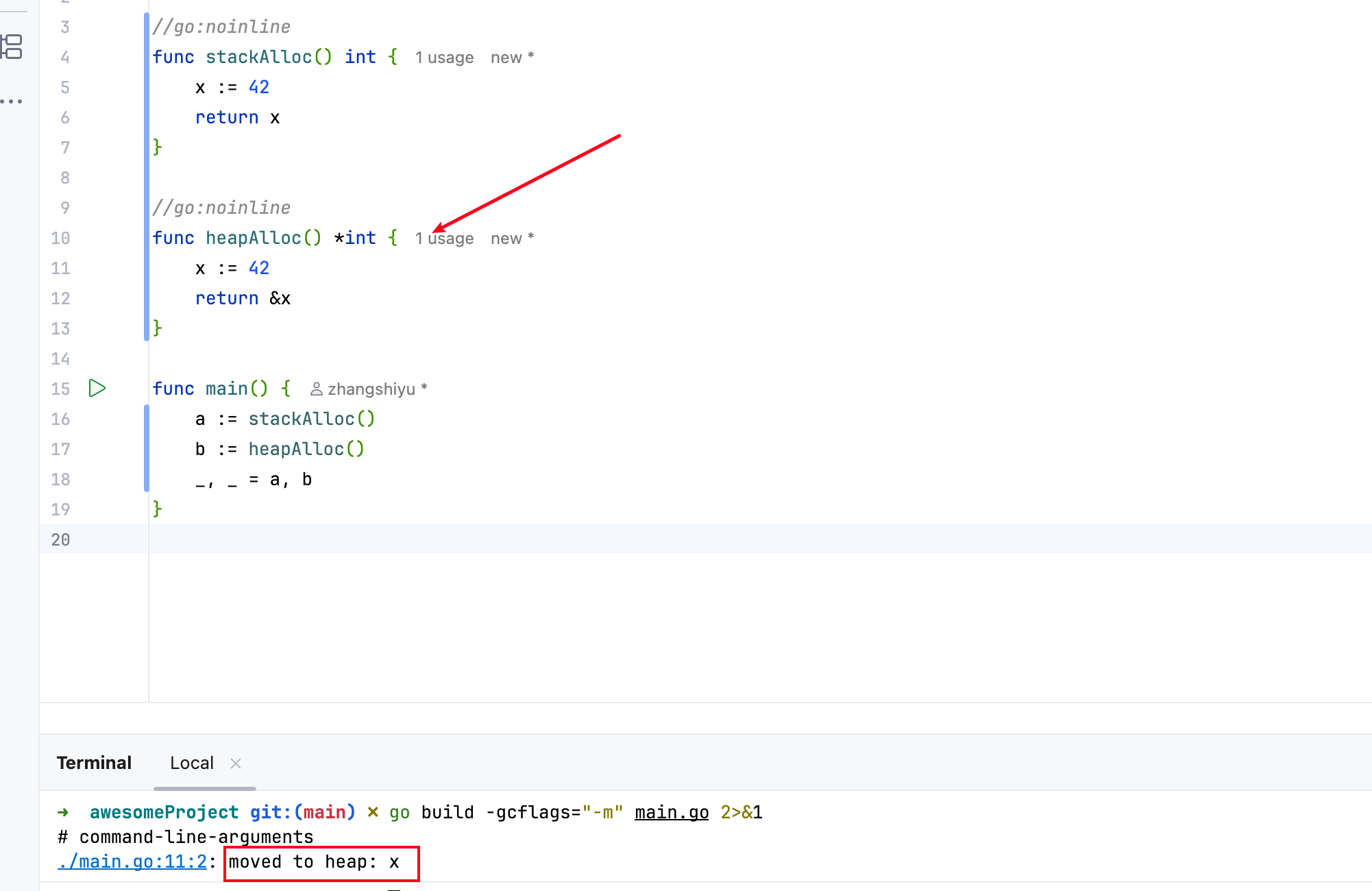
如下代码,我们分别创建两个方法,一个方法变量指针(发生逃逸),一个返回值,变量没有逃逸,并通过go:noinline避免这些函数内联:
//go:noinline
func stackAlloc() int {
x := 42
return x
}
//go:noinline
func heapAlloc() *int {
x := 42
return &x
}
func main() {
a := stackAlloc()
b := heapAlloc()
_, _ = a, b
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
最终执行结果如下,可以看到返回指针的变量,因为返回了变量地址导致函数逃逸,变量分配到了堆上,而返回值的函数,变量直接在栈上分配完成逻辑运算:
# 高级语法降级
高级编程语言本质是让开发者能够快速理解函数语义,高效完成编码工作,CPU则反之,这些非指令结构化指令在执行时非常抵消,所以GO语言存在一个高级语法降级的操作,即降一些语义化的语法转为标准法指令让CPU标准高效执行例如:
高级 Go 语法 降级后的基本操作
───────────── ──────────────────
m[key] = value ──▶ runtime.mapassign(map, key, value)
ch <- msg ──▶ runtime.chansend(ch, msg)
defer cleanup() ──▶ runtime.deferproc(&cleanup)
2
3
4
5
6
7
8
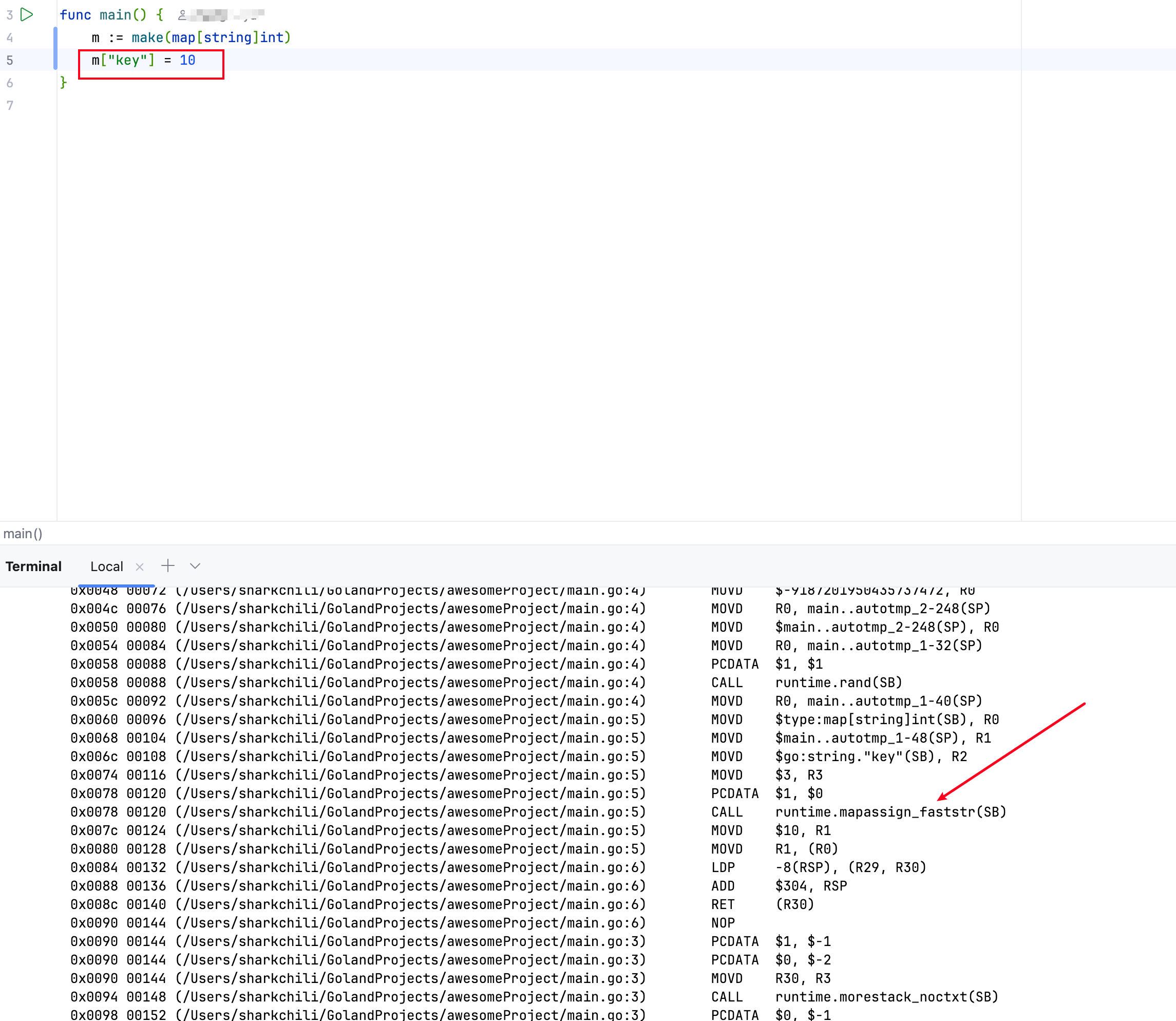
对此,笔者也写了一个简单的map赋值的代码,通过go build -gcflags="-S" main.go 2>&1 可以看到,这段代码底层被降低为runtime.mapassign_faststr这个高效的标准函数调用:
# 生成中间码
在生成各个系统平台可执行的机器码之前,go会生成一段与平台无关的中间汇编码,即可SSA码,在此期间,代码可能还会再进行一次优化工作,例如:
- 死代码消除
对于SSA码,感兴趣的读者可以在操作系统上通过这段指令生成:
GOSSAFUNC=main go build main.go
执行完成之后,文件夹会生成一段ssa.html,读者打开之后就会看到下面这样一个网页,其中网页的最右边就是我们说的SSA码,由于SSA码不是笔者本次讨论的重点就是就不做展开了:

# 生成汇编码
通过上述的步骤之后,系统就会得到中间码,自此各个平台都会基于这段中间码生成汇编码,当然如果你对汇编码感兴趣,可以通过下面这段执行看到我们的代码转为Plan 9的汇编码:
go build -gcflags -S main.go
可以看到一行简单的输出语句就变成下面这样一段汇编代码:
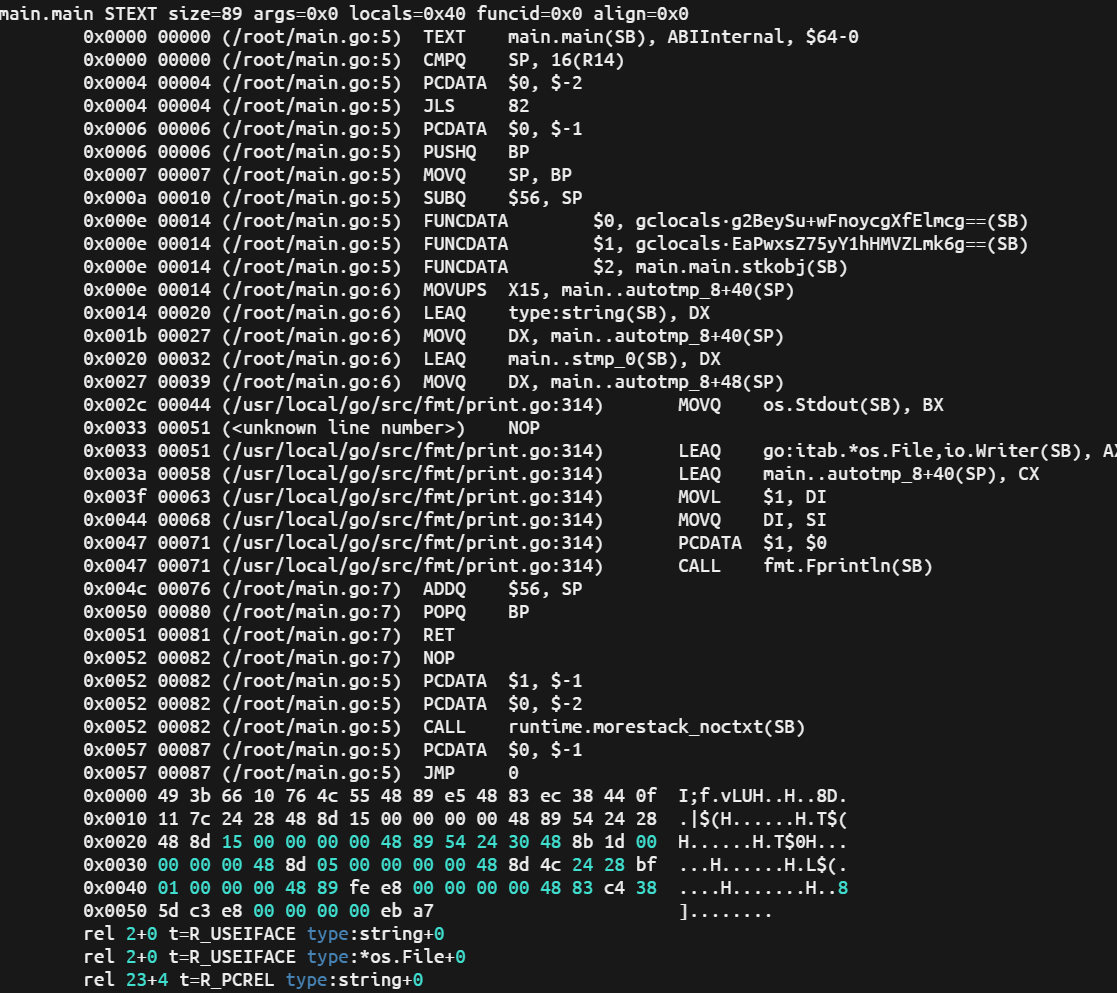
# 链接
基于上述的代码键入如下指令即可查看go语言的编译过程:
go build -n main.go
此时在Linux终端就会输出一大段日志,这里笔者就贴出几个比较核心的地方,首先就是导入配置,由上代码我们可知我们用到了go语言最基本的runtime和fmt包:
# import config
packagefile fmt=/root/.cache/go-build/7a/7a84f8c71e0cd98a53158ab655d48960d612698abe0567abbeb7a633bcb066b7-d
packagefile runtime=/root/.cache/go-build/e2/e2bf522ce6c0c2bfb09b8486578b70b1424422349a8dc2c5e200bf6b8760d950-d
EOF
2
3
4
随后就开始通过compile完成上述所说的编译过程:
cd /root
/usr/local/go/pkg/tool/linux_amd64/compile -o $WORK/b001/_pkg_.a -trimpath "$WORK/b001=>" -p main -complete -buildid 5LGDePcnhcnEtpXVckY4/5LGDePcnhcnEtpXVckY4 -goversion go1.22.0 -c=2 -nolocalimports -importcfg $WORK/b001/importcfg -pack ./main.go
/usr/local/go/pkg/tool/linux_amd64/buildid -w $WORK/b001/_pkg_.a # internal
cat >$WORK/b001/importcfg.link << 'EOF' # internal
.....
2
3
4
5
6
7
中间完成中间码和汇编码生成机器码之后,就来到了链接这一步,如下输出所示,可以看到它用到了/usr/local/go/pkg/tool/linux_amd64/link
cd .
/usr/local/go/pkg/tool/linux_amd64/link -o $WORK/b001/exe/a.out -importcfg $WORK/b001/importcfg.link -buildmode=exe -buildid=IGC7T6g3raqmSVvDtHEN/5LGDePcnhcnEtpXVckY4/5LGDePcnhcnEtpXVckY4/IGC7T6g3raqmSVvDtHEN -extld=gcc $WORK/b001/_pkg_.a
/usr/local/go/pkg/tool/linux_amd64/buildid -w $WORK/b001/exe/a.out # internal
2
3
最终在最后一段输出我们得到了可执行文件main,自此我们的go代码编译过程完成:
mv $WORK/b001/exe/a.out main
链接器把所有依赖——你的代码、标准库代码、Go runtime(调度器、GC、内存分配器)——全部打包进一个二进制文件。这就是为什么Go部署只需要一个文件。
# Go vs Java:编译模型对比
对于笔者的大部分读者都是Java背景(笑),这里做一个编译模型的对比:
| 维度 | Go | Java |
|---|---|---|
| 编译产物 | 原生机器码 | 字节码(.class) |
| 运行方式 | 直接执行,二进制包含完整runtime | 需要JVM,JIT编译 |
| 部署物 | 单个静态链接二进制 | jar + JRE |
| 启动速度 | 毫秒级 | 秒级(JVM预热) |
| 内存占用 | 低(~10MB) | 高(~200MB+) |
| 优化时机 | 编译期(AOT) | 运行时(JIT) |
简单解释一下上表中的 AOT 和 JIT:
- AOT(Ahead-Of-Time,提前编译):在程序运行之前,就把源代码一次性编译成机器码。Go、C、C++、Rust 都是 AOT
- JIT(Just-In-Time,即时编译):先编译成字节码(.class),等程序运行时,JVM 再把热点代码实时编译成机器码。Java、C# 默认是 JIT
AOT(Go)的执行流程: JIT(Java)的执行流程:
源码 → 编译器 → 机器码 → 直接执行 源码 → javac → 字节码 → JVM → 运行时编译成机器码
↑ ↑ ↑
开发阶段完成 开发阶段完成 运行时才完成
2
3
4
5
这个对比不是要分高下,而是帮读者理解:Go选择静态编译是为了部署简单和启动快,代价是放弃了JIT的运行时优化。理解它才能做出正确的技术选型。
# 小结
本文从Go语言的诞生背景出发,逐阶段拆解了Go代码从编写到运行的完整旅程:
- 词法分析:源代码 → Token序列
- 语法分析:Token → AST(递归下降 + 运算符优先级)
- 语义分析:类型检查 + 接口满意度检查 + 常量折叠
- 中间端优化:函数内联 + 逃逸分析
- 高级语法降级:map/channel/defer → runtime调用
- 生成中间码(SSA):平台无关优化
- 生成机器码:SSA → 原生汇编
- 链接:打包所有依赖 → 单个二进制文件
回到文章开头提出的三个核心能力,学完编译原理后,你应该能够回答:
- 设计决策:什么时候传值、什么时候传指针?——理解逃逸分析后你就知道了
- 原理分析:AI生成的代码性能如何?——用
go build -gcflags="-m"检查逃逸情况 - 架构选择:为什么选Go而不是Java?——理解AOT vs JIT的权衡后你就能回答了
SharkChili · 禅与计算机程序设计的艺术
开源贡献
- mini-redis:教学级 Redis 精简实现 · https://github.com/shark-ctrl/mini-redis
关注公众号,回复 【加群】 加入技术社群
# 参考
《Go语言设计与实现》
- 02
- 深入Redis SCAN源码:反向迭代算法的设计与实现06-01
- 03
- Go语言常见面试题解析(上)语言基础与核心概念05-20
