 mini-redis SCAN指令复刻:自底向上的工程方法论实践
mini-redis SCAN指令复刻:自底向上的工程方法论实践
# 写在文章开头
有了AI之后,笔者一直在反思这段时间敏捷交付所带来的低收益问题。也正是因为这一点,笔者有幸在网上看到Google技术总监addyosmani的一篇文章《Don't Outsource the Learning》,该文章非常精准地点出了当下的一个问题——认知投降:

addyosmani在这篇文章中一直强调,随着ai能力的不断发展,我们只需明确贴出问题,模型即可快速定位并完成问题交付,由此人与问题斗争的过程随之消失。有研究表明,对于深度依赖LLM完成的工作内容,大脑中与这些最终交付内容相关的神经连接性急剧降低,开发者对于既有问题的理解为零。这使得每一次交付,都可能成为将来认知上的债务,且对于个人并没有任何提升:
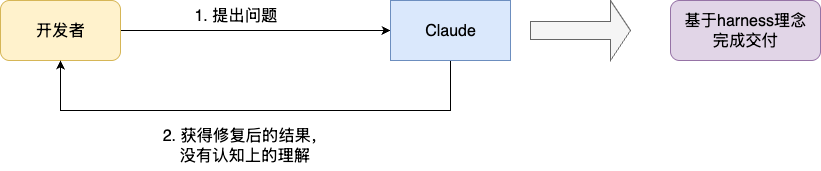
所以,addyosmani提出AI时代下,工程师对于AI工具使用的一些实践上的建议:
- 善用claude code learning模式协作,让其引导我们完成既有问题的学习和思考,并写好模板代码,将核心且有价值部分让我们主动完成
- 面对问题作出假设,用AI辅助验证自己的猜想,而非取代你的思考
- 对于不熟悉的领域,让AI先进行解释和说明,明确概念之后,再让其进行编码和学习了解
- AI完成问题的交付后,询问其思路,用到哪些概念,学习优秀的设计理念,并加以学习沉淀
The trouble is that friction was where the learning lived,只有经过与问题的斗争和深度思考,才能完成系统工程知识的储备和沉淀,确保面对LLM幻觉时依然有足够的专业知识去识别这些错误:

所以,笔者就有了每周一次深度编码的想法,这篇文章不会去深究scan指令实现的细节,笔者将着重说明笔者如何结合AI主动思考并拆解和分析问题,并完成核心算法的学习和复刻。
只有动手尝试编程,才能更加细致的感知每个架构的设计和算法的每一个细节,从而确保在快节奏的AI编程下,依然可以快速准确完成决策,构建出稳健的软件系统。
因为本文着重编程任务的方法实践,所以不会深入讲解redis scan指令的实现细节,可参考笔者这篇文章的解析:https://mp.weixin.qq.com/s/5ybr9ab23r9ID530d2SUdA (opens new window)
SharkChili · 禅与计算机程序设计的艺术
开源贡献
- mini-redis:教学级 Redis 精简实现 · https://github.com/shark-ctrl/mini-redis
关注公众号,回复 【加群】 加入技术社群
# 梳理与落地步骤详解
# 理清思路
对于此复杂逻辑的长任务,涉及既有逻辑梳理、全新架构复刻的任务,首要做的就是理清既有的代码逻辑,整理出实际的核心主干部分,构建出完整的业务链路图,再基于每个子步骤进行详细的梳理,理解其每个步骤的意图,从而获得一份有效的设计稿:
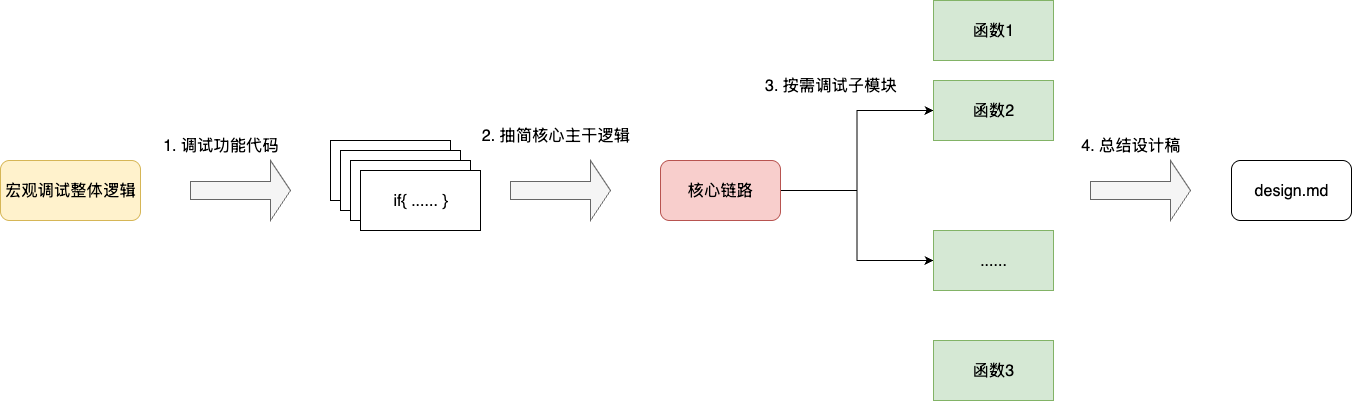
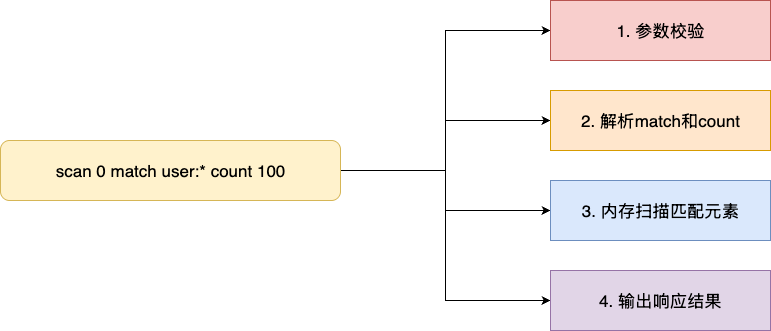
以笔者本次的scan指令复刻为例,按照上述的梳理笔者大体得出该指令的核心逻辑:
- 校验参数合法性,例如count后面跟随的是否是整数,match后面的glob表达式是什么
- 如果存在match和count则获取参数值
- 基于上述参数到redis db内存中扫描获取匹配元素
- 输出返回
# 拆解并自底向上实现
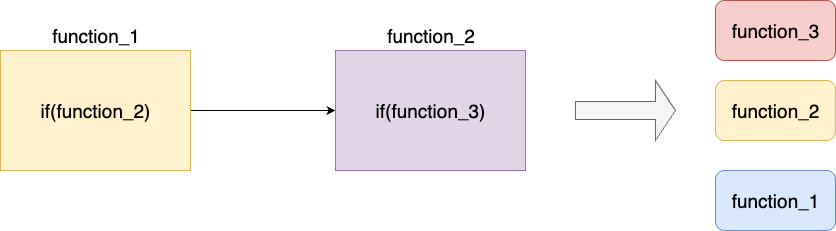
无论是传统编程调试还是AI辅助梳理,上一步结束后,我们已经具备对于核心方法和每一个细节的理解和掌握,为了确保落地的有序执行,在编码前,笔者会尝试按照自底向上的方式逐步完成编码从而构建出完整的功能。
我们基于上述步骤完成宏观拆分结构之后,为保证能够独立完整的实现,以做到学习redis优秀理念的目的,就需要做到针对每个步骤实现步骤拆解,按照笔者的习惯是自底向上的完成层层逻辑封装,例如:函数function_1部分逻辑依赖于function_2,而function_2又依赖于function_3,所以我们的实现步骤就是:
- 完成function_3的逻辑封装
- 完成function_2的逻辑封装
- 基于完整的function_2完成核心的function_1函数封装
我们以dictScan这个扫描redis db的函数为例,其底层涉及一个将db元素写入链表的回调函数dictScanFunction的抽象和反向迭代算法rev,所以我们的实现步骤则是:
- 完成函数回调的type定义
- 编写回调函数scanCallback
- 完成二进制翻转算法rev编写
- 完成dictScan函数的编写
# 函数式回调设计与实现
明确的逻辑复刻的基调之后,我们就开始逐步完成复刻,首先是处理字典的回调函数定义,我们在dict.go中完成如下type声明:
/*
*
字典元素回调处理函数结构定义:
1. privData 数组:索引0为存放元素的链表,索引1 额外的redis obj对象
2. de :当前要处理的键值对
*/
type dictScanFunction func(privData [2]any, de *dictEntry)
2
3
4
5
6
7
8
9
明确回调函数定义之后,我们可以完成本次要用到的scanCallback函数的实现,逻辑比较简单:
- 获取privData中的链表和robj
- 根据robj是否为空,判断是否是普通的redis db scan,以本次复刻为例,robj肯定为空
- 调用dictGetKey获取传入的键值对的key值
- 将key值写入到链表中
这里笔者补充说明一点,为了保证链表的通用性,笔者将链表相关操作都通过接口抽象的方式处理,这也是为什么笔者取出redis key之后还要用接口封装一下再写入链表的原因所在:
func scanCallback(privData [2]any, de *dictEntry) {
//获取数组0的链表
keys := privData[0].(*list)
//获取数组1的robj
o := privData[1].(*robj)
var key, value interface{}
//如果robj为空,说明当前是普通scan函数的调用,直接从dictEntry中获取key
if o == nil {
sdsKey := dictGetKey(de)
key = interface{}(sdsKey)
}
//将key添加到数组0的链表
listAddNodeTail(keys, &key)
if value != nil {
listAddNodeTail(keys, &value)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 二进制翻转函数的实现
翻转二进制则是http://graphics.stanford.edu/~seander/bithacks.html#ReverseParallel中的优秀实践,利用分治位运算在 O(log N) 步内完成全位翻转,为redis后续的高位递增算法做好性能保障:

对应源代码如下,对该算法感兴趣的读者可以移步笔者这篇文章的关于本章节的二进制算法的解析: https://mp.weixin.qq.com/s/Eb7RqFOi25G8l9cdUYcM7A (opens new window)
相关章节截图如下:
对应源代码如下,感兴趣的读者可结合注释推算一下,需要注意一下,Go 语言中 ^ 作为一元运算符时是按位取反:
// 反转二进制位
func rev(v uint64) uint64 {
//获取待翻转的数的位宽
s := uint64(64) // 8 * sizeof(uint64)
//获得一个全1的掩码,注意:^运算 在Go语言中为按位取反
mask := ^uint64(0)
//位宽除以2,步入下面的循环进行二分翻转,例如二进制0000 1111,对应除2的位为4,第一轮翻转结果为1111 0000
s >>= 1
for s > 0 {
//获得低位全1的掩码,例如1111 1111 经过移位+异或运算获得0000 1111
mask ^= (mask << s)
/**
进行高低位翻转,假设传入v:0000 1111,对应位数为8,s位2,对应执行步骤为:
(v >> s) & mask => (0000 1111>>4) & 0000 1111=> 0000 0000 & 0000 1111 => 0000 0000
(v << s) & ^mask => (0000 1111<<4) & 1111 0000=> 1111 0000 & 1111 0000 => 1111 0000
最终两段结果做或(OR)运算,获得 1111 0000 完成4位翻转
*/
v = ((v >> s) & mask) | ((v << s) & ^mask)
s >>= 1
}
return v
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 字典扫描逻辑实现
通过上述两个底层原子函数的铺垫之后,我们已经具备实现字典扫描所需的全部原子能力,下面给出 dictScan 的完整实现:
/**
* 扫描字典元素并存入字典
* @param d 字典
* @param v 扫描起始位置
* @param fn 回调函数 本次传入的是scanCallback
* @param privData 回调函数的参数,我们只需要知道数组0为链表即可
*/
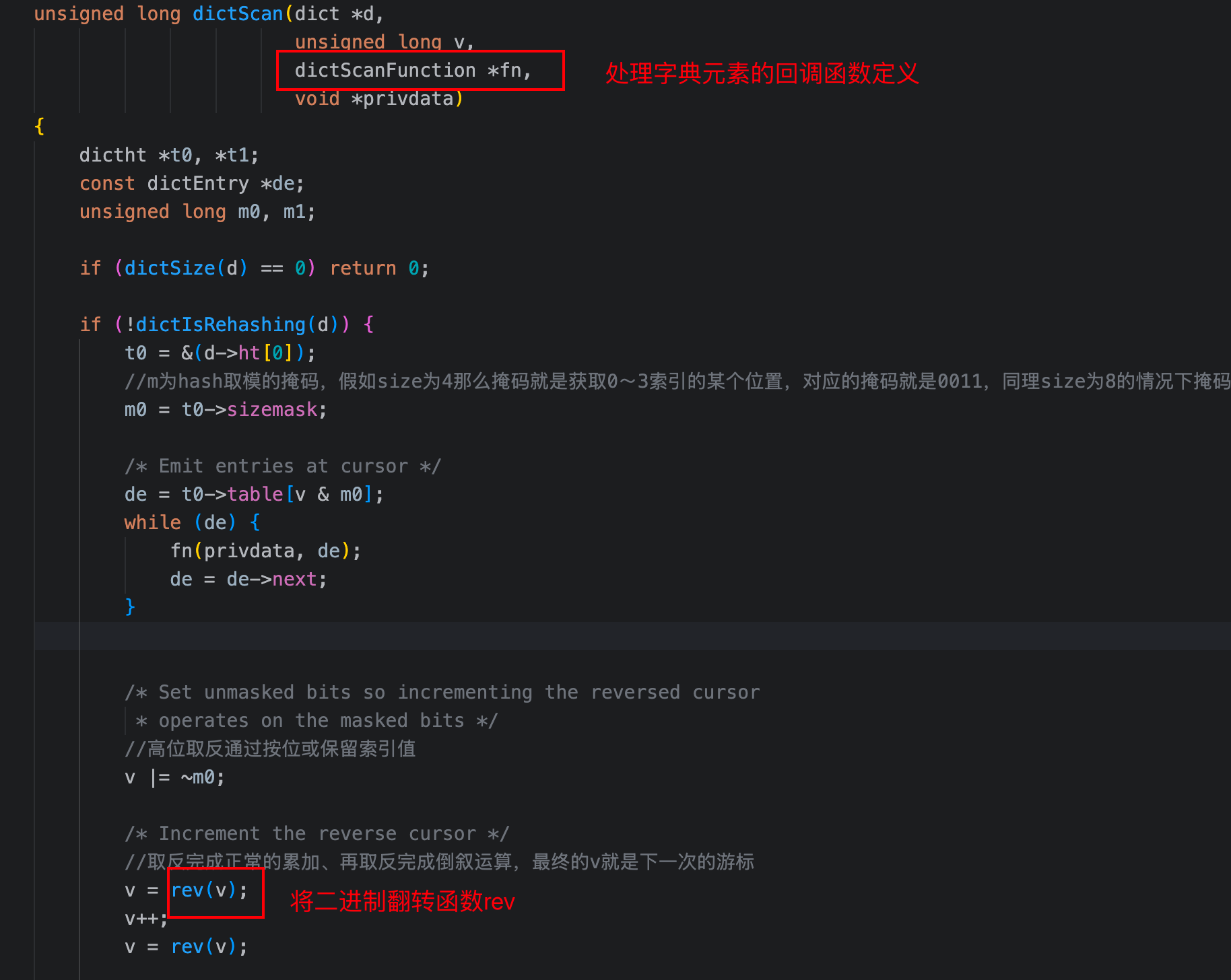
func dictScan(d *dict,
v int64,
fn dictScanFunction,
privData [2]any) int64 {
var t0, t1 *dictht
var de *dictEntry
var m0, m1 int64
//若字典为空直接返回
if dictSize(d) == 0 {
return 0
}
//非渐进式哈希,直接扫描数组0
if !dictIsRehashing(d) {
t0 = &(d.ht[0])
m0 = int64(t0.sizemask)
//定位具体bucket
de = (*t0.table)[v&m0]
//若bucket非空,通过回调函数fn将元素值存入链表中
for de != nil {
fn(privData, de)
de = de.next
}
/**
完成反向递增,例如 数组为4 对应mask则是低2位, 该算法就是不断通过低2位向右+1, 对应0000 的迭代则是:
0000 0010 0001 0011 =>0 2 1 3
*/
v |= ^m0
v = int64(rev(uint64(v)))
v++
v = int64(rev(uint64(v)))
} else {
//渐进式哈希场景:ht[0] 与 ht[1] 同时存在,需要把两张表都扫到
t0 = &(d.ht[0])
t1 = &(d.ht[1])
//算法前置条件:t0 必须是小表、t1 必须是大表,保证 for 循环里的反向二进制递增能覆盖大表所有相关 bucket,避免漏扫
if t0.size > t1.size {
t0 = &(d.ht[1])
t1 = &(d.ht[0])
}
m0 = int64(t0.sizemask)
m1 = int64(t1.sizemask)
//小表只扫 v 对应的那 1 个 bucket
de = (*t0.table)[v&m0]
for de != nil {
fn(privData, de)
de = de.next
}
//大表扫描所有"低位与 v&m0 一致"的若干 bucket
for {
de = (*t1.table)[v&m1]
for de != nil {
fn(privData, de)
de = de.next
}
//在大表 mask 空间里做一次反向二进制 +1
v |= ^m1
v = int64(rev(uint64(v)))
v++
v = int64(rev(uint64(v)))
//差异位 m0^m1 全部归 0 时,v 已推进到下一个小表 bucket,可退出
if v&(m0^m1) == 0 {
break
}
}
}
return v
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
# scan函数封装
最后,所有的原子能力都完成,直接将scan进行封装,即完成:
- 参数解析
- 元素扫荡
- 匹配过滤
- 按照协议规范输出
func scanGenericCommand(c *redisClient, o *robj, cursor *int64) {
var i, j int
keys := listCreate()
var node, nextNode *listNode
var count int64
count = 10
var pat string
var usePattern bool
var ht *dict
if o == nil {
i = 2
} else {
i = 3
}
for i < int(c.argc) {
j = int(c.argc) - i
if strings.EqualFold((*c.argv[i].ptr).(string), "count") && j >= 2 {
if getLongFromObjectOrReply(c, c.argv[i+1], &count, nil) == false {
goto cleanup
}
if count < 1 {
addReply(c, shared.syntaxerr)
goto cleanup
}
i += 2
} else if strings.EqualFold((*c.argv[i].ptr).(string), "match") && j >= 2 {
pat = (*c.argv[i+1].ptr).(string)
// 单一 "*" 等价于不过滤,跳过逐元素匹配开销
usePattern = !(len(pat) == 1 && pat[0] == '*')
i += 2
} else {
addReply(c, shared.syntaxerr)
goto cleanup
}
}
if o == nil {
ht = &c.db.dict
}
if ht != nil {
var privateData [2]any
privateData[0] = keys
privateData[1] = o
var maxiterations int64
maxiterations = count * 10
for {
//扫荡元素写入链表
*cursor = dictScan(ht, *cursor, scanCallback, privateData)
//迭代次数更新
maxiterations--
if *cursor == 0 || maxiterations <= 0 || listLength(keys) >= count {
break
}
}
//遍历链表元素
node = listFirst(keys)
for node != nil {
nextNode = listNextNode(node)
kobj := (*node.value).(*robj)
filter := false
//若存在匹配模式,且元素与匹配模式不匹配,则过滤该元素,将filter设置为true
if usePattern && !stringmatch(pat, (*kobj.ptr).(string), false) {
filter = true
}
//若元素过期,也过滤
if !filter && expireIfNeeded(c.db, kobj) == 1 {
filter = true
}
//从链表删除待过滤的元素
if filter {
listDelNode(keys, node)
}
node = nextNode
}
}
//按照RESP协议输出长度为2,数组0记录游标,数组1记录元素个数
addReplyMultiBulkLen(c, 2)
//输出下一次的游标
addReplyLongLong(c, *cursor)
//数组1输出数组长度+元素
addReplyMultiBulkLen(c, listLength(keys))
//遍历结果集链表并输出
for {
if node = listFirst(keys); node == nil {
break
}
//获取链表值并输出
kobj := (*node.value).(*robj)
addReplyBulk(c, kobj)
//删除该链表
listDelNode(keys, node)
}
cleanup:
keys = nil
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
# 测试验收
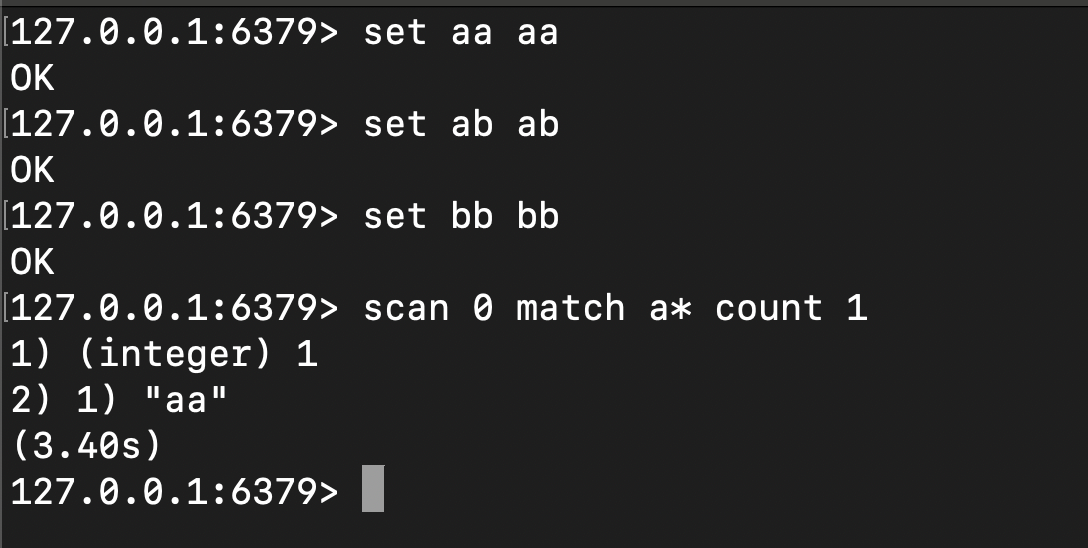
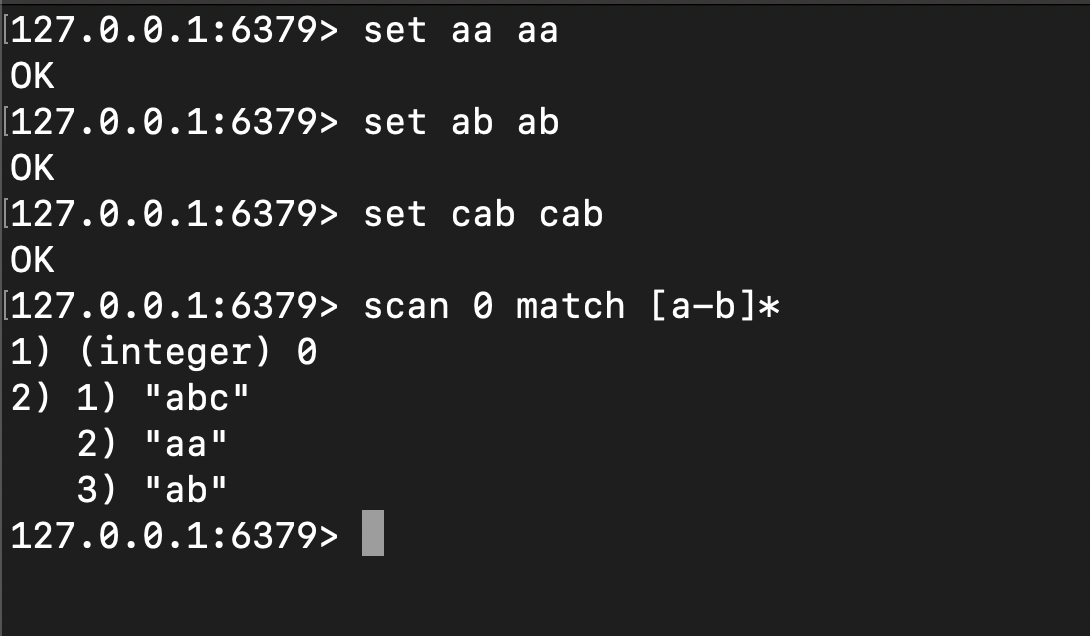
最后就是验收流程了,这一点一直是笔者比较重视的一个传统开发模式中比较重要的过程,一般情况下,笔者会在设计阶段就为每段逻辑设计对应的单元测试,以做到充分覆盖,以本次scan的代码为例,我们手工向redis写入aa、ab、bb等测试数据,对应的单元测试则是:
- 测试scan 0是否全扫描
- 测试scan 0 count 1是否正常输出一个元素,并返回下一次的坐标
- 测试scan 0 match aa是否正常扫输出元素aa
- 测试删除aa,验证 scan 0 match aa是否输出空响应
- 测试写入aa ab ac,scan 0是否全扫描
- 测试aa ab ac,scan match a* 是否全扫描输出
整体原则就是结合代码,构建完整的覆盖场景,主动调试理解代码并完成结果验收,这里给出笔者最基础的单元测试调试场景,即键入测试数据后,通过scan指令验收mini-redis输出结果:
# 基于学习模式进行复盘验收
人的认知是有限的,利用LLM强大的知识语料辅助自己进行代码评审和纠错,有助于获得一个正向反馈,以提升本次编码的学习收获。
以笔者为例,在mini-redis下打开claude code,键入/config指令进入配置修改:

搜索output style点击空格将其设置为learning模式:
然后以学习为目标,指定目标代码实现,让其进行深度评审,然后手工修复:

对应的,claude code很好的结合上下文和go语言特性给出建议,我们就可以结合其提示完成修复工作:

结合Claude的说明,笔者很好的完成的代码的修复和重构,完成了对glob算法核心逻辑的闭环:
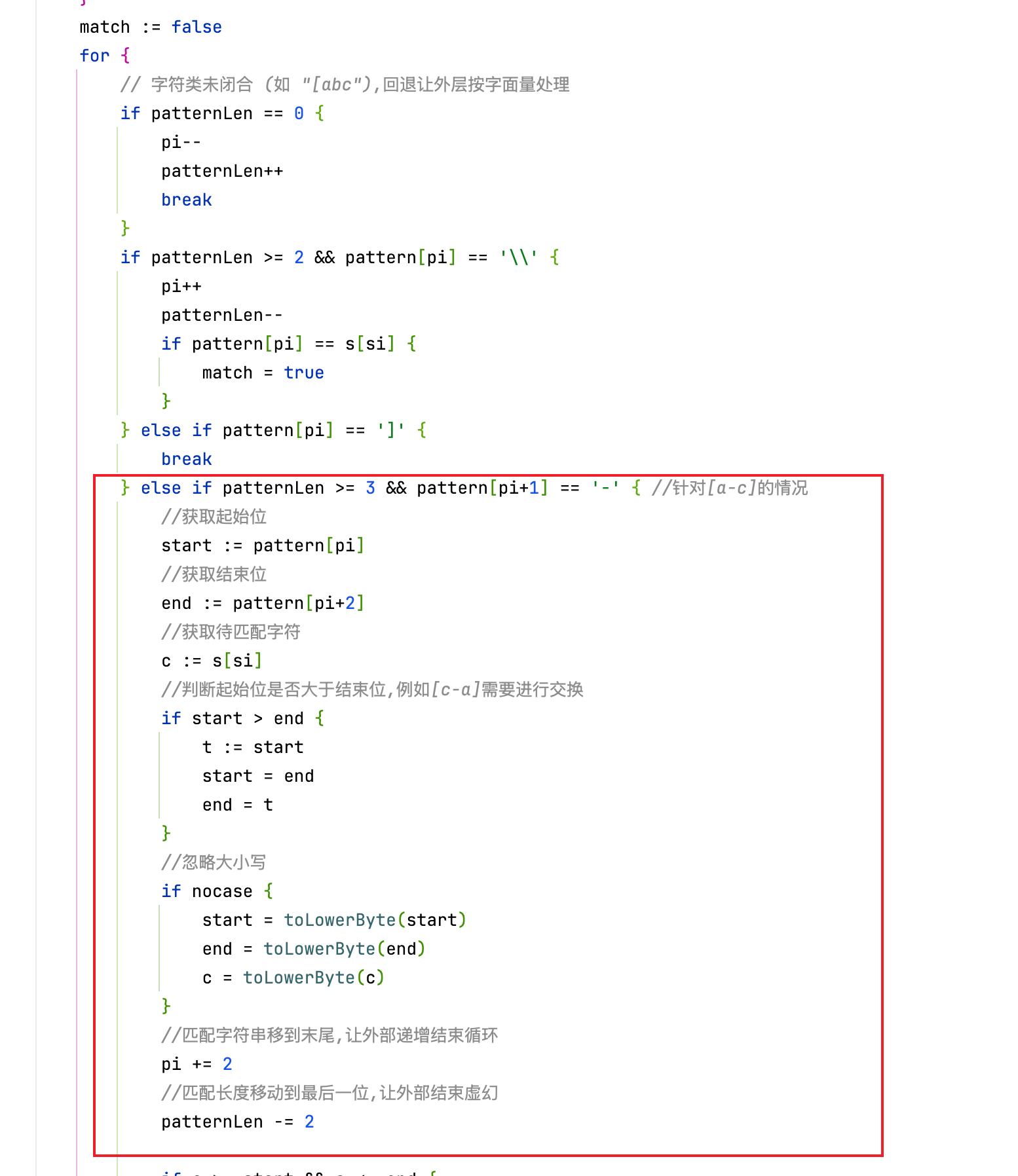
可以看到,learning mode会替你完成非核心的样板代码填充,将具有价值的部分进行详细说明并提供思路,让工程师主动完成,确保任务准确交付的同时,对当前任务构成一次有效学习:

最后笔者补充了一次完整调试,辅助理解本次编写的代码,完成完整的学习闭环:
# 小结
在ai时代,开发者要学会沉淀自己的工作理念,保证高效的完成工作落地,本篇文章没有过分纠结代码细节,而是强调一种工程方法论,即逻辑学习和任务拆解,最后再自底向上原子构建,并结合AI工具进行完整的反馈完成学习闭环,希望对你有帮助。
SharkChili · 禅与计算机程序设计的艺术
开源贡献
- mini-redis:教学级 Redis 精简实现 · https://github.com/shark-ctrl/mini-redis
关注公众号,回复 【加群】 加入技术社群
# 参考
Don't Outsource the Learning:https://addyosmani.com/blog/dont-outsource-learning/ (opens new window)
《Redis设计与实现》
- 02
- 重读 Redis SCAN 源码:那些当年没看懂的反向迭代细节06-01
- 03
- Go语言常见面试题解析(上)语言基础与核心概念05-20
