 基于Claude Code速通Redis Set的设计与实现
基于Claude Code速通Redis Set的设计与实现
随着AI编码工具的普及,笔者发现一个很不好的现象:问题解决效率确实高了,但每次问题修复后却没有任何收益,开发者的模型没有得到任何成长。Addy Osmani把这个现象叫作认知债务(cognitive debt),即一种用未来的能力换眼下的速度的工作方式。
Addy Osmani并不是反对使用AI,而是反对错误的工作姿态。他在文中还引用了一组对照数据:两组工程师学同一个新库,完成速度相近,但事后的理解测验,AI组明显低于手写组。而且AI组内部也分化得厉害——把AI当老师、追问概念的人,理解程度远高于直接复制粘贴的人。MIT那篇《Your Brain on ChatGPT》(arXiv 2506.08872)用EEG也测出了类似结果,用LLM时大脑连接最弱,绝大多数人写完连自己刚写的一行都背不出来。说到底,决定结果的不是工具,是你拿它干嘛。
工具一点点把编码里的摩擦磨平了,可学习偏偏就长在那些摩擦里。好在同一批工具也能反过来用,Anthropic的Claude Learning Mode、OpenAI的Study Mode、Google的Guided Learning,都是用苏格拉底式的提问逼你先动手写再往下走。可惜大多数人把它当成了“学生才用的东西”丢在一边。
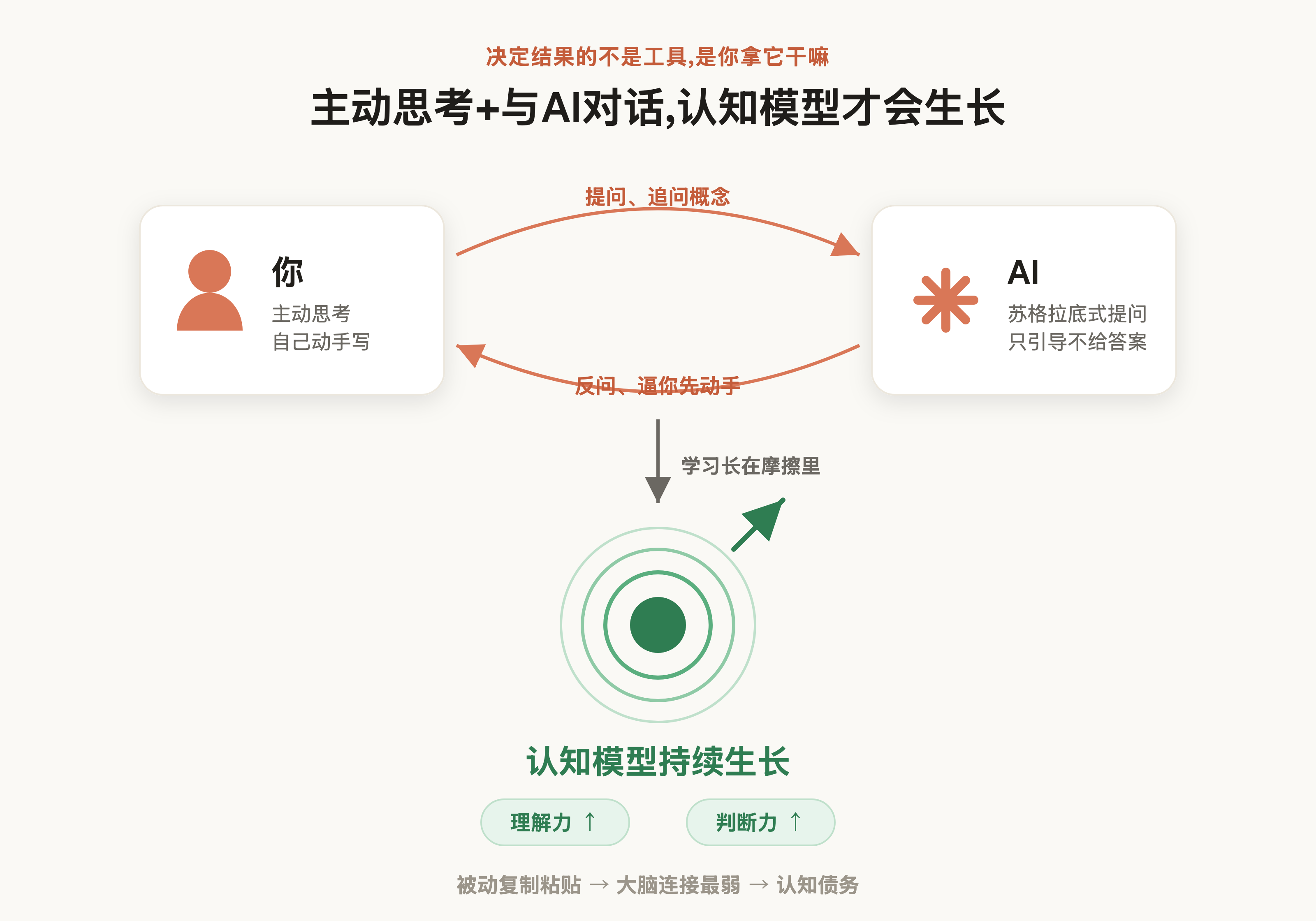
这篇文章就顺着这个思路走一遍。笔者会用 Claude Code 的 learning mode 完整复刻一次 Redis 的 SET 集合,核心自己手写、AI 补边角。这不只是一篇讲 Redis 源码的文章,过程中也会分享一些 Claude Code 在日常开发里好用的实践技巧。
更着重介绍的,是笔者认为 AI 时代最宝贵的一种能力:技术判断力,也就是面对AI 看似准确的方案,你能不能判断出当前场景该选哪个的思想理论。
# 前置配置步骤
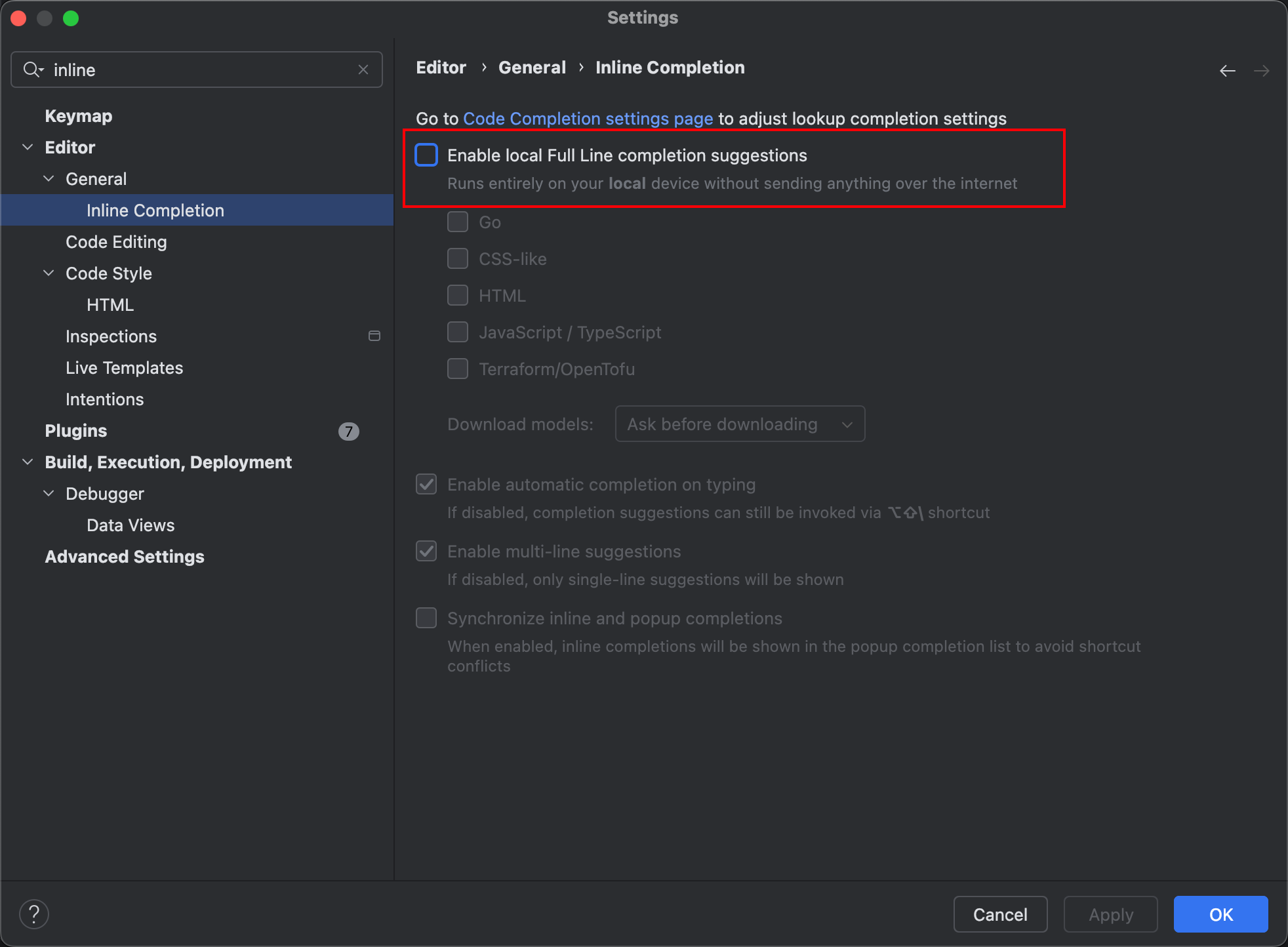
因为本次任务着重于开源项目的学习,为了让学习收益最大化,笔者建议先把 GoLand 的整行代码补全关掉,确保自己对每个需求都能完整地独立思考:依次进入 Settings | Editor | General | Inline Completion,找到 Enable local full line completion suggestions 选项,取消勾选即可。
# 详解set集合的复刻
# 添加上下文
复刻代码和重构型任务一样,必须先给 AI 提供需要迁移或复刻的逻辑上下文。所以正式编码的第一步,是通过 /add-dir 指令把本地的 redis 源码目录纳入当前会话的可访问范围:
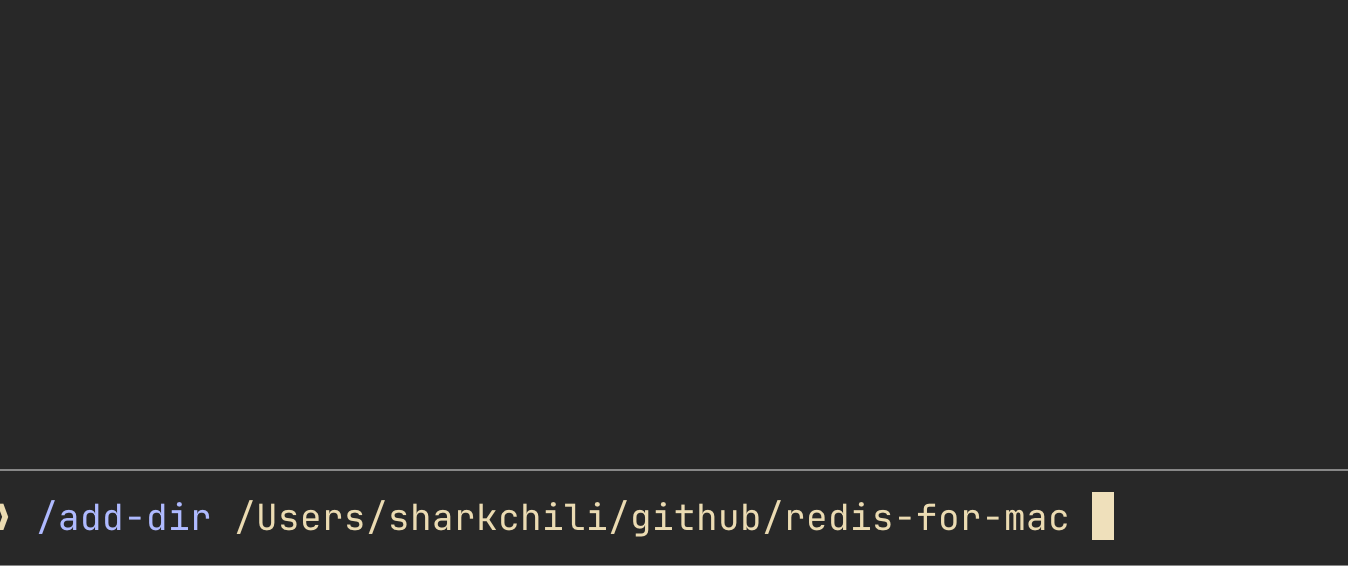
为了方便后续复用,笔者直接选择 remember。这样一来,项目下的 .claude/settings.local.json 就会多出一条 redis 源码目录的配置,接下来即可着手 learning mode 的编码复刻计划:
{
"permissions": {
"additionalDirectories": [
"/Users/sharkchili/github/redis-for-mac"
]
}
}
2
3
4
5
6
7
8
9
# 调整为learning mode
输入 /config 进入 Claude Code 配置界面,选择 Output style。Claude Code 内置了四种输出风格:默认的 Default(标准软件工程模式)、Proactive(主动执行)、Explanatory(讲解模式)和 Learning(学习模式)。其中和学习直接相关的是后两种:
Explanatory: 会在帮你完成编码的同时穿插“Insights”讲解,让你理解每一处实现选择Learning: 更进一步,是一种“边做边学”的协作模式
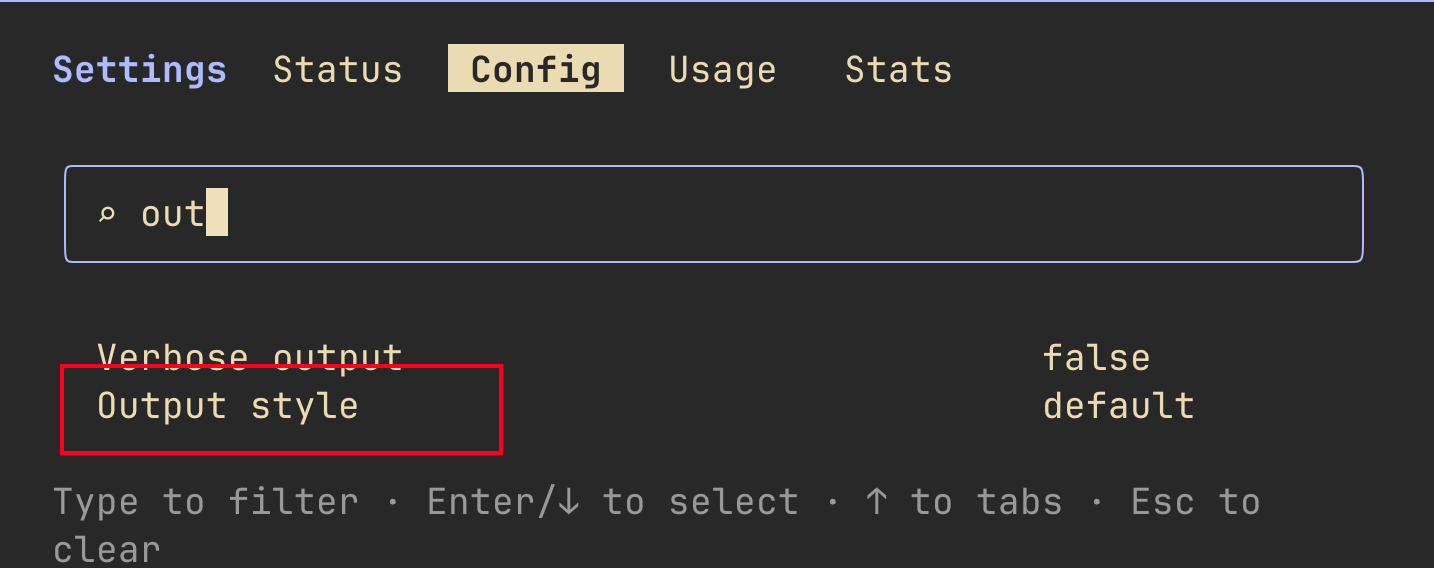
我们这里选 Learning 模式。从介绍可以看到,该模式下 Claude Code 不只会输出讲解,还会主动把关键片段留给你亲手写——它会在代码里插入 TODO(human) 标记,让你根据需求理解上下文,完成核心逻辑补全,训练开发者需求理解、上下文梳理和编码等多项综合能力:
一路回车,模式成功切为学习模式。需要注意,output style 属于系统提示词的一部分,仅在会话启动时读取一次,所以切换后要 /clear 或新开一个会话才会生效。此时我们就可以开始本次的编码工作了:
# 梳理源代码
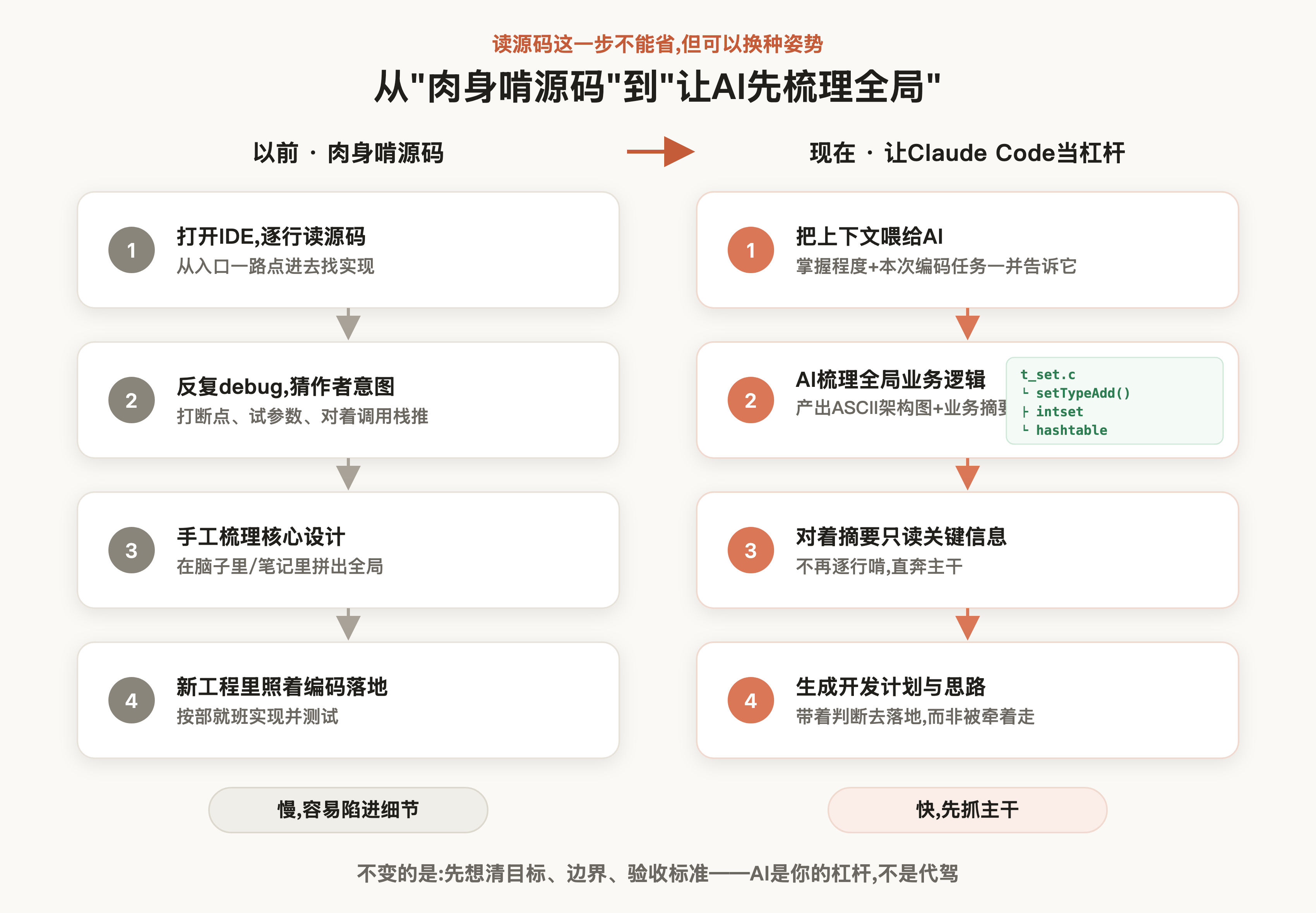
在正式复刻前,我们必须对任务有充分了解。本次要复刻的是 redis 的 set 集合,按笔者以往的习惯,都是先在 IDE 里深入阅读源码、理清核心设计,再结合当前工程梳理出开发步骤,然后按部就班地落地并测试。
这一步看似只是"读源码",实则是 AI 时代最关键的一环:明确自己的目标。工具越强,越容易被它牵着走——你不清楚自己要什么,AI 就会替你做决定,最后产出一堆"能跑但你看不懂"的代码。只有先把目标、边界和验收标准想清楚,AI 才是你的杠杆而不是你的代驾。所以哪怕有了 Claude Code,这步梳理也不能省。
有了 Claude Code,这些梳理工作就可以交给它来辅助。所以笔者很直接地把自己当前对 redis 的掌握程度,以及本次的编码任务,都一并告诉了它——只有它了解你的真实水平,才能把握好讲解的深浅:
可以看到,单凭一句提示词,Claude Code 其实摸不清笔者的真实掌握情况,于是它主动做了两件事来补全上下文:一是加载 superpowers 的头脑风暴流程,二是通过 codegraph 扫描当前项目。这里顺带介绍下这两个工具,后续读者自己用 Claude Code 时也能用上——superpowers 是一套 Claude Code 插件/技能,把"头脑风暴、需求澄清、计划拆解"这类工作流固化成可复用的步骤。codegraph 则是一个 MCP 服务,它把整个工程的符号、调用关系预先建成一张代码知识图谱,让 Claude 不必逐个文件 grep 就能快速理解项目结构。借助这两者,它先和笔者做了一轮详细澄清,确保能正确地引导笔者通过学习模式完成 redis set 集合的复刻:

# 思路学习
正式动手前,先跟着 Claude Code 把 set 集合的设计思路过一遍。下面几节分别从数据结构、编码升级、整数集合的插入到核心指令逐层拆解,理论与源码相互印证。
# set数据结构分析
在与笔者进行详细的澄清之后,AI终于开始对笔者进行指导和开发了,输出结果如下,可以看到claude code结合上下文掌握情况给出redis set集合编码结构、设计哲学和源代码定义位置,通过理论+源代码双重印证的方式引导笔者逐步学习和了解代码的设计和实现思路。
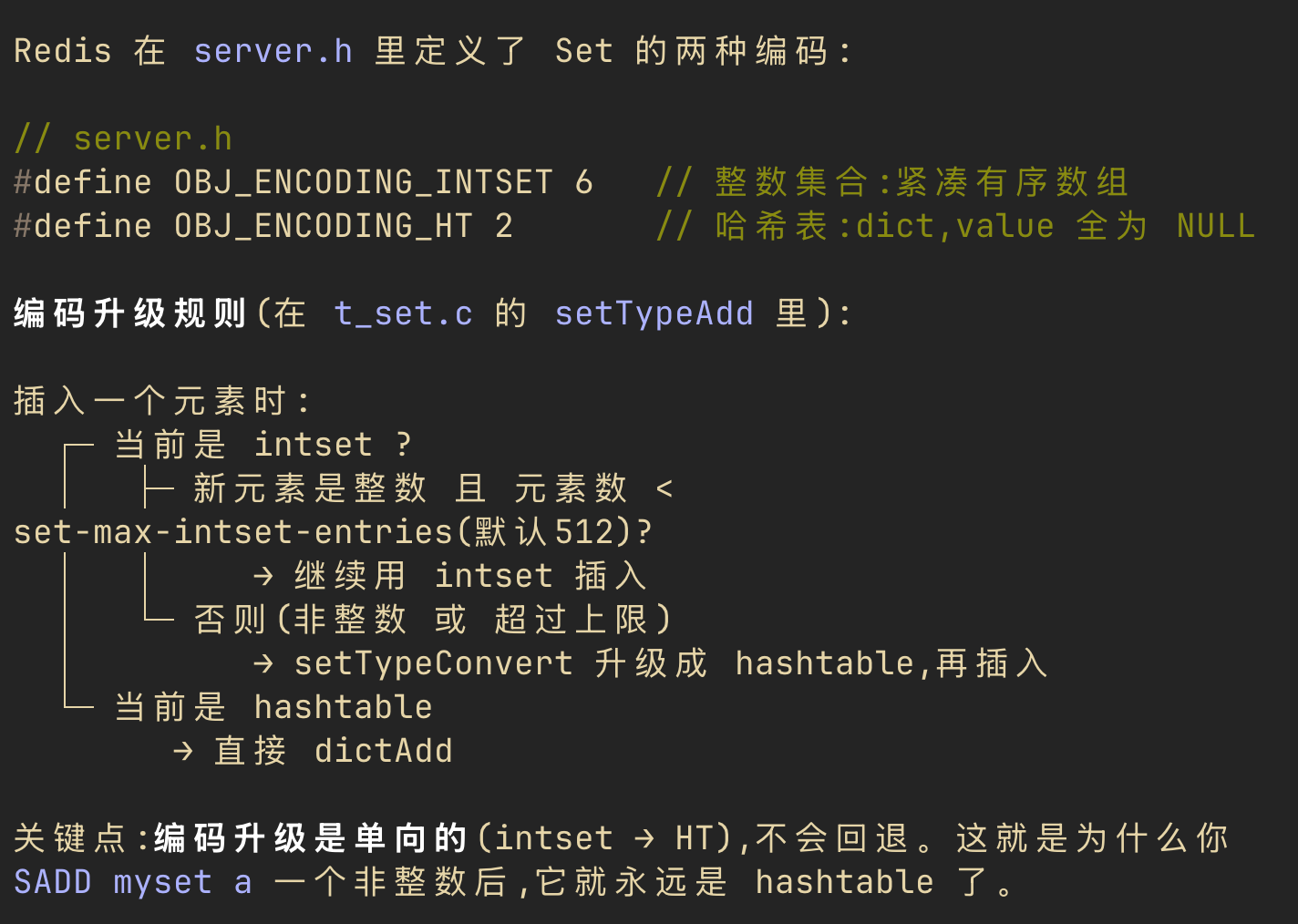
首先,它讲清了 redis set 集合的双编码设计:set 的本质是用哈希表实现的,用 key 来存元素、value 留空,这一点和 Java 的 HashSet 很像。同时为了避免不必要的内存开销,当元素全是整数且数量较小时,redis 底层会改用整数集合(intset)来存储。

# 编码升级
明确基本数据结构后,它给出了编码升级规则:默认情况下,只要满足“元素个数超过 512(set-max-intset-entries)”或“插入了非整数元素”这两个条件之一,intset 就会升级为 hashtable,否则一直用 intset 存储。
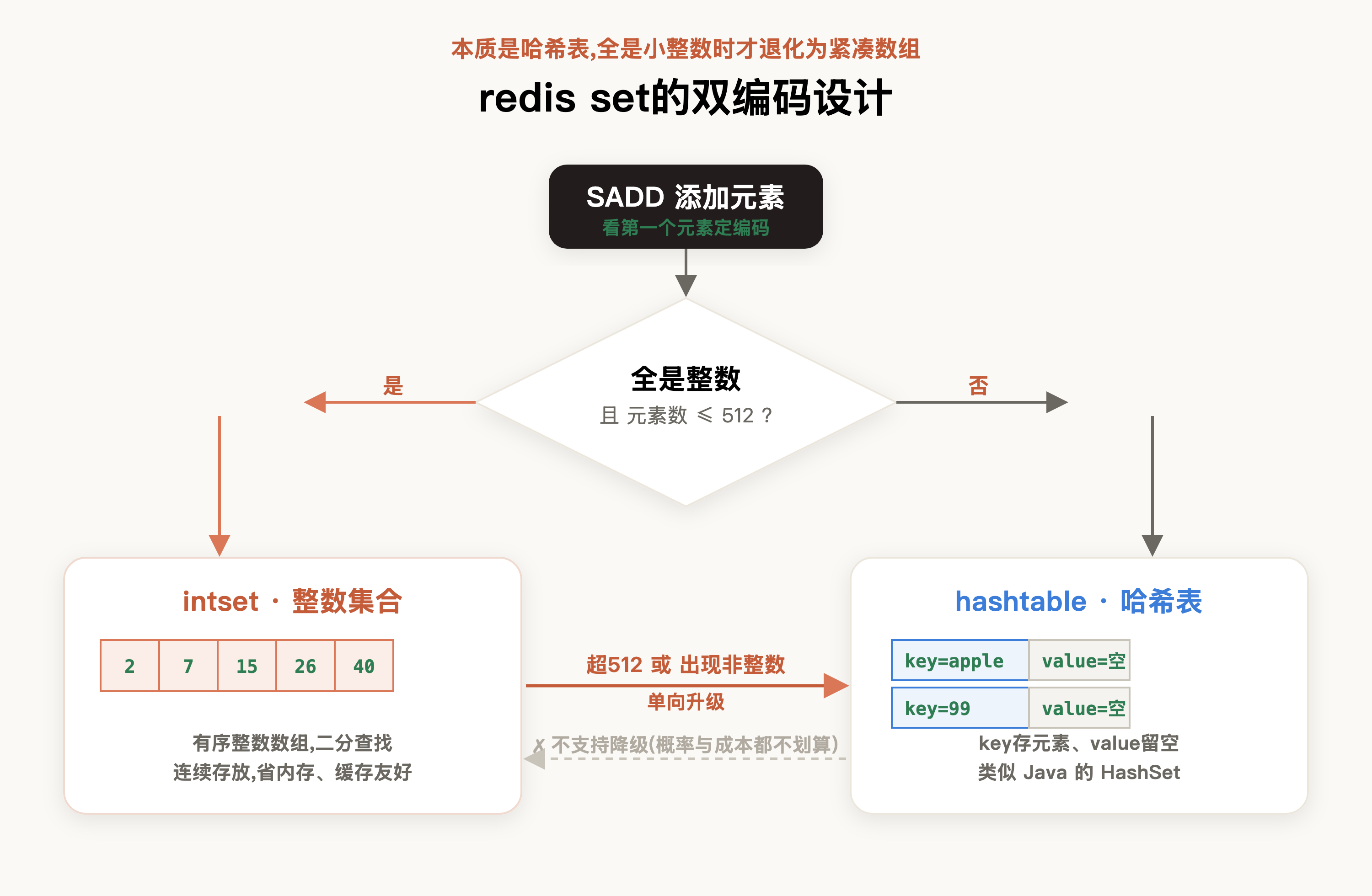
同时它指出升级是单向的——笔者顺着这点想了一下:无论是元素类型变化还是容量增长,从概率上看,set 一旦升级后几乎不可能再退回“小容量且全是整数”的状态,所以 redis 干脆只做单向升级。
笔者想特别强调这种"顺着规则往下追问一层"的习惯。在 AI 时代,让 AI 给出结论和代码已经几乎零成本,真正稀缺的是你能不能在拿到结论后多问一句"它为什么这么设计"。就像这里,AI 只告诉你"升级是单向的",但只有自己再推一步,才能想明白单向背后的概率与成本权衡。
当然,再从软件工程的成本角度看,降级操作的性价比本就不高:真遇到这种极端场景,我们通常也会在应用层重新设计数据结构,而不是指望底层去做反向降级。这恰恰是 AI 时代仍要坚持读源码、保持技术嗅觉的原因——你得有能力判断 AI 给的方案合不合理:
# 整数集合的插入
整数集合(intset)用一个统一编码的有序数组来维护元素。它的编码宽度有三档——int16(2 字节)、int32(4 字节)、int64(8 字节),redis 始终选用“能装下当前所有元素的最小宽度”,以此压榨内存、提升 CPU cache 局部性。无论处于哪一档,元素定位都按 下标 × 当前编码宽度 计算偏移来统一寻址,保证读写效率。

一旦插入了超出当前档位的整数(比如一个需要 8 字节才放得下的大整数),就会触发整体升级:数组里每个元素都重新编码到更宽的档位。intset 全程保持升序,所以每次插入都是先用二分查找定位插入位置,再挪位写入,从而维持有序且不重复:

# 核心指令介绍
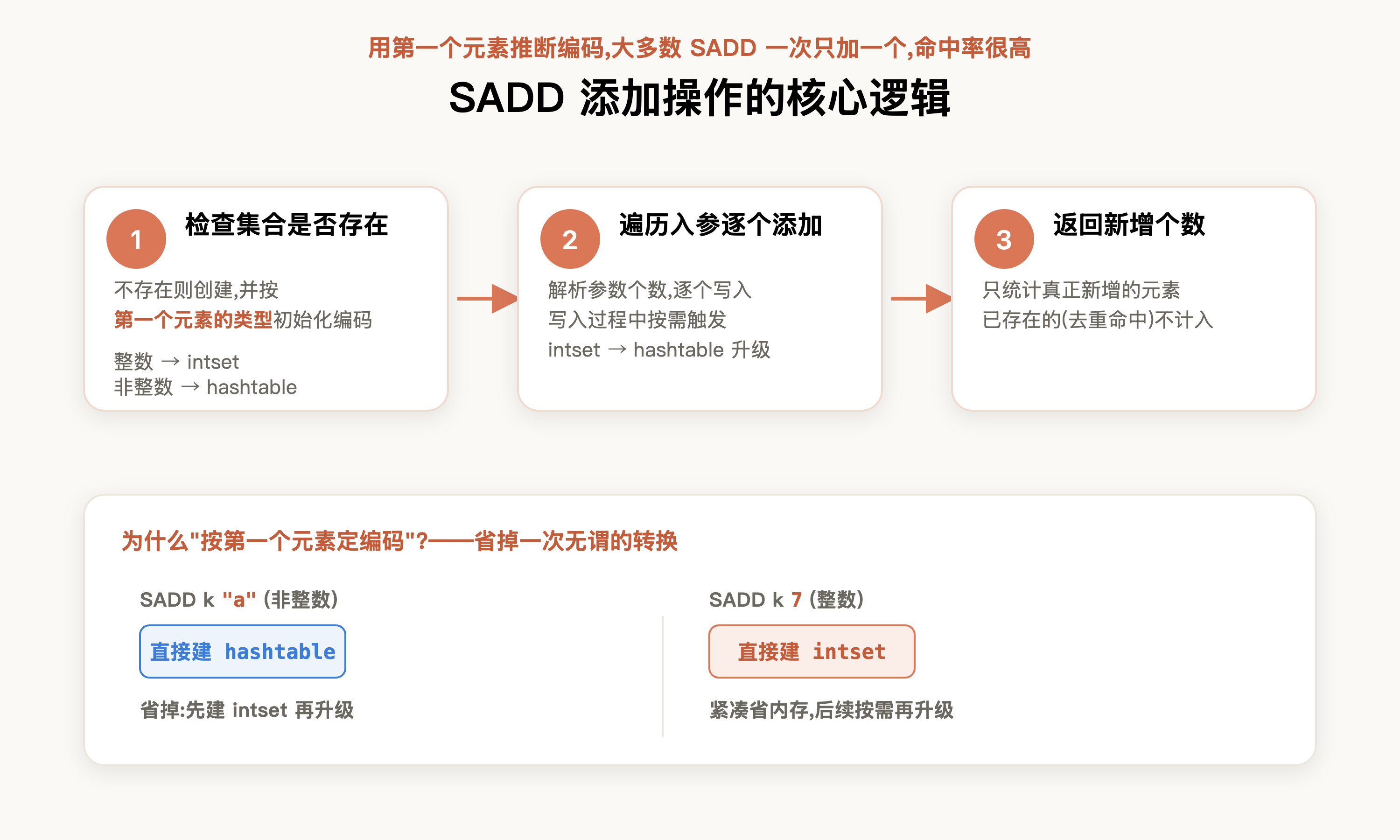
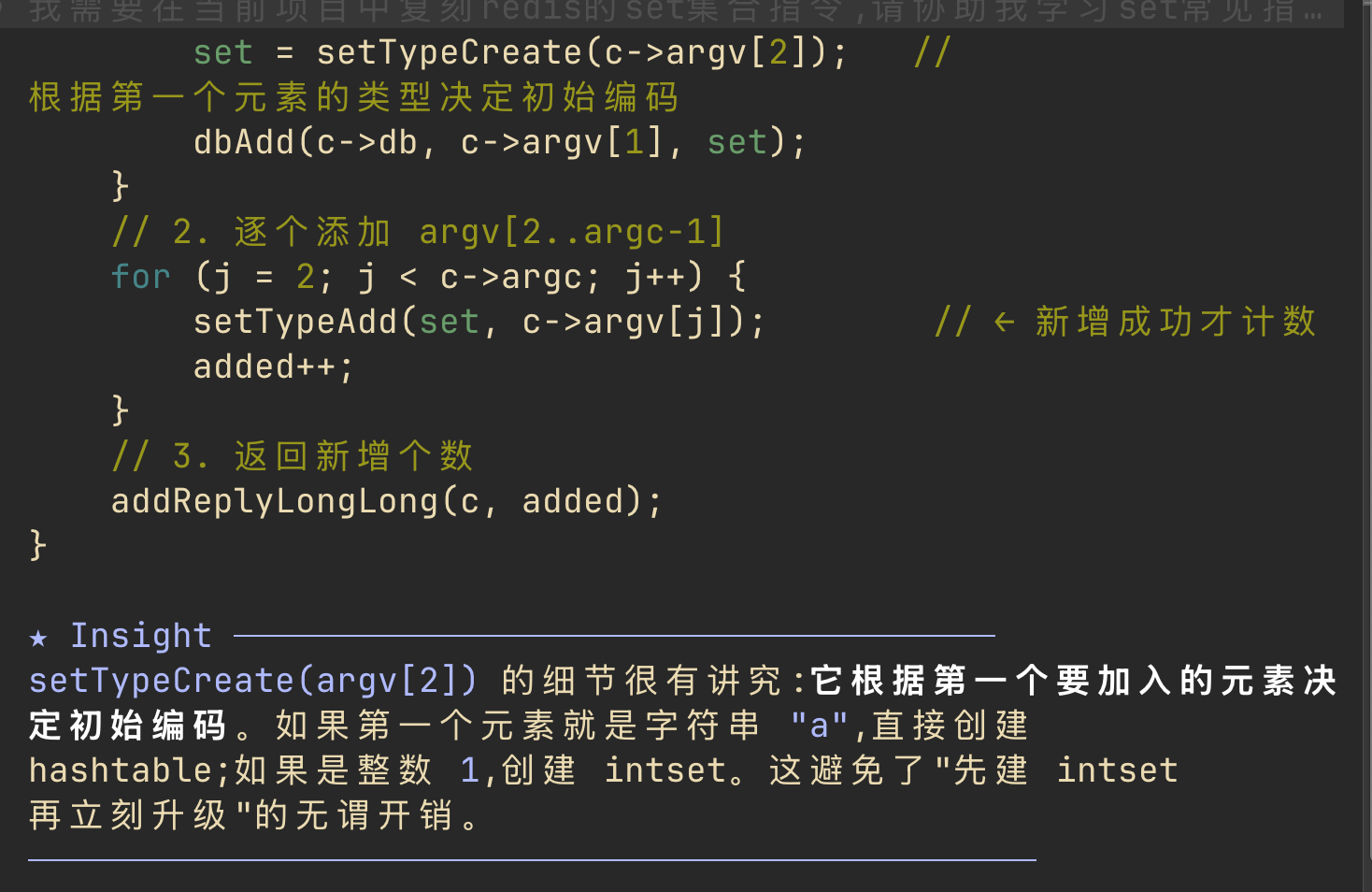
learning 模式很好地把握了开发者的认知负载,针对添加指令,它很好地抽丝剥茧,给出最核心的代码段。可以看到,它排除非必要的细节,简要给出 set 集合添加操作的核心逻辑:
- 检查当前key的集合是否存在,不存在则创建,同时根据第一个类型进行初始化编码
- 解析入参个数,遍历元素添加到redis
- 返回本次添加个数
同时它也精准地指出,“按第一个元素初始化编码”本质是一种尽量贴合数据的设计:用第一个元素来推断本次集合的编码类型。因为大多数场景下,开发者用 SADD 一次往往只加一个元素,所以拿第一个元素来定编码是个高命中率的策略——比如传入的是 a(非整数),集合就直接初始化为 hashtable 编码,省掉了“先建 intset、再因非整数升级为 hashtable”的无谓转换开销:
# 编码落地
# 需求定义
这里展开说说笔者的考量。因为有了大语言模型的支持,无论是任务上下文的梳理,还是编码产出的验收,都能快速拿到反馈与帮助,试错成本被压得很低。所以笔者干脆选择了完整的双编码复刻——不挑软柿子捏,力求把 redis 源码这次能学的东西尽量学透,让这趟源码学习的收益最大化。
至于复刻的命令范围,本着效率和收益的平衡,笔者最终选择了 SADD 以及 sunion/sdiff/sinter 这类集合运算的常见指令——前者打通 set 的写入与编码路径,后者覆盖集合最有代表性的运算场景,足以把核心数据结构的定义与实现都练到:
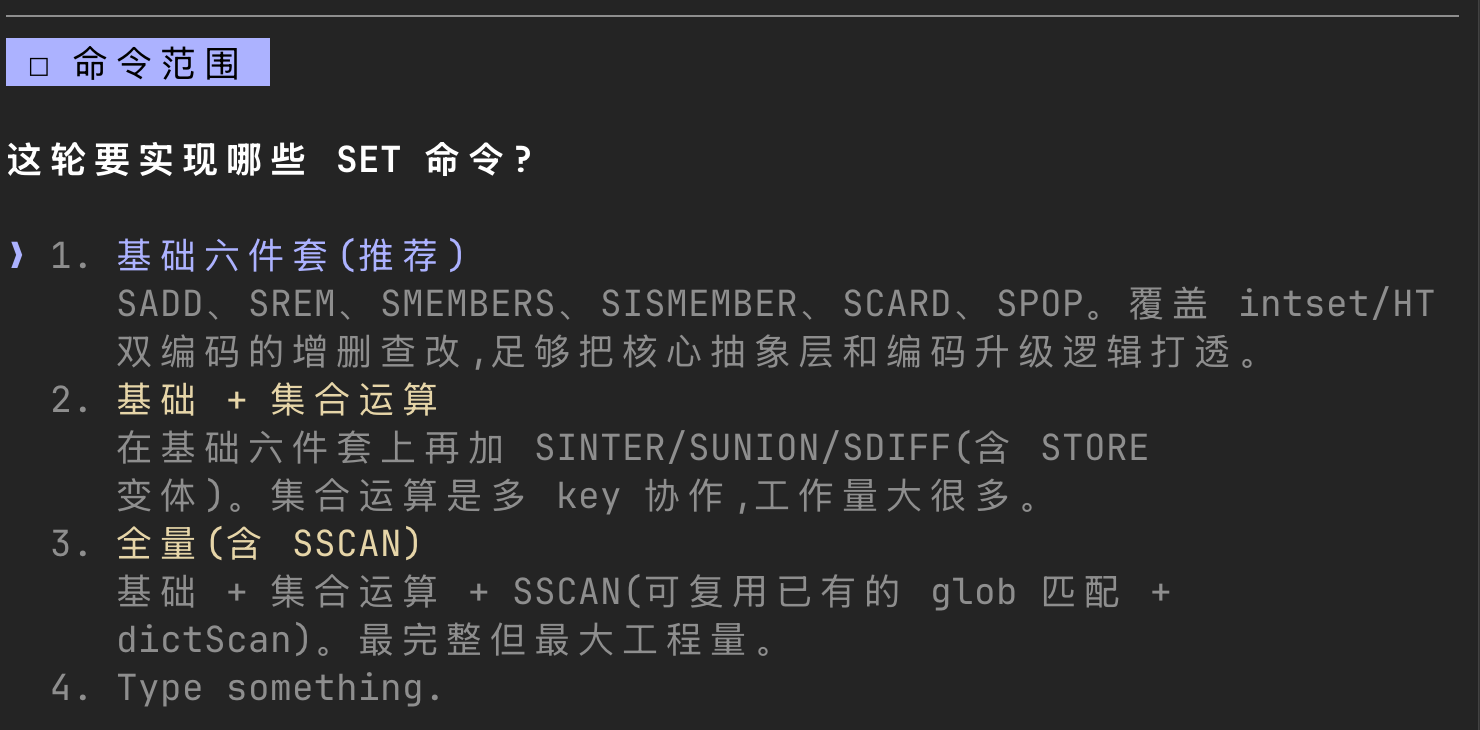
在 superpowers 的加持下,笔者很快就完成了这五层需求的拆解与定制:

# 整数集合的封装
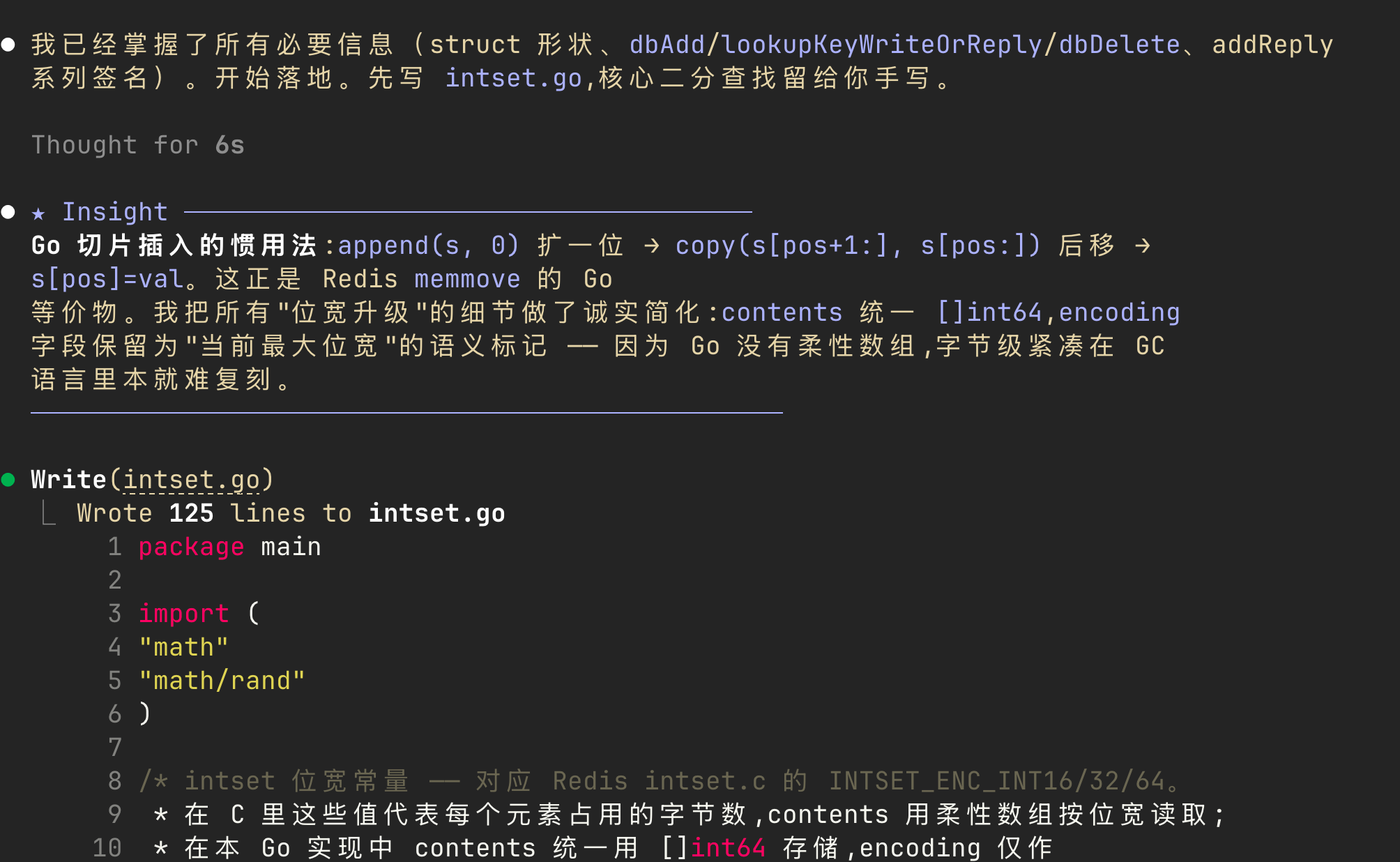
等AI把任务规范输出完,我们就正式进入开发与学习。claude code会结合学习需求,复用工程里已有的基建,并搭建好基础代码骨架——把不那么核心的部分先替我们写好,只把真正需要动脑的算法留出来。
以本次intset封装为例,claude code已经搭好了整数集合的完整骨架:intsetValueEncoding负责按值计算所需位宽,createIntsetObject负责创建intset编码对象,intsetAdd/intsetRemove/intsetRandom分别对应增、删、随机取。这三个增删操作全都依赖intsetSearch来定位元素——所以二分查找才是整个intset的算法核心,也是它O(log n)性能的来源:intsetAdd靠intsetSearch返回的"应插入位置"来维持升序,intsetRemove靠它定位待删元素的下标。换句话说,只要把intsetSearch写对,其余操作就自然通了。
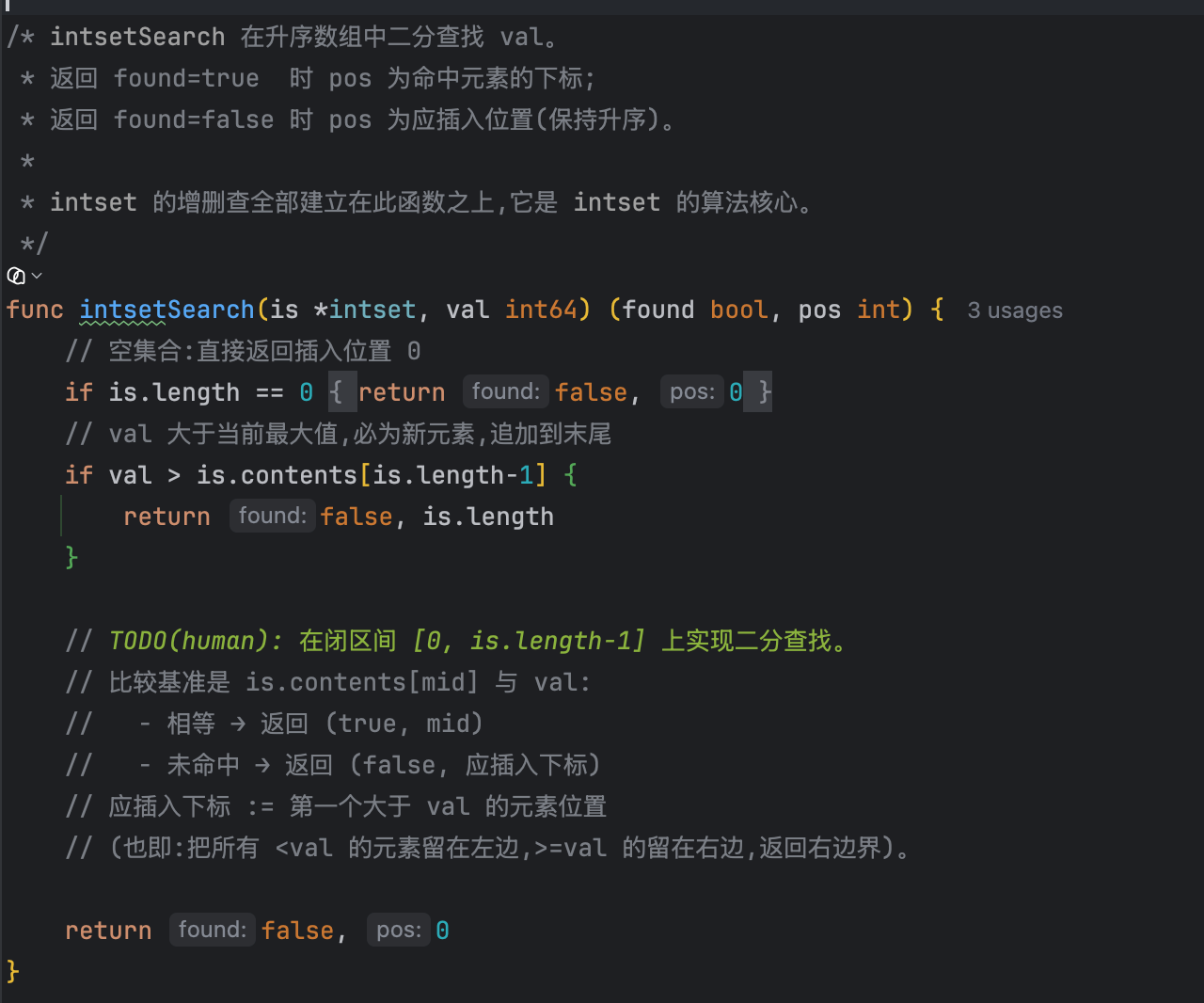
正因如此,claude code把这些不复杂的骨架代码留给自己实现,而把最核心的intsetSearch二分查找以TODO(human)的形式交给我们:函数已经替我们处理好两个边界(空集合返回(false, 0)、val大于最大值返回(false, is.length)),我们只需在闭区间[0, is.length-1]上补全标准二分——命中返回(true, mid),未命中返回(false, 应插入的下标)。
值得一提的是,claude code特意指出了一个语言层面的差异:Go不像C那样可以直接对内存字节做指针运算,因此intset"按字节位宽逐档升级、整体重新编码"的底层实现,在Go里并不适合原样实现。所以它将编码升级这部分用Go原生的整型切片做了语义化保留,把真正需要我们手写的重心集中到二分查找上。
针对这段输出,笔者认为:大部分重构、尤其是跨语言复刻类的任务,都需要先结合现有技术栈对需求做一次评估,判断哪些设计能直接沿用、哪些必须按目标语言的特性重新取舍。这种评估能力,正是AI时代下一项很重要的判断力——AI能帮你把代码写出来,但要不要采纳、如何落地到自己的技术栈,最终还是得由工程师来定:
总之,我们要实现的就是一个O(log n)的二分查找,并保证整数集合始终有序且不重复——这正是intset增删查正确性的地基:

下面是learning mode给出的代码模板。可以看到,它把代码框架、边界判断,以及redis在算法上的一些微操都填好了。比如在正式进入二分查找前,它会先判断当前元素是否大于最大值,若是则直接返回false和数组长度,告诉上层"这个元素该追加到末尾"——用一个简单分支就把追加场景从O(log n)的二分查找降到了O(1):
结合需求和代码模板,笔者也拿纸和笔手动推演了一遍算法,来确认"找不到元素时,应返回大于val的最小元素的位置"这个行为。这里多说一句:理解一个算法最扎实的办法,往往就是拿纸笔自己走一遍。AI时代尤其要避免浮躁,学习这件事不能图快——AI提升的是你的效率,并不等于提升你的编程能力,真正长在自己身上的理解,还得靠一次次亲手推演换来。
假设有一个长度为5的有序数组,元素依次是0、1、2、3、5,现在要插入4。按要求,我们最终应返回"大于4的最小元素"的索引——也就是元素5所在的位置,即索引4。
第一轮:lo=0、hi=4,算出mid=(lo+hi)/2=2。此时contents[2]=2,小于val=4,说明目标在右半区,于是lo=mid+1=3,区间向右收缩:
第二轮:lo=3、hi=4,算出mid=3。contents[3]=3,仍小于val=4,所以lo继续前进,lo=mid+1=4:
第三轮:lo、hi都为4,算出mid=4。此时contents[4]=5,大于val=4,于是hi=mid-1=3。此时lo(4)>hi(3),触发循环终止。对照预期可以发现:找不到元素时返回lo,正好就是"大于val的最小元素"的位置。

于是笔者就仔细阅读工程的上下文,梳理claude code给出的思路和需要完成的逻辑部分,完成算法的填充:
/* intsetSearch 在升序数组中二分查找 val。
* 返回 found=true 时 pos 为命中元素的下标;
* 返回 found=false 时 pos 为应插入位置(保持升序)。
*
* intset 的增删查全部建立在此函数之上,它是 intset 的算法核心。
*/
func intsetSearch(is *intset, val int64) (found bool, pos int) {
// 空集合:直接返回插入位置 0
if is.length == 0 {
return false, 0
}
// val 大于当前最大值,必为新元素,追加到末尾
if val > is.contents[is.length-1] {
return false, is.length
}
// 在闭区间 [0, is.length-1] 上二分查找。
// 循环条件必须是 <= 而非 <:lo==hi 时仍需检查最后一个元素,
// 否则会漏掉"恰好落在末位"的命中,导致集合去重失效。
lo := 0
hi := is.length - 1
for lo <= hi {
mid := lo + (hi-lo)/2 // 防溢出写法,等价于 (lo+hi)/2
if is.contents[mid] == val {
return true, mid
} else if is.contents[mid] > val {
hi = mid - 1
} else {
lo = mid + 1
}
}
// 未命中:循环退出时 lo 恰好落在"第一个大于 val 的位置"。
// 注意返回 lo 而非 mid —— mid 是上一轮的旧值,已失效。
return false, lo
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
把写好的代码提交给AI后,它会先帮我们做一轮审查和修复,随后进入单元测试编写阶段——把笔者刚才没写到位的地方固化成测试用例,确保后续重构时能通过回归测试及时发现问题。
这其实正是learning mode让人学得扎实的关键:你每写一段代码,都能立刻拿到一次正向、高效的反馈——写对了有测试兜底,写错了有审查纠偏,学习闭环转得很快,比闷头写、写完还不知道对错的方式高效得多。
这里重点说说AI编写单元测试的思路(注意是思路,不是具体代码)。如果换成我们自己写,无非就是想清楚四件事:测什么、怎么写、验收什么、标准是什么。AI正是这么一步步推的。
先想"测什么"。它没有盯着代码行去凑覆盖率,而是回到intset的行为契约,锁定两个最容易出错、也最能体现设计意图的点:一是去重幂等,二是编码升级的边界。
再想"怎么写用例"。针对去重,它构造"同一个元素加两次"的场景,先add(5)再add(5)。针对编码升级,它构造"逐档越界"的场景,依次加入1、40000、3000000000,刚好把int16、int32、int64三档边界各踩一遍。
最后是"验收什么、标准是什么"。每个用例都钉死明确的预期值:首次add(5)应返回1,重复add(5)应返回0,去重后length应为1。编码升级则断言每加入一个越界值后,is.encoding依次等于INT16、INT32、INT64,跑出来不符就报错。
可以看到,好的测试不是凭感觉堆数量,而是先想明白"要验证哪条行为、喂什么输入、期望什么输出"。这套从行为和边界出发的思考方式,本身就很值得我们学过来:
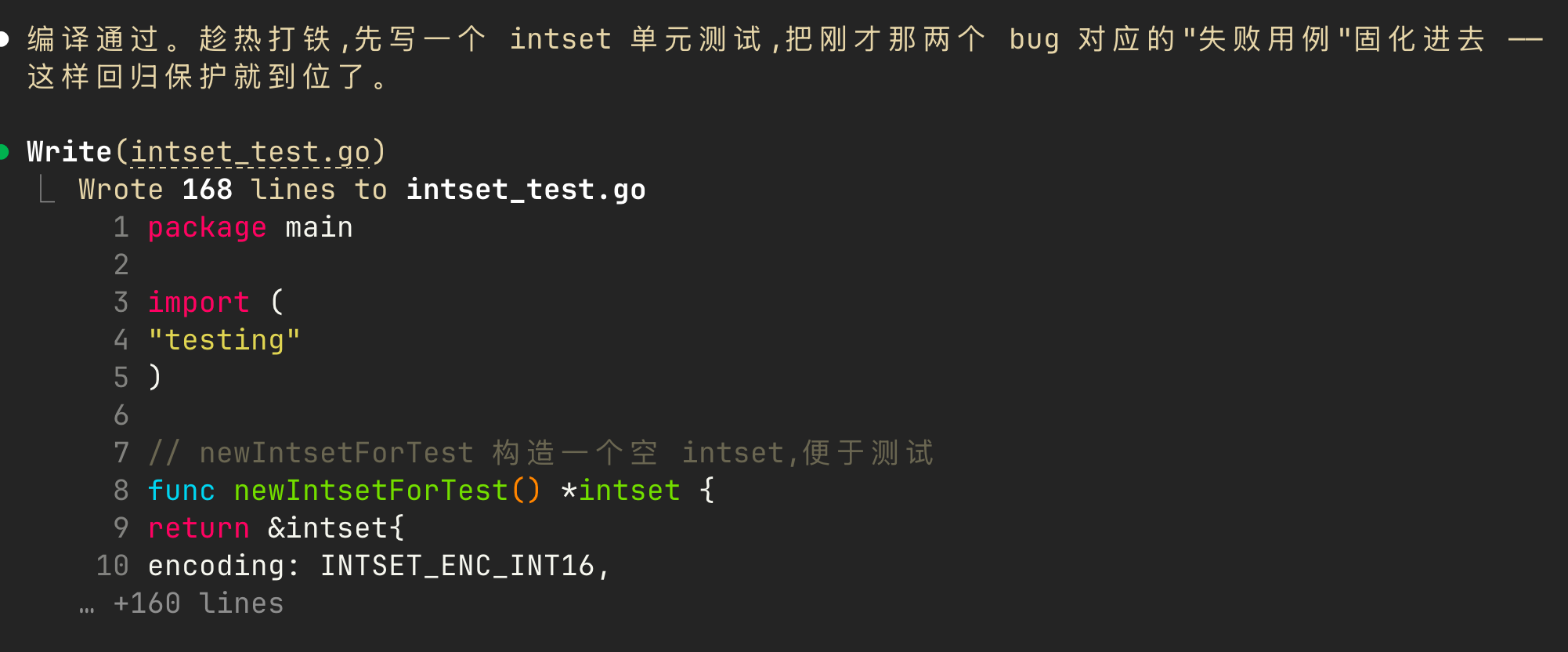
对应的单元测试如下。这些繁琐但必要的覆盖用例,learning mode都替我们写齐了,既帮我们完成最后的验收,也方便编码结束后回头把这些逻辑系统地梳理一遍、巩固理解。对应代码如下,可以看到,claude code针对每一个都进行的基础和边界角度的全方面覆盖,并通过终态断言确保测试结果的准确性:
// 重复添加同一元素判断是否幂等处理(返回 0,集合不变)
func TestIntsetAdd_Dedup(t *testing.T) {
is := newIntsetForTest()
//重复添加两次5,断言第二次输出0
if intsetAdd(is, 5) != 1 {
t.Error("首次添加应返回 1")
}
if intsetAdd(is, 5) != 0 {
t.Error("重复添加应返回 0(幂等)")
}
// 通过set数量终态判断去重是否生效
if is.length != 1 {
t.Errorf("去重后 length = %d, want 1", is.length)
}
}
// 测试删除元素
func TestIntsetRemove_Basic(t *testing.T) {
is := newIntsetForTest()
//插入元素
for _, v := range []int64{1, 3, 5, 7} {
intsetAdd(is, v)
}
//移除3 判断返回索引是否为1
if intsetRemove(is, 3) != 1 {
t.Error("删除存在的元素应返回 1")
}
//创建快照单元测试,比对移除结果是否准确
got := intsetSnapshot(is)
want := []int64{1, 5, 7}
for i := range want {
if got[i] != want[i] {
t.Errorf("after remove(3): contents[%d] = %d, want %d", i, got[i], want[i])
}
}
//删除不存在的元素,覆盖边界
if intsetRemove(is, 100) != 0 {
t.Error("删除不存在的元素应返回 0")
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
它同时也详细说明了intset这个512阈值设计的初衷。结合它的分析和笔者的经验来看,这个阈值大概率是设计者经过多场景压测推导出来的:本意是让小整数集合保持紧凑、元素连续存放,这样二分查找时更多元素能直接命中CPU cache line,在缓存行内就完成检索,避免缓存未命中后再到内存加载的耗时开销:

# go map与原生dict的取舍
完成单元验收后,claude code会帮我补完剩余的逻辑。而真正考验工程师的地方,这时才到——AI时代里,我们亲手敲代码的比例确实在降低,但对代码好坏的判断力、对编程语言底层的理解功底,反而变得更稀缺、也更可贵。这恰恰是机器替代不了、只能靠长期积累换来的部分。读过笔者mini-redis系列的朋友想必都记得,当初复刻scan指令时,为了配合dictScan算法,笔者在mini-redis里完整地复刻过dict这一数据结构。
在走查claude code对sadd指令的实现时,笔者发现:它并没有像我那样用dict来实现非整数集合,而是直接用go map来承载set。这是为什么呢?
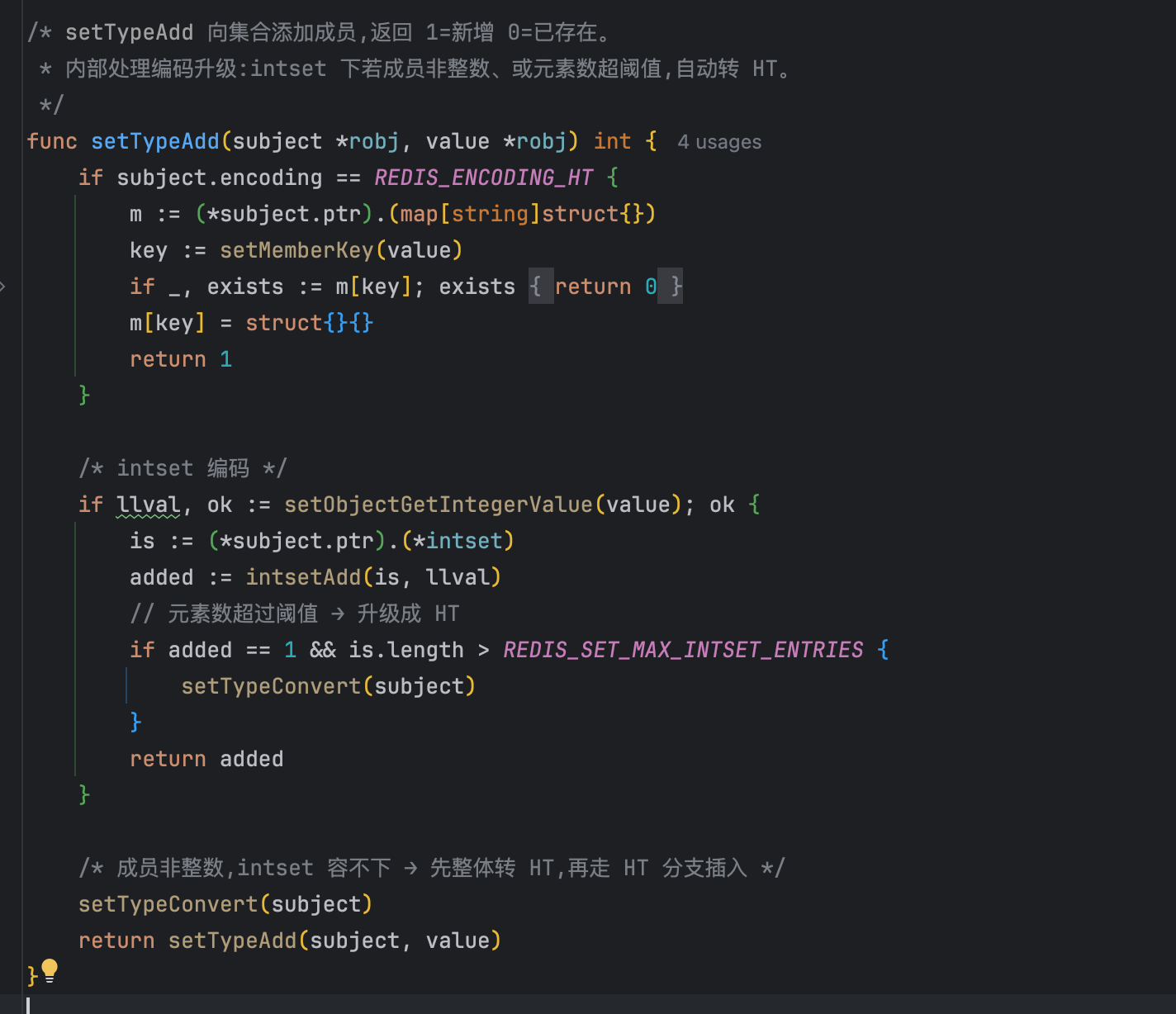
首先要明确一点:这个选择并不是因为上下文过长、被稀释而做出的错误决策,而是claude code有意为之——所以它值得我们认真理解。以本次set的哈希编码为例,redis本质上是内存数据库,把数据放内存就是为了减少磁盘IO、提升读写性能。 而在企业级系统里,redis大多是读多写少:热点数据往往靠服务启动时预热,或通过监听数据库binlog(如Canal)异步刷新,绝大部分时间redis都在承载读请求。所以set这种哈希结构的设计,要尽可能向读性能倾斜。
我们先说dict,它是redis内置的哈希表,特点是:
- 底层由数组+链表组成,用拉链法解决哈希冲突
- 每个entry(节点)同时存key和value
- 当负载因子过高、冲突变多导致读写变慢时,会触发扩容:分配一个约2倍大小的新数组,再用渐进式rehash把元素一点点迁过去(迁移成本摊到每次读写中,不阻塞单线程主流程),全部迁完后,只需把新数组的桶指针赋给ht[0]、并将rehashidx置为-1即可完成切换——这一步不拷贝数据、代价O(1),又因单线程串行执行不会被其它命令打断,对客户端呈现为一次原子替换

对照redis源码(dict.h)能更直观地印证这几点:
// dictEntry: 哈希表的节点, 对应"每个 entry 同时存 key 和 value"
typedef struct dictEntry {
void *key; // 键
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v; // 值(联合体, 兼容多种类型)
struct dictEntry *next; // 指向同槽下一个节点 —— 拉链法靠它解决冲突
} dictEntry;
// dictht: 一张哈希表
typedef struct dictht {
dictEntry **table; // 数组, 每个槽挂一条 dictEntry 链表
unsigned long size; // 数组容量(总是 2 的幂)
unsigned long sizemask; // size-1, 用按位与代替取模来定位槽
unsigned long used; // 已存节点数, 用来算负载因子
} dictht;
// dict: 对外的字典
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2]; // 两张表: ht[0] 平时用, ht[1] 扩容时用
long rehashidx; // 渐进式 rehash 的进度; -1 表示当前没在 rehash
// ... 省略迭代器等字段
} dict;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
而go map是go语言内置的哈希表,也是本次讨论的重点。下面结合runtime源码,一个特点配一段核心结构来看。
它底层是一个长度为2^B的bucket数组(长度取2的幂,是为了用位运算快速定位桶)。对应hmap结构体的核心字段,正好和下图一一对应:
type hmap struct {
count int // 当前元素个数, len(map) 直接返回它(图中 count=5)
B uint8 // bucket 数量的对数, 数组长度 = 2^B; 图中 B=3 即 8 个桶
buckets unsafe.Pointer // 指向这 2^B 个 bucket 组成的数组(图中 buckets[8])
oldbuckets unsafe.Pointer // 扩容时指向旧数组, 没在扩容时为 nil(图中即 nil)
hash0 uint32 // 哈希种子
// ... 省略 noverflow / flags 等字段
}
2
3
4
5
6
7
8
如下图,hmap 通过 buckets 指向一个 8 个桶的数组(b0~b7),当前一共存了 5 个元素,其中 b0 里装了 3 个,我们接着展开 b0 看它内部长什么样:
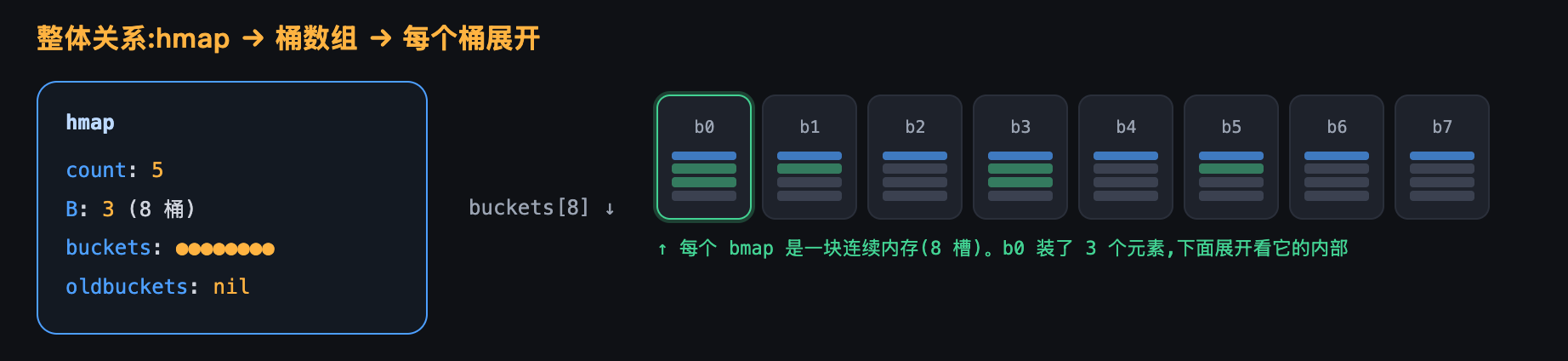
数组里每个元素就是一个bucket,也就是一个bmap——它才是真正存键值对的地方。一个bmap固定有8个槽,装满后再通过overflow指针挂一个溢出bmap接着存:
const bucketCnt = 8 // 一个 bucket 最多放 8 个键值对
type bmap struct {
tophash [bucketCnt]uint8 // 8 个 key 哈希的高 8 位, 用于快速比较
// 编译期会在后面依次追加:
// keys [8]keyType 8 个 key 连续存放
// values [8]valueType 8 个 value 连续存放
// overflow *bmap 指向溢出 bmap, 槽满了才用到
}
2
3
4
5
6
7
8
9
这里要特别留意它的内存布局:并不是"key、value 交替排列",而是 8 个 tophash、8 个 key、8 个 value 各自成段连续存放,最后跟一个 overflow 指针。而且 key 是内联存放的——以字符串 key 为例,直接把 stringHeader 排在 keys 段里,没有再绕一层指针。这种"key 归 key、value 归 value、且内联无间接"的布局,既减少了内存对齐的填充浪费,也让扫描 key 时内存高度连续,后面分析读性能时还会用到这一点:
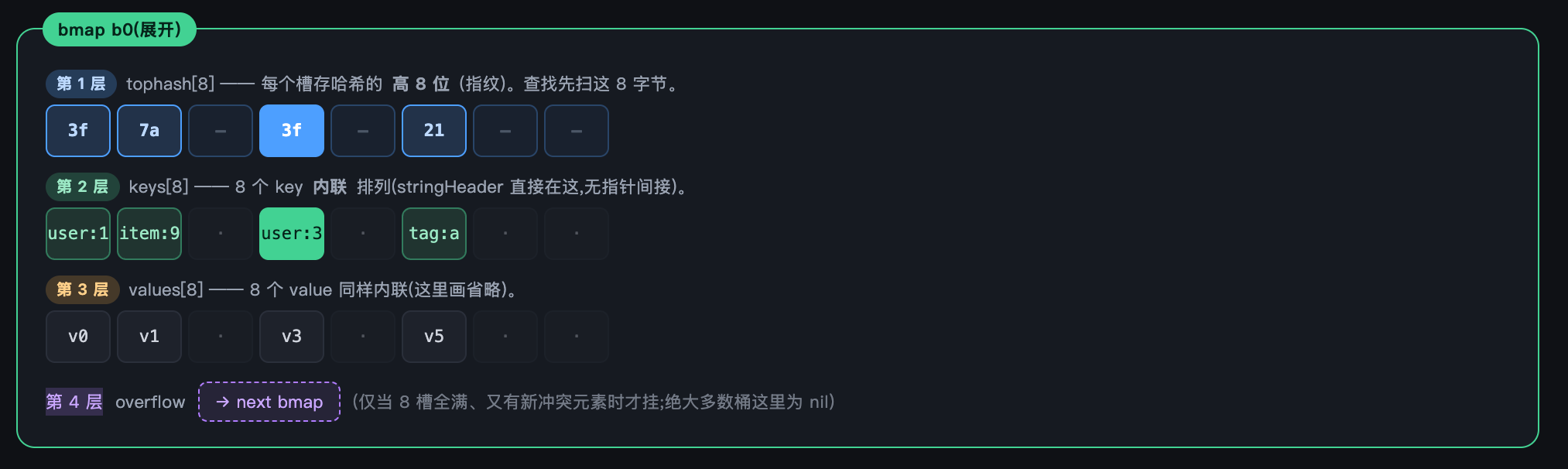
以写入 user:3 为例,go map 的步骤是:
- 计算哈希:h = memhash("user:3", hash0),得到 64 位,例如 0x3f...a1000
- 定位 bucket:bucket = h & (1<<B - 1) = h & 7 = 0,走到 b0(用哈希低位选桶)
- 取指纹:top = uint8(h >> 56) = 0x3f(用哈希高位当 1 字节指纹)
- 在 b0 里找一个空槽(比如槽 3),写入 tophash[3]=0x3f、keys[3]="user:3"、values[3]=v3
- 若 b0 的 8 个槽都满了,就沿 overflow 指针走到下一个溢出 bmap,再找空槽写入
与之对应的读请求也是同理,假设我们需要寻找key为user:3的元素,对应步骤为:
- 计算哈希:h = memhash("user:3", hash0)→ 得 64 位,例如 0x3f...a1000
- 定位bucket:bucket = h & (1<<B - 1) = h & 7 = 0 → 走到 b0(用哈希低位选桶)
- 取指纹:top = uint8(h >> 56) = 0x3f(用哈希高位当 1 字节指纹)
- 扫b0的tophash[8],逐个比单字节。槽0的指纹是3f,和目标撞上了,于是去比较完整key,发现keys[0]="user:1"并不是"user:3"——指纹相同但key不同,继续往下。槽3的指纹也是3f,再比较keys[3]="user:3",这回完整key也相等,命中。
- 返回values[3]。若8个槽都扫完仍没命中,就沿overflow指针走到下一个桶,重复第4步。
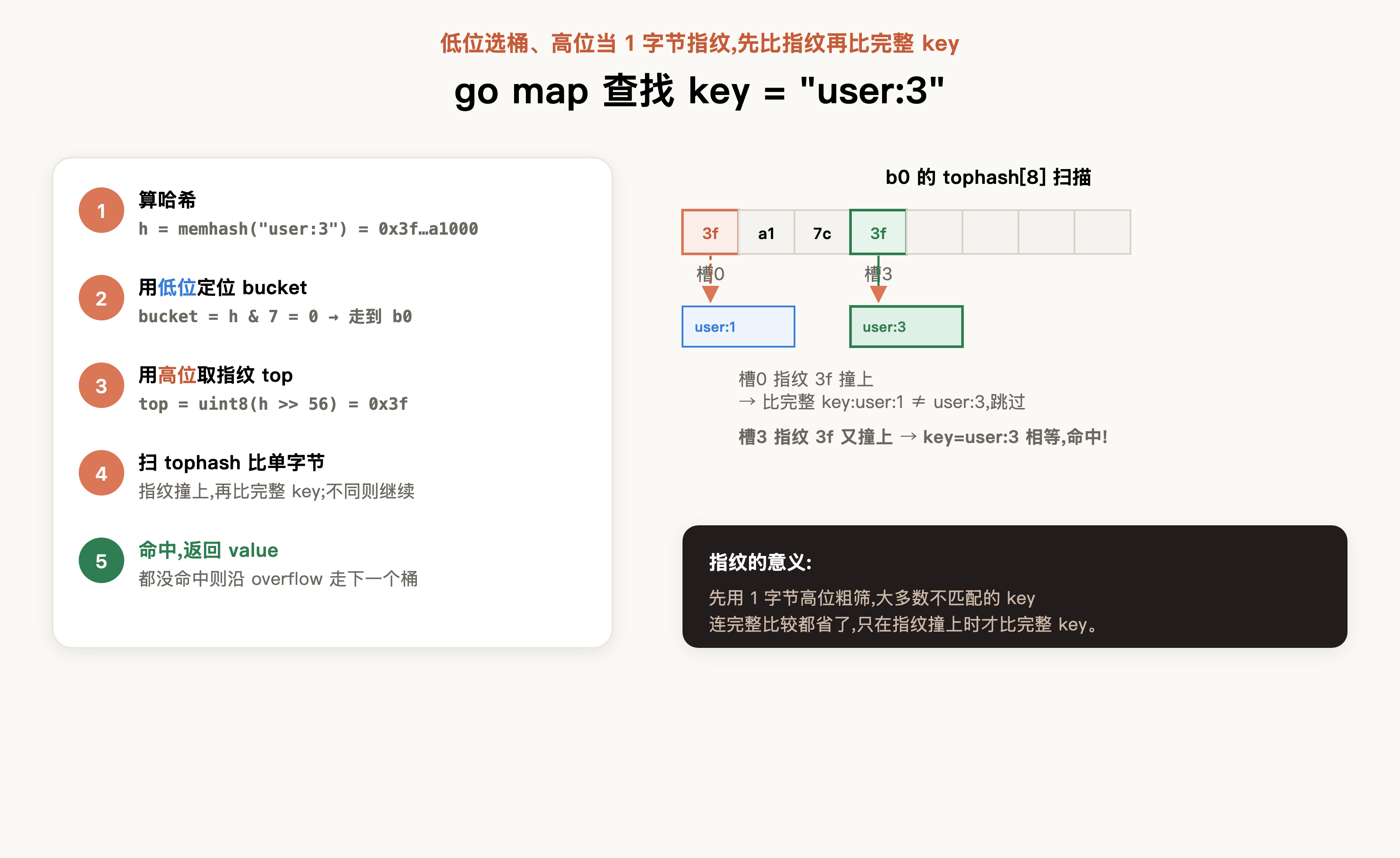
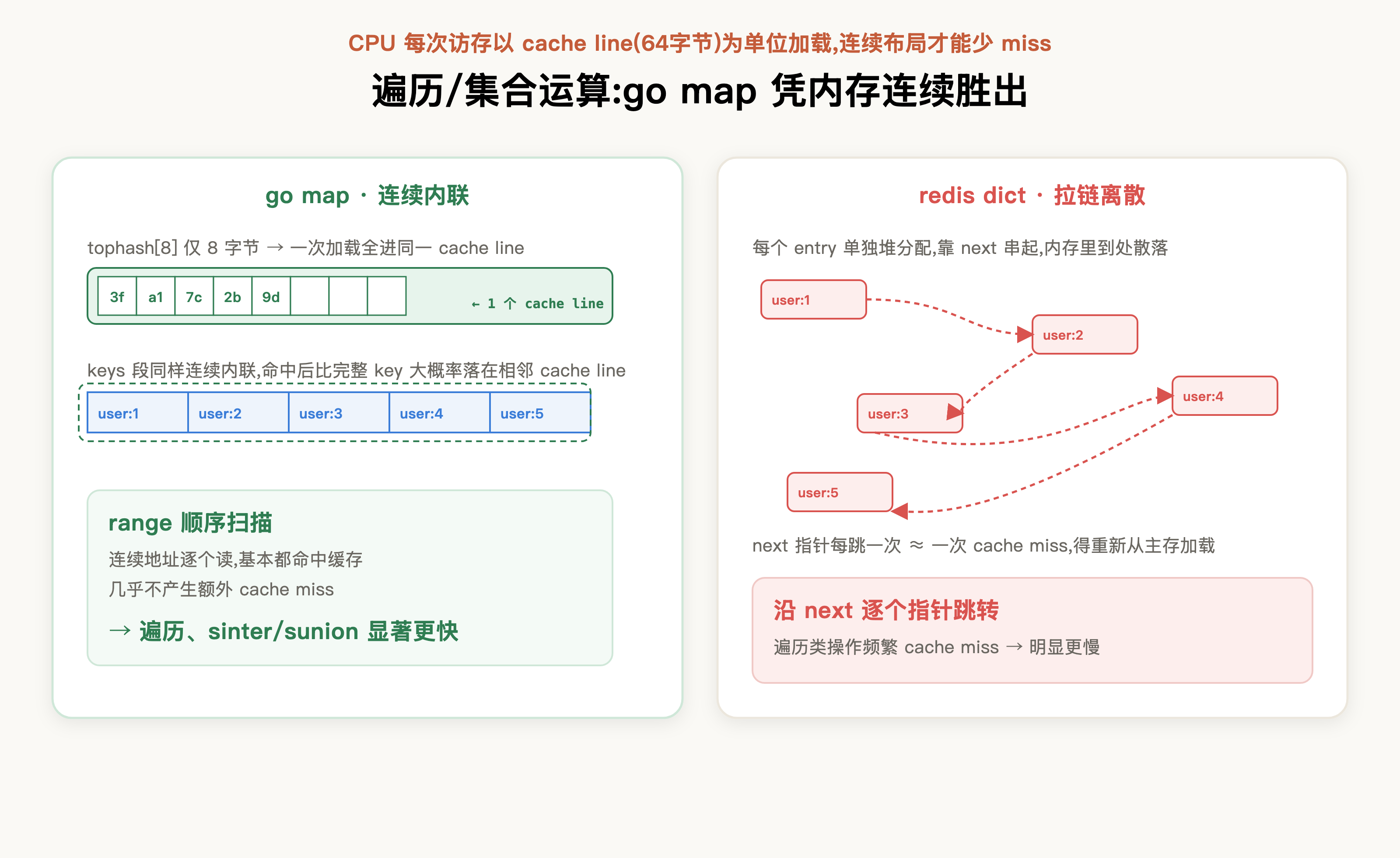
不难看出,go map因为内存连续性对CPU缓存非常友好,我们都知道,CPU每次访存都是以cache line(通常64字节)为单位加载的。
而tophash[8]只有8字节,一次加载就能把整段指纹读进同一个cache line,扫描指纹基本不仅不会产生额外的cache miss,还能够快速筛选掉一些不匹配元素。只有当指纹命中后,go map比对的完整key,由于keys段同样连续内联存放,大概率落在相邻的cache line里。也就是说,当需要连续迭代或做基于set的集合运算时,go map凭更高的缓存命中率能更高效地完成遍历和运算。
所以在dict和go map哈希都分布均匀的前提下,单值查询凸显不出go map的优势,但涉及sunion、sdiff、sinter这类集合运算时,它会有显著的性能优势:
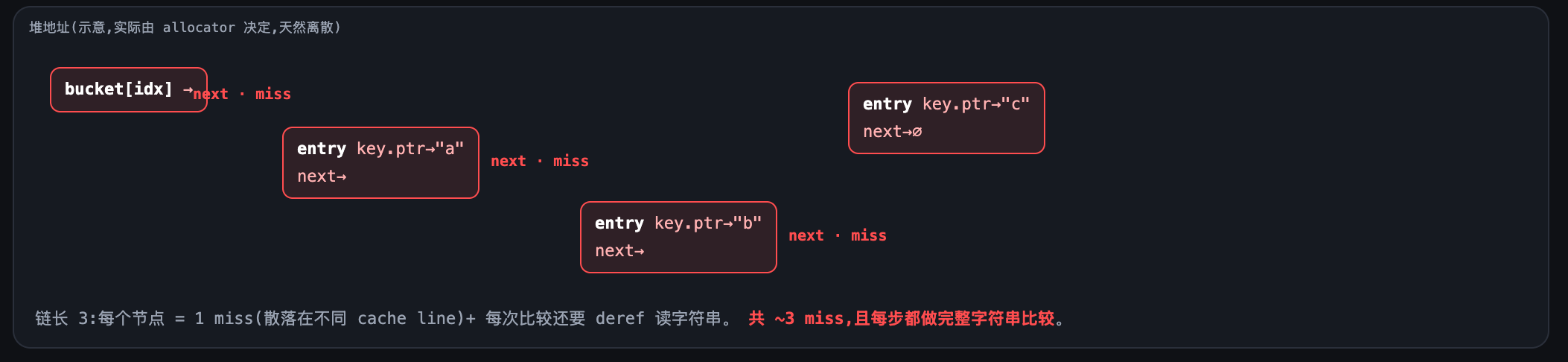
对比之下,redis dict用的是拉链法:每个entry都是单独分配、靠next指针串起来的节点,在内存里是分散的。所以冲突时每比对一个entry,往往就是一次指针跳转加一次cache miss,得重新从主存加载:
能不能看懂这些底层细节、并据此做出合理取舍,正是AI时代工程师的核心能力。回到当前的set集合:它读多写少,而go map又是go语言的原生结构、不存在跨语言移植的妥协,所以在非整数编码这一支,优先用go map来承载,是更合适的选择。
为了印证上面这套取舍并非AI的幻觉式论断,笔者特意写了一段基准测试,针对dict和go map分别覆盖三类场景:
写入(Add/SADD)
哈希定位(IsMember/SISMEMBER)
全量迭代(Iterate/SMEMBERS)
对应的测试代码如下,读者可结合注释了解各个代码段含义:
func BenchmarkSet(b *testing.B) {
const n = 100000
// SADD:测试dict和go map写入性能
b.Run("Add/dict", func(b *testing.B) {
for i := 0; i < b.N; i++ {
d := dictCreate(&dbDictType, nil)
for j := 0; j < n; j++ {
k := "m:" + strconv.Itoa(j)
dictAdd(d, createStringObject(&k, len(k)), nil)
}
}
})
b.Run("Add/gomap", func(b *testing.B) {
for i := 0; i < b.N; i++ {
m := make(map[string]struct{})
for j := 0; j < n; j++ {
m["m:"+strconv.Itoa(j)] = struct{}{}
}
}
})
d := dictCreate(&dbDictType, nil)
m := make(map[string]struct{}, n)
for j := 0; j < n; j++ {
k := "m:" + strconv.Itoa(j)
dictAdd(d, createStringObject(&k, len(k)), nil)
m[k] = struct{}{}
}
// 测试 dict和go map键值对检索性能
b.Run("IsMember/dict", func(b *testing.B) {
for i := 0; i < b.N; i++ {
if dictFind(d, "m:"+strconv.Itoa(i%n)) == nil {
b.Fatal("miss")
}
}
})
b.Run("IsMember/gomap", func(b *testing.B) {
for i := 0; i < b.N; i++ {
if _, ok := m["m:"+strconv.Itoa(i%n)]; !ok {
b.Fatal("miss")
}
}
})
// 测试dict和go map迭代性能
b.Run("Iterate/dict", func(b *testing.B) {
for i := 0; i < b.N; i++ {
cnt := 0
it := dictGetIterator(d)
//需逐桶遍历,跨指针跳跃,cache miss概率高,性能表现差
for de := dictNext(it); de != nil; de = dictNext(it) {
cnt++
}
dictReleaseIterator(it)
if cnt != n {
b.Fatalf("want %d got %d", n, cnt)
}
}
})
b.Run("Iterate/gomap", func(b *testing.B) {
for i := 0; i < b.N; i++ {
cnt := 0
//go map桶内key value连续存储,cache line友好
for range m {
cnt++
}
if cnt != n {
b.Fatalf("want %d got %d", n, cnt)
}
}
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
运行go test -run=^$ -bench=BenchmarkSet,输出如下:
goos: darwin
goarch: arm64
pkg: mini-redis
cpu: Apple M4
BenchmarkSet/Add/dict-10 68 17290798 ns/op
BenchmarkSet/Add/gomap-10 181 6514517 ns/op
BenchmarkSet/IsMember/dict-10 22881913 47.46 ns/op
BenchmarkSet/IsMember/gomap-10 26038864 45.74 ns/op
BenchmarkSet/Iterate/dict-10 1434 740907 ns/op
BenchmarkSet/Iterate/gomap-10 2030 597758 ns/op
2
3
4
5
6
7
8
9
10
三组用例都按完全相同的方式装入十万个成员、各自原样计时,是一次公平对照。看ns/op这一列(每次操作耗时,越小越快),三类场景结论各不相同:
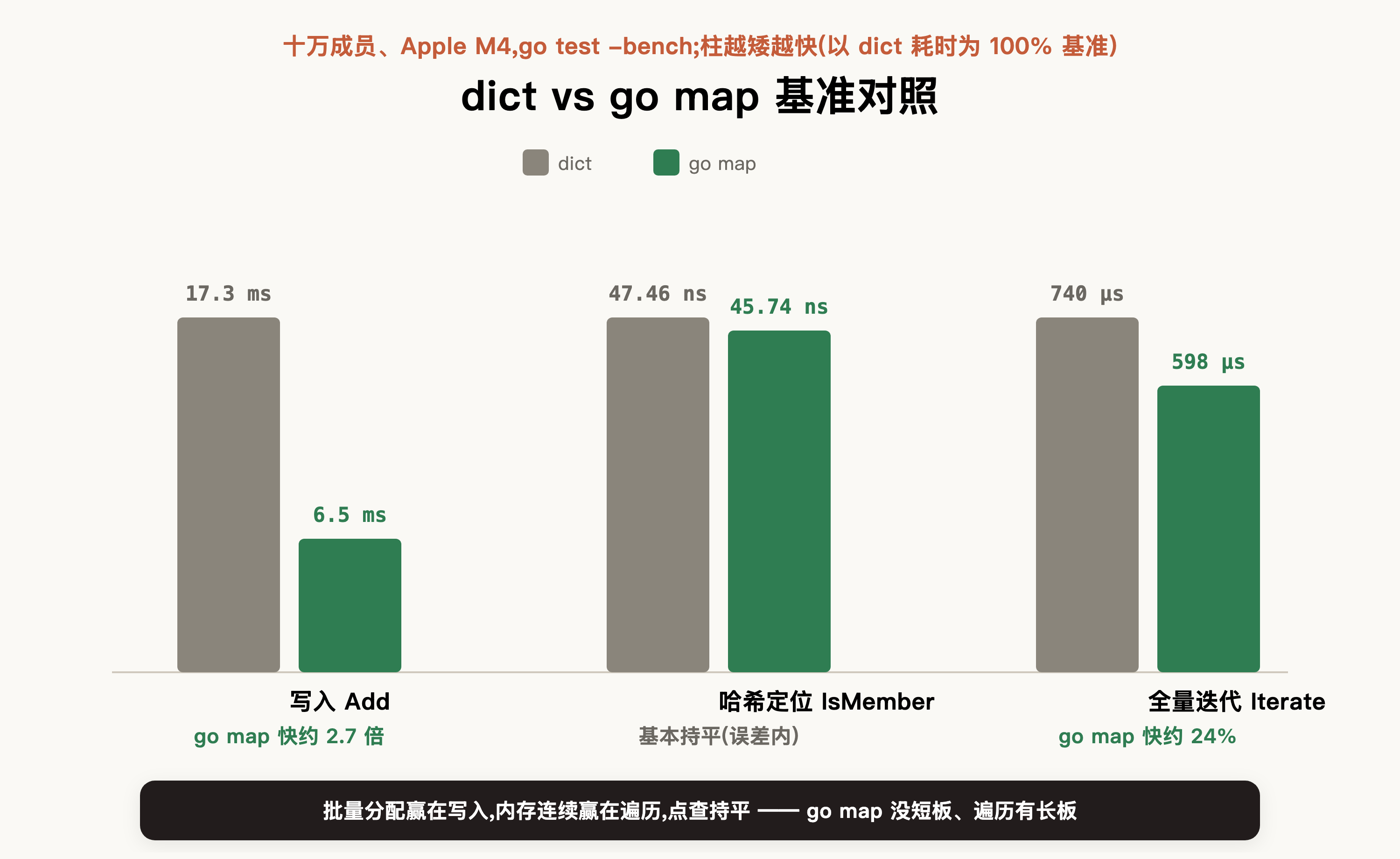
- 写入(go map 快约 2.7 倍):dict每加一个成员,都要单独在堆上分配一个entry节点挂到链表上——十万次插入累计就是几十万次离散堆分配;扩容时还要沿
next指针把散落在堆上的旧节点逐个重挂到新表(渐进式rehash)。go map则把entry内联进连续的桶数组,按桶批量分配、扩容时整段连续内存一次性搬迁,几乎不为单个元素单独分配。这2.7倍直接来自分配次数:dict要做几十万次离散malloc,go map按桶批量分配把malloc调用摊薄到极少,写入路径本身就更快。而离散对象、指针更少还带来一层附加收益——GC标记阶段要扫描的更少,CPU占用和STW停顿随之下降,长时间高频写入下吞吐也更稳。 - 哈希定位(基本持平):哈希函数把key散得足够均匀、单桶链长接近1时,一次点查无非"算哈希 + 定位桶 + 比较key",二者都是O(1),本质同一量级。47.46 vs 45.74 ns的差距(~3.6%)在误差范围内,基本可视为持平,谁快谁慢不必深究。
- 全量迭代(go map 快约 24%):这一项才真正体现内存连续的价值——go map的键连续内联存放,
range顺序扫描基本都命中CPU缓存;dict则要沿next指针逐个跳转散落在堆上的entry,每跳一次都可能是一次cache miss。而set的典型场景,恰恰大量依赖SMEMBERS、以及sinter/sunion这类需要整体遍历的集合运算,这一项优势会被实打实放大。
归纳起来,go map的优势来自两点:
- 批量分配让它赢在写入(GC负担轻是顺带的好处),
- 内存连续让它赢在遍历
结合压测报告来看,go map的连续内存布局让它在遍历类操作上明显占优(SMEMBERS、sinter/sunion这类整体扫描最吃cache line),写入上又靠批量分配赢下GC开销,点查则与dict基本持平。综合下来go map没有短板、遍历有长板,这也是笔者审查AI代码时保留用go map作为set哈希编码结构的原因。
# 集合运算
完成核心查找和常见指令的代码审查后,我们就可以基于当前数据结构,进一步实现集合运算。claude code结合源码逐一说明了这几个运算指令的含义:
- sunion:求两个set的并集
- sdiff:求两个set的差集
- sinter:求多个set的交集。这是claude特意点明的重点——计算交集时,它会先挑出元素最少的那个集合,以它为基准遍历,再到其他集合里逐个判断是否存在,也就是典型的"小表驱动大表"
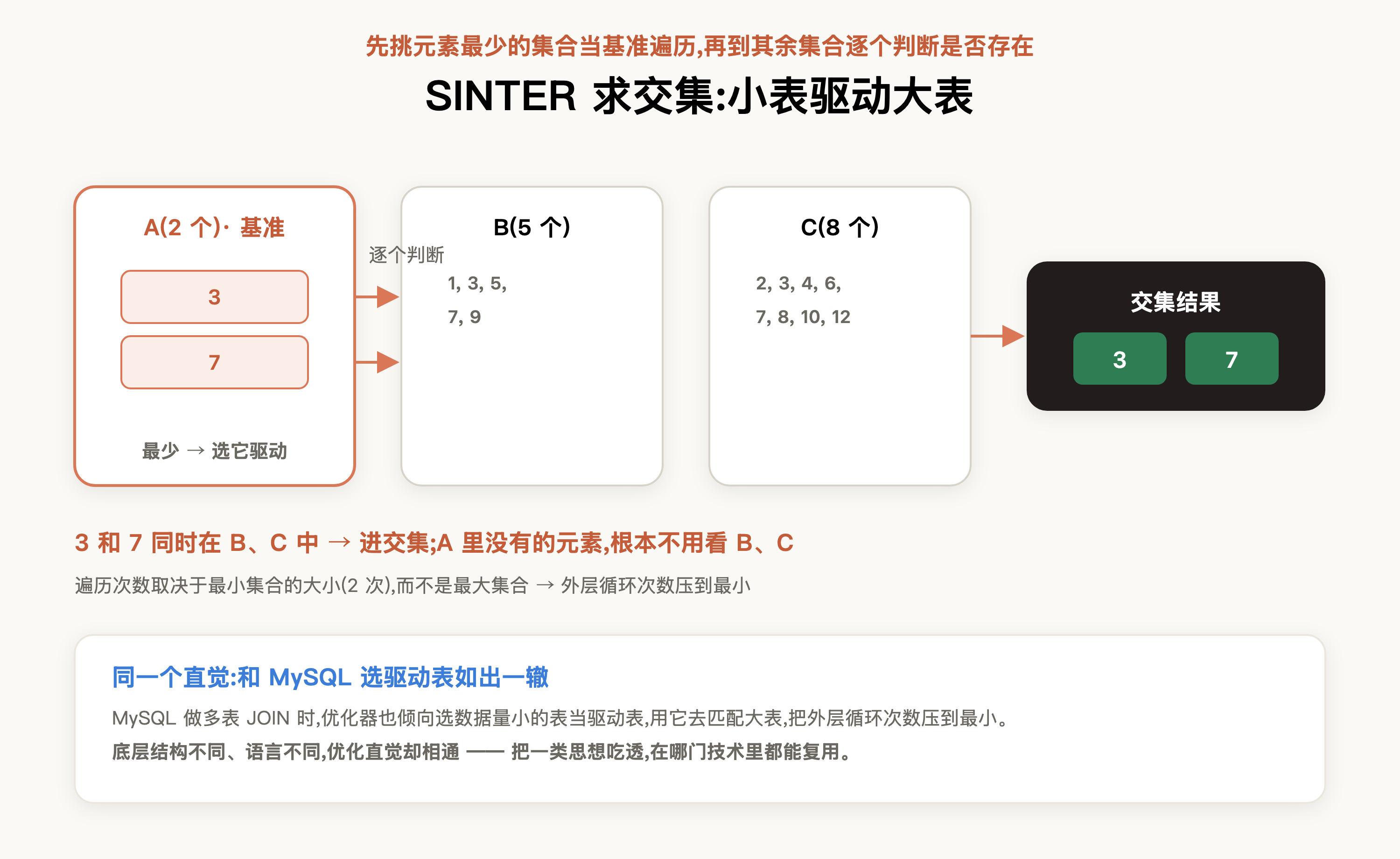
值得一提的是,这个"小表驱动大表"的思路,和MySQL的优化如出一辙:MySQL在做多表连接时,优化器也会倾向于选数据量小的表作为驱动表,用它去匹配大表,从而把外层循环的次数压到最小。底层数据结构不同、语言不同,优化的直觉却是相通的——这也是为什么把一类思想吃透后,在哪门技术里都能复用,很有学习意义:

所以在后续讲解里,claude对sunion、sdiff这类哈希天然友好的运算只是简单点明、直接写完,而把核心的sinter交给我们学习。它先把sinter的整体模板写好,再把其中负责"判断某个元素是否同时存在于其余所有集合"的isMemberOfAll函数交给我们实现,让我们主动去理解这个集合运算的核心算法,弄清楚intset(数值)和哈希表两种编码下,交集是如何被高效定位出来的:
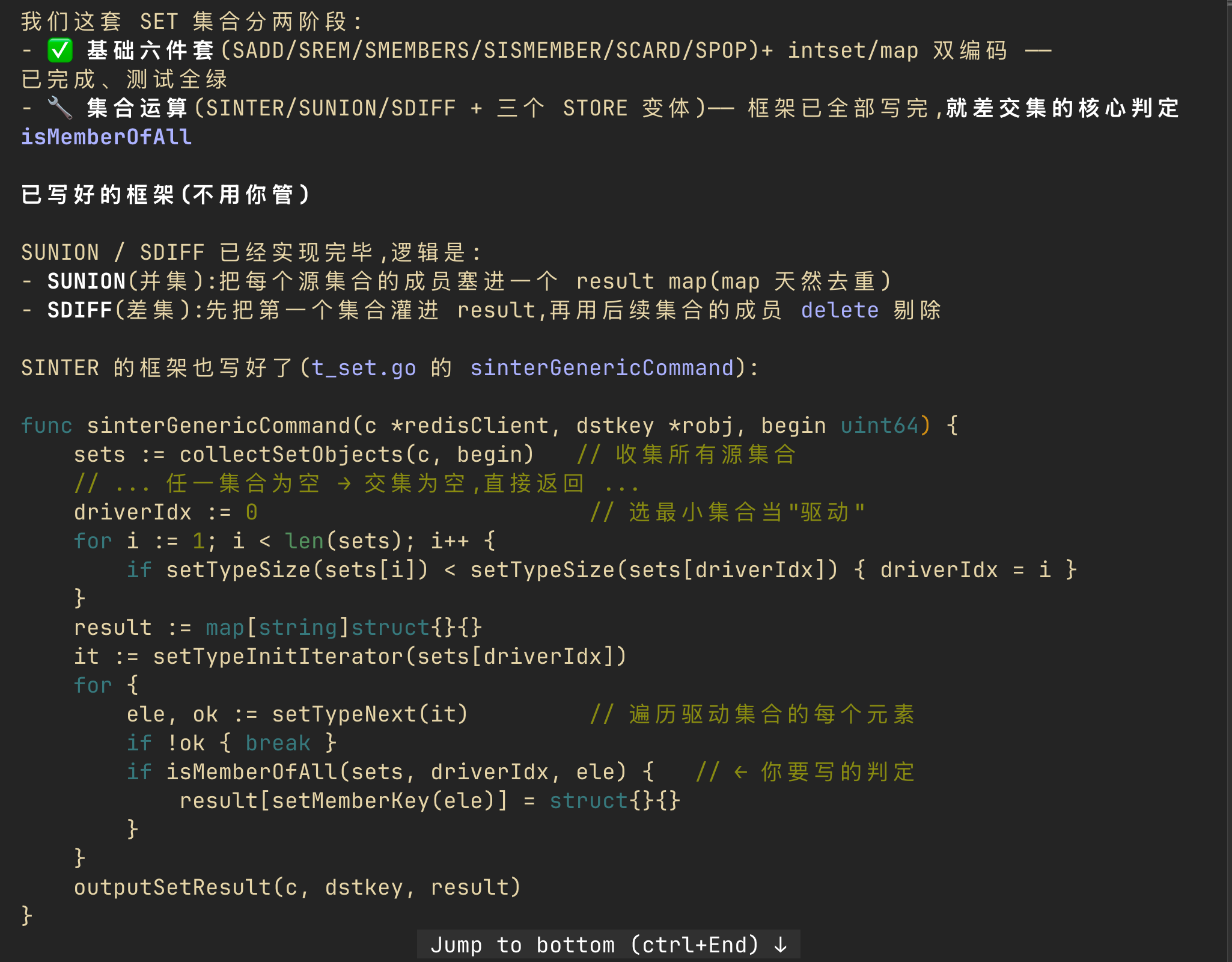
这种模式恰恰体现了learning mode的价值:它高度贴合企业真实的开发场景——在已有的复杂上下文里,让你独立写出核心逻辑,并保证它稳定运行。这背后考察的是几项硬能力:对现有上下文的理解、迭代式的思路设计,以及对整体结果的全局验收把控。以本次为例,笔者先读懂了isMemberOfAll之外的sinterGenericCommand,理清整体思路后,才动手编写核心的"判断元素是否存在"那段逻辑:
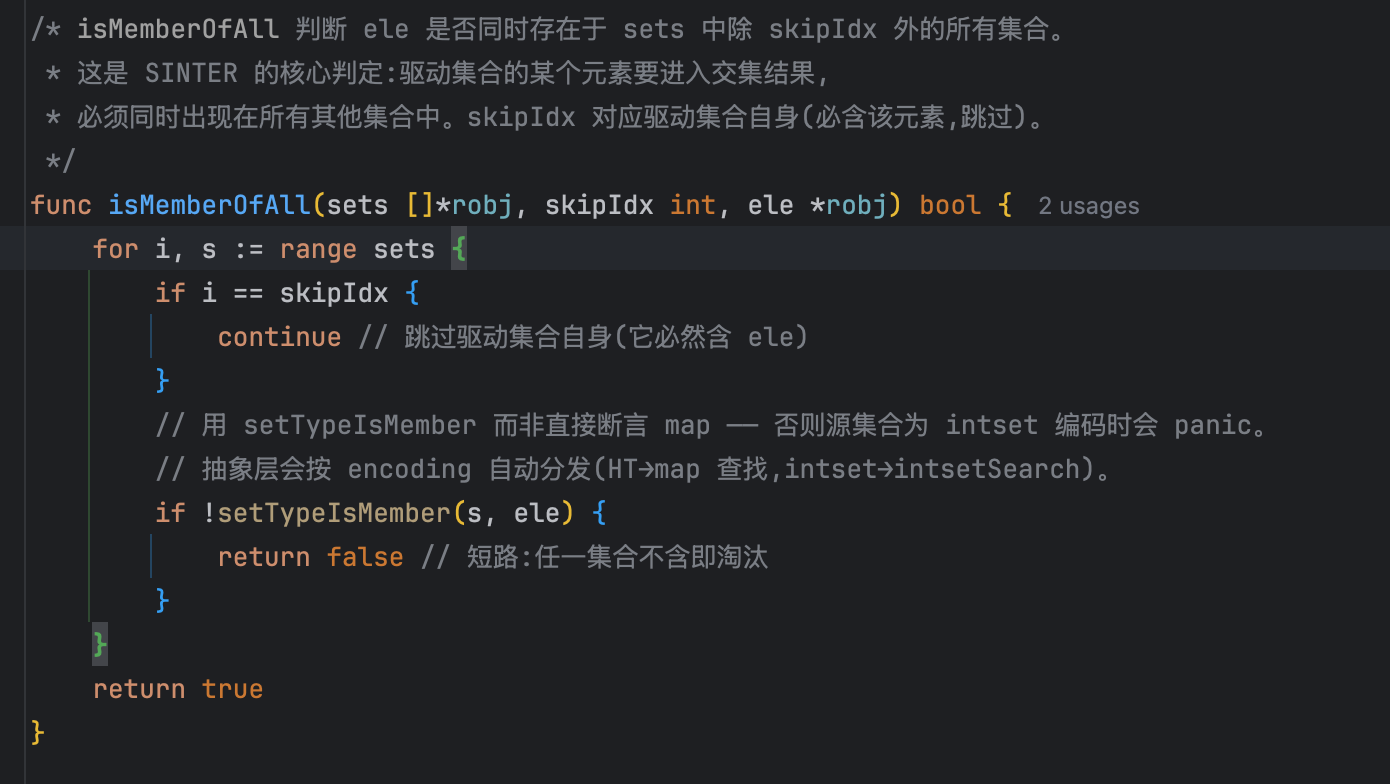
# 小结
回顾整篇,我们借助claude code的learning mode,完整复刻了redis set的双编码设计:整数场景用intset(有序数组 + 二分查找),非整数场景用哈希表(redis用dict,我们用go map),并亲手实现了二分查找、isMemberOfAll等几处最核心的算法。
learning mode最让笔者受用的一点,是它的分工:claude code会把那些繁琐、重复、对成长几乎没有收益的样板代码替我们写完,而把真正核心的算法留给我们,逼着我们主动去读懂需求和上下文,再亲手把这块逻辑填充进去。既省掉了无谓的体力活,又把学习的重心牢牢压在最该动脑的地方。
但比代码本身更值得带走的,是过程中反复出现的那条主线——技术判断力:
- 为什么set全整数时用intset而非哈希表?为什么编码升级是单向的?顺着规则多追问一层,才想得明白。
- 为什么非整数编码笔者用dict、claude却用go map?因为set读多写少,而go map内存连续、对CPU缓存友好,且是go原生、无跨语言妥协。能做出这个取舍,靠的是对底层的理解。
- sinter的"小表驱动大表",和MySQL选驱动表的优化如出一辙——把一类思想吃透,在哪门技术里都能复用。
AI把写代码的成本压到了极低,但"明确目标、读懂源码、做出合理取舍"这些能力,反而更稀缺、更可贵。别把学习外包出去:让AI当你的陪练和考官,而不是代笔——这才是AI时代真正划算的用法。
# 参考
- Don't Outsource the Learning:https://addyosmani.com/blog/dont-outsource-learning/ (opens new window)
- 别让AI替你学习:认知债务正在悄悄侵蚀你的竞争力:https://sotasync.com/reader/2026-05-18-dont-outsource-learning/ (opens new window)
- Your Brain on ChatGPT:https://arxiv.org/abs/2506.08872 (opens new window)
- t_set.c:https://github.com/redis/redis/blob/3.2/src/t_set.c (opens new window)
- intset.c:https://github.com/redis/redis/blob/3.2/src/intset.c (opens new window)
