 Go语言常见面试题解析(上)语言基础与核心概念
Go语言常见面试题解析(上)语言基础与核心概念
# 前言
如今基础语法、标准库用法、常见陷阱这些,AI已经答得又快又准,开发者更多时间不是在写代码,而是在长上下文里审查AI输出的代码。
面对AI输出的长上下文,即使是资深的开发者也很容易漏掉语言层面潜藏的bug。例如:你让AI实现一个并发场景,它顺手用了普通map做并发读写——编译能过、单测可能也过,可一上量就 fatal error: concurrent map writes 直接崩,这种坑得靠你懂"Go的map不是并发安全的、该加锁或换sync.Map",才能在review时揪出来、给AI的输出套上约束,说到底,前提还是你自己得真懂这些语言细节,
所以这篇面经讲的就是这些"AI容易漏、面试也爱考"的Go基础——每道题不只说"是什么",更带你搞懂它的工作原理和一些潜藏的使用风险,既能让你正确地配合AI高效完成编码,又能从容应对面试,
# Go 语言基础
# 为什么选择 Go 语言?
AI时代语言门槛低了,但选型能力反而更值钱,所以涉及编程语言的选择,我们需要从 "为了解决什么问题、做了哪些取舍、适合什么场景"角度出发。
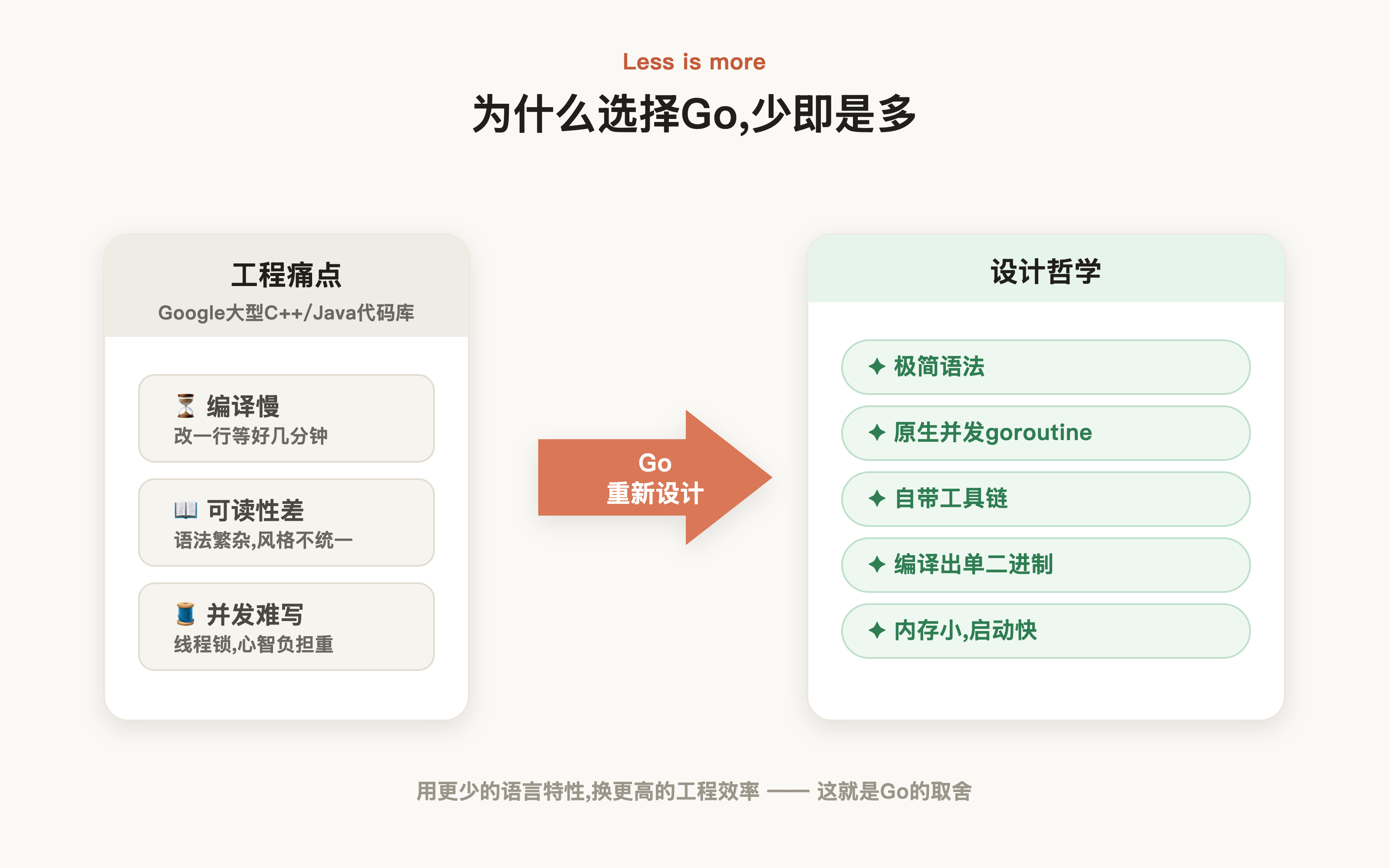
结合官方的"Why did you create a new language"可以看出,Go最初是为了解决Google内部大型C++和Java代码库在编译速度、代码可读性、并发编程上的工程痛点,自诞生起就奔着简单且高效去:

它的设计哲学可以归结为少即是多:
- 极简语法
- 原生并发
- 自带工具链
- 编译出单二进制
- 内存占用小、启动快
也正因如此,选型时一句话就能说清:云原生基础设施(Docker、K8s、Prometheus都是Go写的)、微服务/API网关、CLI工具、网络代理这类要高并发加快速部署、又没历史包袱的场景,优先用Go;而需要复杂类型系统和领域建模的企业应用,还是Java系更合适:
# Go 和 Java 有什么区别?
比较两门语言,与其纠结语法差异,不如从各自的设计理念和适用场景切入,这道题面试时,顺着语言设计、应用生态、性能表现三个角度展开就够清晰:
# 语言设计
我们先来说说语言设计上,Java在继承这一方面的设计上,通过extends关键字实现继承功能,同时,为避免菱形问题,直接采用单继承,这使得在面向对象的设计上,需要结合接口进行一些组合。
而 Go 则舍弃了继承体系,为保证语法实现上的简单,通过struct embedding(组合)实现代码复用,例如我们希望Dog类能够直接复用Animal的方法,就可以直接通过声明、组合、使用三个步骤完成类似于继承效果的设计:
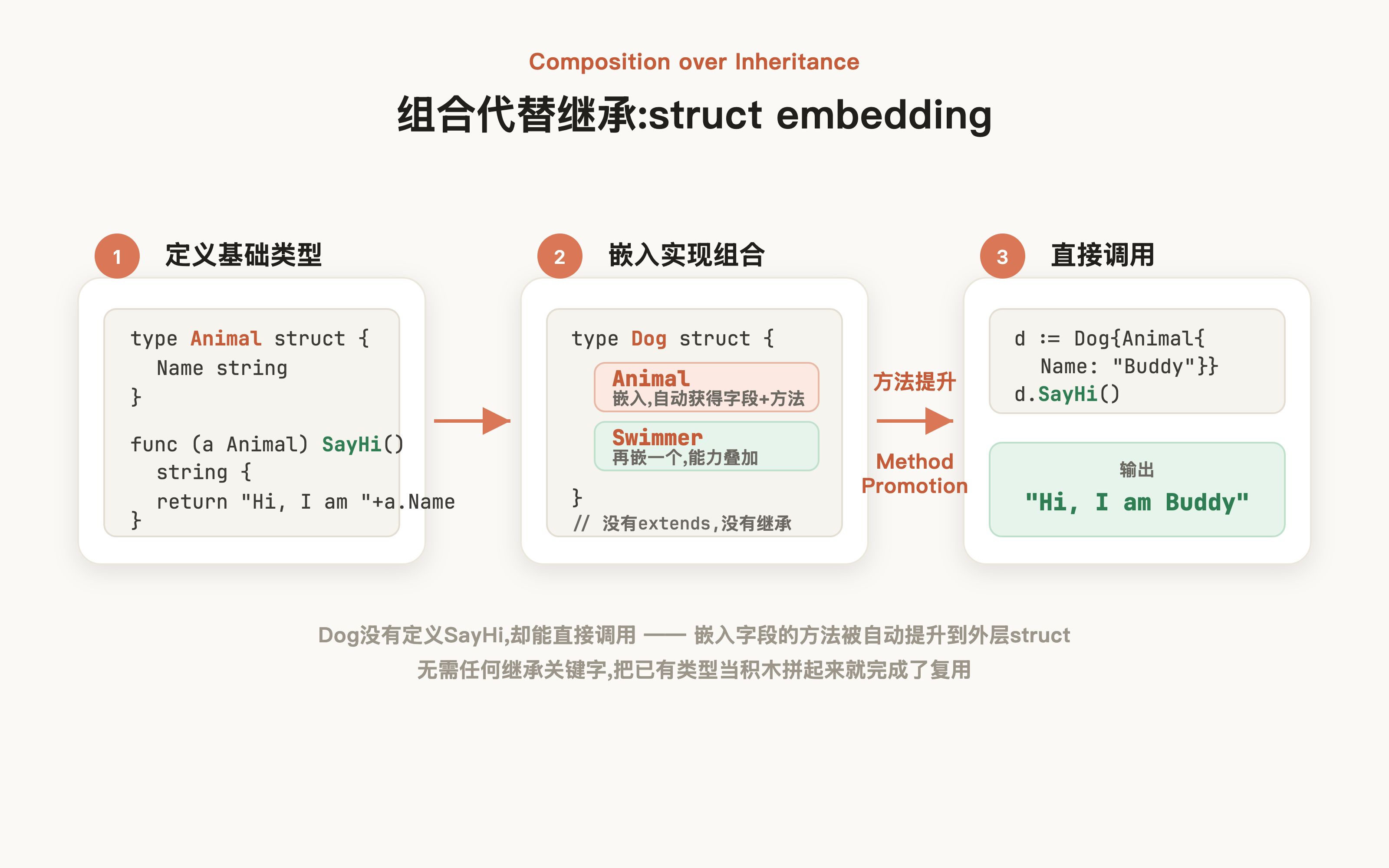
对应的编写步骤如下:
1. 声明Animal及SayHi方法:
type Animal struct {
Name string
}
func (a Animal) SayHi() string {
return "Hi, I am " + a.Name
}
2
3
4
5
6
7
2. 声明Dog并组合Animal
type Dog struct {
Animal
Swimmer
}
2
3
4
3. 初始化Dog,编译器自动做方法提升(Method Promotion),以达到类似于继承效果的直接调用,输出 Hi, I am Buddy
d := Dog{Animal: Animal{Name: "Buddy"}}
fmt.Println(d.SayHi()) // 直接调用 Animal 的 SayHi,输出 Hi, I am Buddy
2
3
对于多态性,Go 也是简单粗暴提出如下原则:
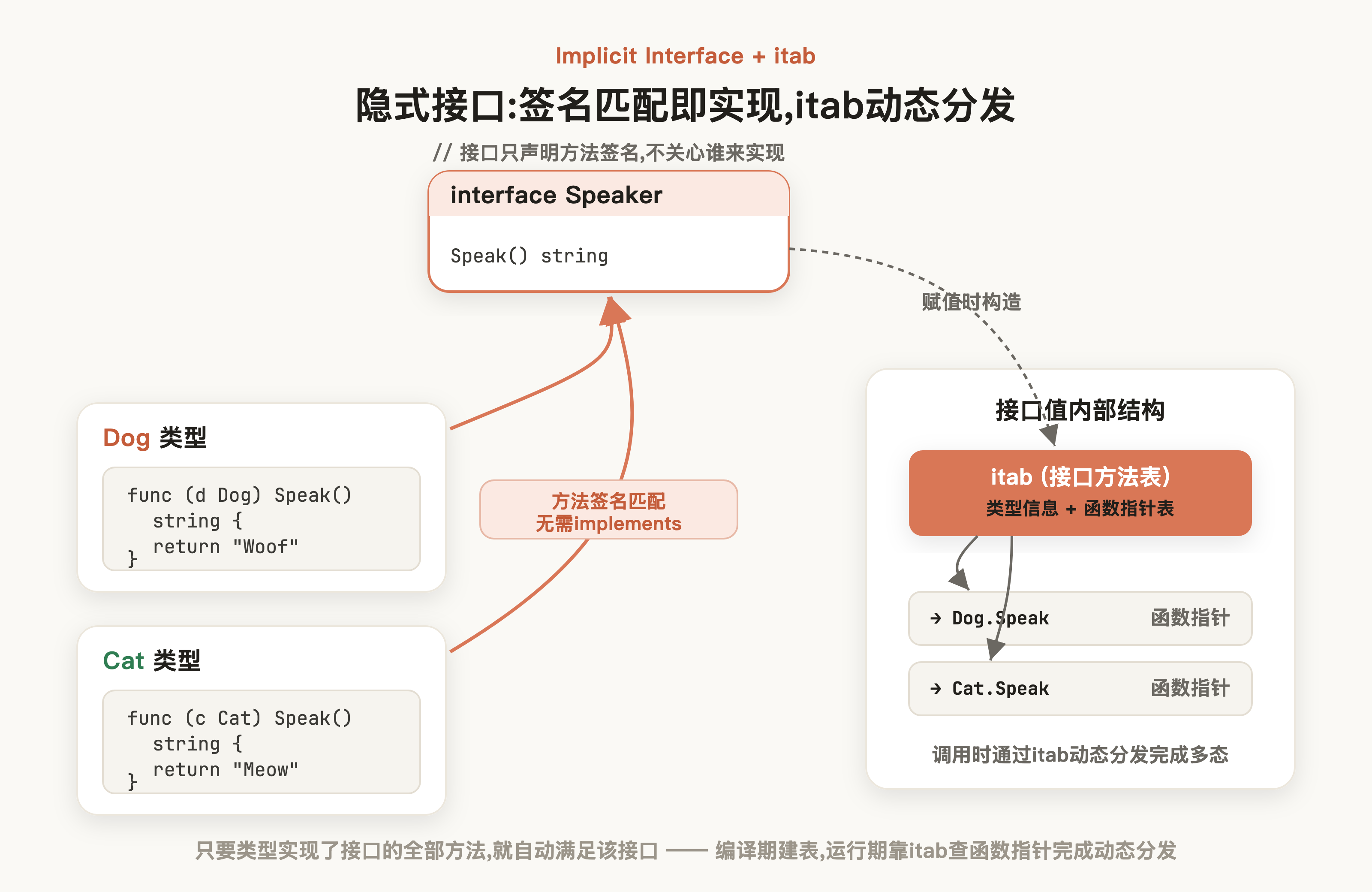
- 只要接口方法签名一致,即可认为该类型实现此接口,无需像 Java 通过implements声明
- 运行时,接口值内部持有一张 itab(接口方法表),记录了具体类型的方法函数指针。不同类型实现同一接口后,itab 指向各自的函数表,方法调用时通过 itab 做动态分发,从而完成多态。
例如我们定义了一个speak接口并声明一个返回String类型的行为能力,我们希望创建Dog和Cat类型实现这一能力:
对应代码落地步骤也很简单,首先声明接口:
type Speaker interface {
Speak() string
}
2
3
以Dog类型为例,明确Speak方法签名格式后,我们只需实现一个值接受者为Dog,方法名为Speak,返回值为string的方法,Go 语言方法签名匹配机制就会认为这个类型实现了Speaker接口,这也就是所谓的隐式接口机制:
type Dog struct{ Name string }
// 无需 implements,方法签名匹配即自动实现 Speaker 接口
func (d Dog) Speak() string {
return d.Name + ": 汪汪!"
}
2
3
4
5
6
7
基于该匹配机制,我们将Dog作为MakeSound函数入参之后,也是可以正确执行的:
// MakeSound 接收接口类型,运行时通过 itab 动态分发到具体类型的方法
func MakeSound(s Speaker) {
fmt.Println(s.Speak())
}
MakeSound(dog) // itab -> Dog.Speak
2
3
4
5
6
也正是因为这种简单灵活的规约,使得 Go 语言多态的实现简单且灵活,例如:我们声明一个Animal且带有相同签名的Speak方法,Go 语言匹配机制也会认为 Dog 属于 Animal 接口,无需像 Java 或者 C++ 那样需要通过各种关键字来显式声明:
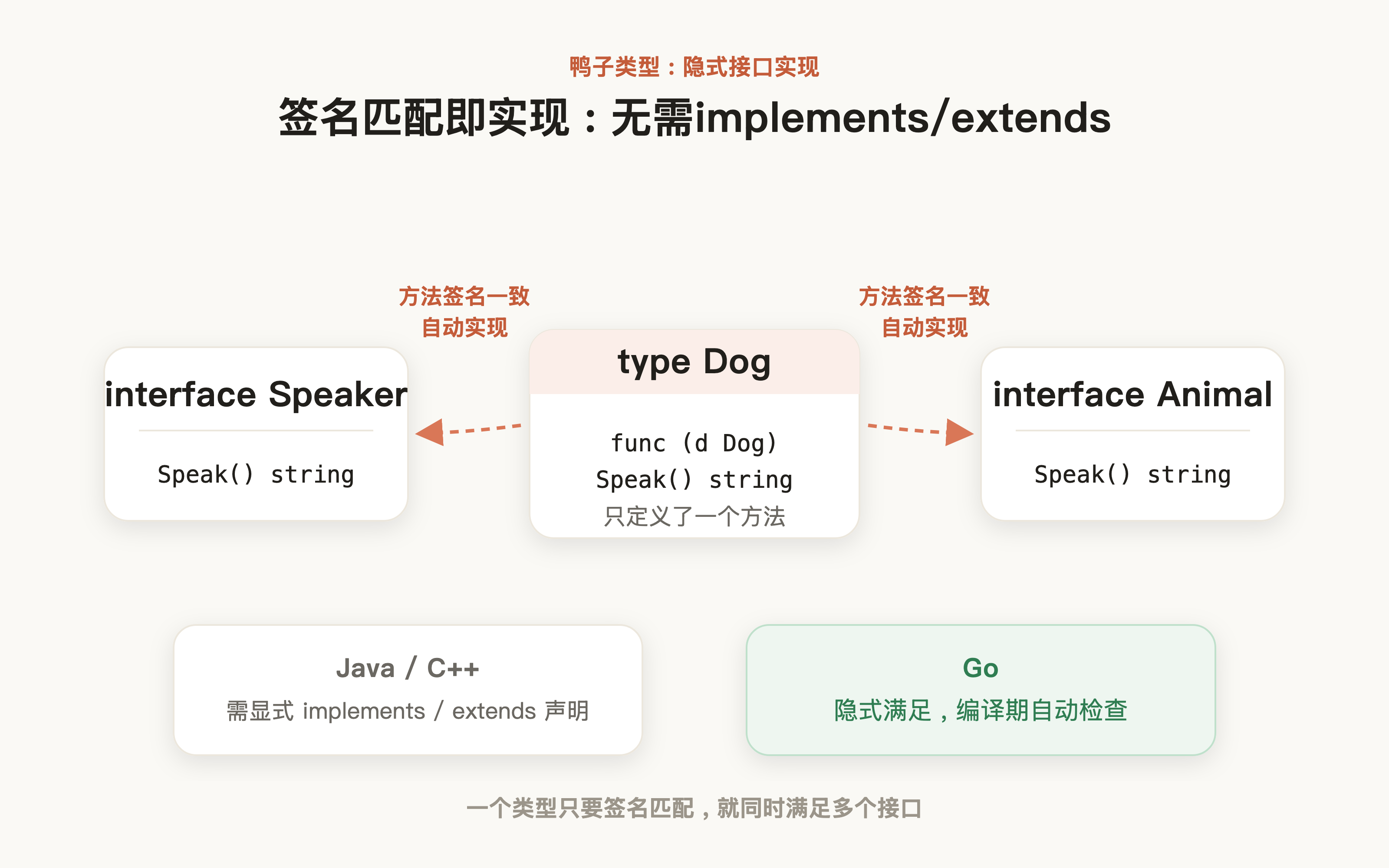
对应我们也可以通过编码来印证这一点:
type Animal interface {
Speak() string
}
2
3
4
通过隐式接口赋值,若程序正常输出,则说明dog实现了animal类型:
var a Animal = dog // 隐式接口赋值(编译器确定dog属于animal类型)
fmt.Printf("dog 实现了 Animal: %T\n", a) //正常输出,说明dog结构体实现了animal接口抽象√
2
3
# 应用生态
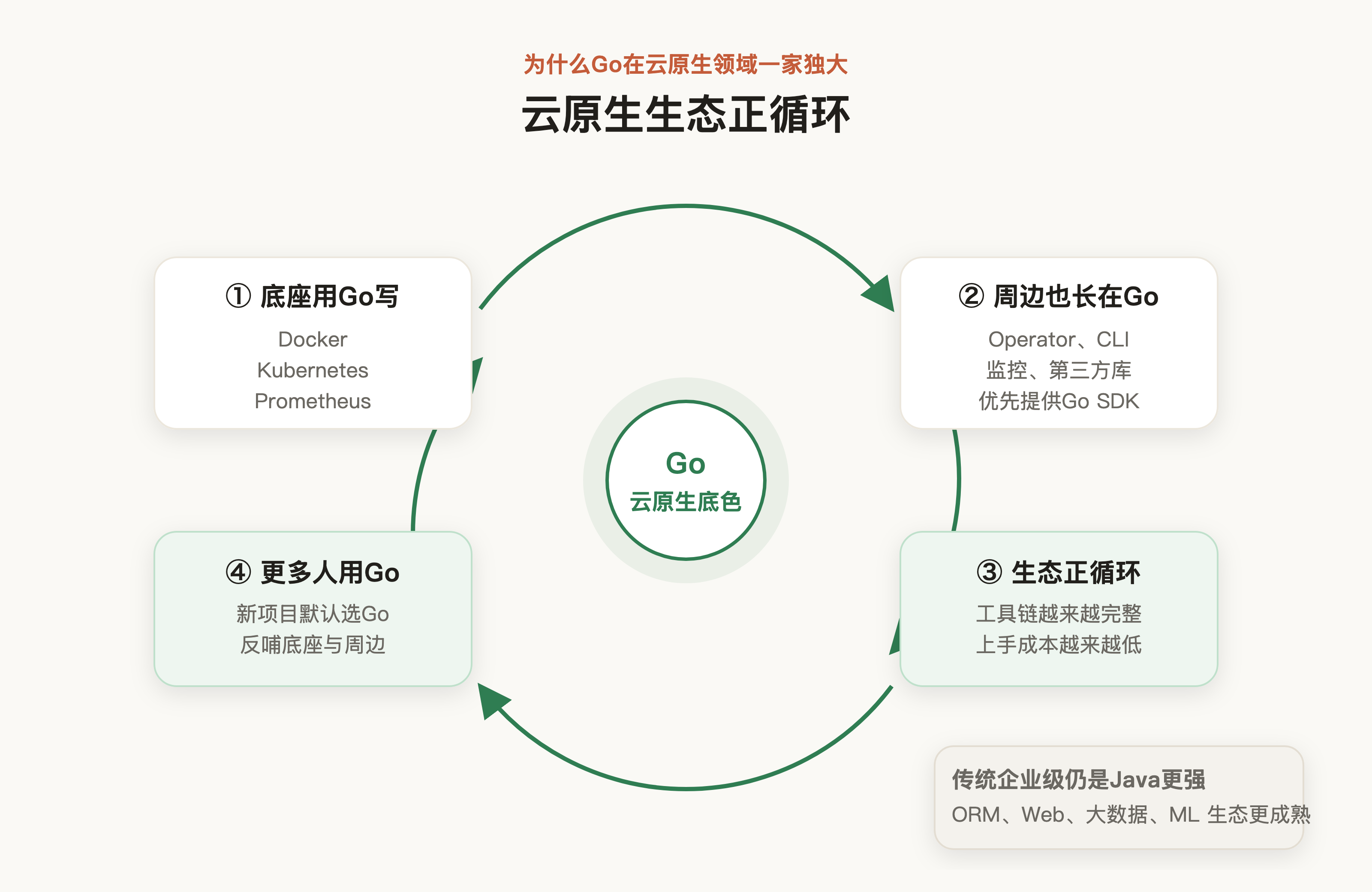
再来说说二者的生态。因为有着 Spring 这个强大的框架体系支持,Java 几乎覆盖了企业应用 Web 程序、微服务、数据、消息、安全所有的场景,所以在传统企业级应用(ORM、Web 框架、大数据/ML)上,Go 确实相对薄弱。但在云原生基础设施(Docker、Kubernetes、Prometheus)这些特定领域,Go 有着压倒性优势的生态——正因为这些底座本身就是用 Go 编写的,围绕它们的 Operator、CLI、监控组件、第三方库也几乎都长在 Go 上,逐渐形成了云原生领域难以撼动的生态正循环。
# 性能表现
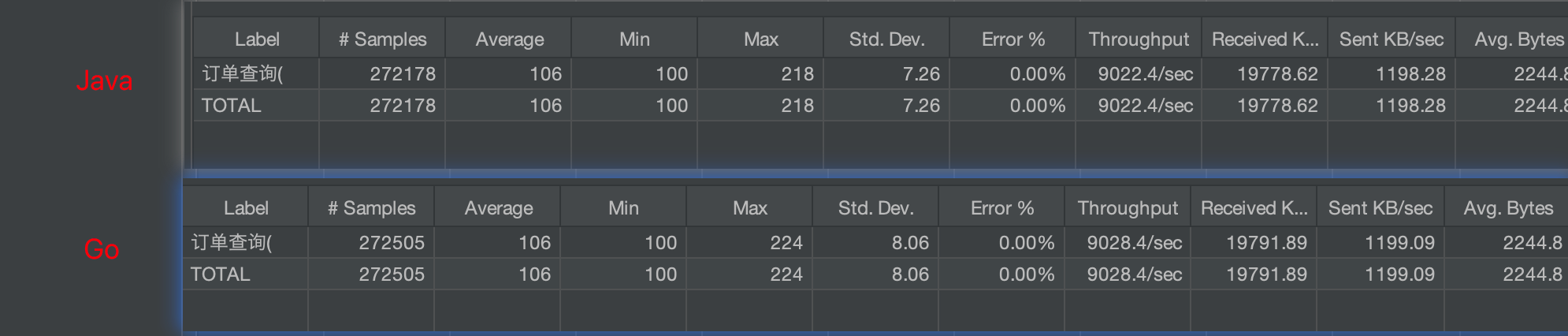
再来说说性能表现方面,JDK 21引入Virtual Threads后,Java 在IO密集型场景的并发表现已接近 Go 的goroutine。笔者在自己的Mac M4(10C32G)上做过一个压测:请求耗时100ms、并发1000的场景下,Go 和 Java 的吞吐量(throughput)均在9000左右,性能差距不大:
理论最大吞吐量计算公式如下:
最大吞吐量 = 并发数/ 请求耗时
= 1000 / 0.1s
= 10,000 req/s
2
3
实际9000约为理论值的90%,剩余10%的损耗来自框架开销、调度开销、GC以及启动时的预热等,属于合理范围。但在冷启动速度和内存占用方面,Go 毫秒级启动和MB级的内存占用远小于 Java 秒级启动+百MB级别的内存:

而在并发编程这一方面,Go 语言更着重强调简单易用,无需手动管控并发线程池、阻塞队列等并发队列存取逻辑处理,只需一个go关键字即可快速启动配合,channel和select天然表达并发协调。
我们以一个多生产者和单消费者的案例为例,该需要我们高效并发写入元素到队列中让消费者准确的消费:
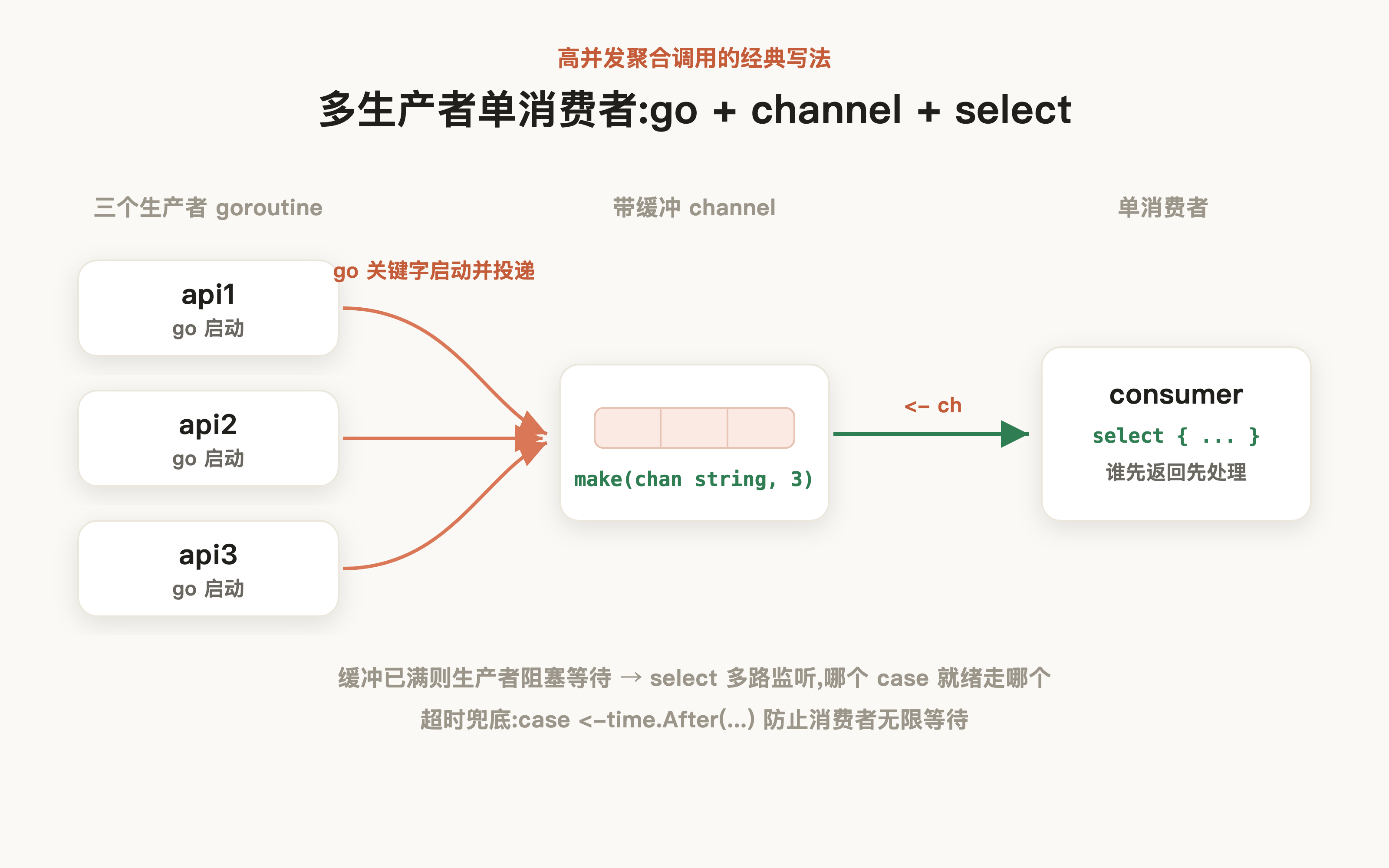
Go 语言的写法就比较简单,快速构建 channel 后,用 go 关键字启动协程投递即可:
// 创建一个缓冲通道
ch := make(chan string, 3)
// 一行启动三个并发任务
go func() { ch <- "api1" }()
go func() { ch <- "api2" }()
go func() { ch <- "api3" }()
// select天然协调:谁先返回先处理,超时兜底
for i := 0; i < 3; i++ {
select {
case result := <-ch:
fmt.Println(result)
case <-time.After(2 * time.Second):
fmt.Println("超时")
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
相比之下,Java 则稍显啰嗦,需要显式指定线程池和阻塞队列,同时还需要结合 try-with-resources 等机制优雅关闭资源:
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
BlockingQueue<String> queue = new LinkedBlockingQueue<>(3);
// 提交到阻塞队列
executor.submit(() -> queue.add("api1"));
executor.submit(() -> queue.add("api2"));
executor.submit(() -> queue.add("api3"));
// 等待所有任务完成后再消费,避免 poll 非阻塞导致提前结束
Thread.sleep(100);
String item;
while ((item = queue.poll()) != null) {
System.out.println(item);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# = 和 := 的区别?变量遮蔽问题了解吗?
= 是赋值,作用在已经声明过的变量上,:= 是短变量声明,在声明的同时由编译器根据右值自动推断类型,这也是Go简洁省心的地方:
var a int = 1 // 完整声明
a = 2 // =:给已声明的 a 重新赋值
b := 3 // :=:声明 b 并自动推断为 int,等价于 var b int = 3
2
3
这题在传统面试里不算常见,这里本着完整性补一下——真正值得留意的,是 := 背后的变量遮蔽(shadowing)问题。
在AI时代,我们大量时间花在审查AI生成的代码上,而上下文一长,AI很容易丢失其中的关键信息、偶发产出一些看着正常实则有缺陷的代码,所以面试也越来越爱考语言层面的底层细节——看你能不能在review时把这类问题揪出来,变量遮蔽就是典型的一例。
如下代码,外层声明了一个 num,在 if 内层又用 := 声明了一个同名的 num:内层这个只在 if 作用域内生效、遮蔽了外层,一旦离开 if,外层的 num 不受任何影响:

对应代码遮蔽示例如下:
num := 1 // 外层 num
if true {
num := 2 // := 在内层重新声明 num,遮蔽外层
fmt.Println(num) // 2:访问的是内层 num
}
fmt.Println(num) // 1:外层 num 未受影响
2
3
4
5
6
# Go 支持 while 循环吗?如何实现?
Go 为了保证语法的简洁、高效和可读性,仅提供for循环控制能力,通过循环参数的调整来实现while和do..while的效果,从而避免语言关键字的膨胀和概念的重复。
模拟while循环最直接的方式是使用 for condition {},即只保留条件判断:
i := 0
for i < 5 {
fmt.Println(i)
i++
}
2
3
4
5
也可以使用不带条件的for循环,配合 if + break 来控制退出:
for {
// do something
if someCondition {
break
}
}
2
3
4
5
6
对应 do {} while (条件) 的效果(至少执行一次),只需在无限for循环的逻辑末尾补充条件判断:
i := 0
for {
fmt.Printf("i = %d\n", i)
i++
if i >= 5 {
break
}
}
2
3
4
5
6
7
8
# Go允许多返回值吗?为什么?它是如何实现的
Go支持多返回值,这是语言层面的设计,不是实现细节,它让错误处理直接成为函数签名的一部分,调用方必须显式处理每一个返回值,错误不会被悄悄忽略,
实现上,Go按调用约定传递返回值。1.17之前主要走栈,1.17开始在amd64上引入了基于寄存器的调用约定,参数和返回值优先放寄存器、装不下才回退到栈,执行效率因此更高(CPU读写寄存器远快于内存),

多返回值配合命名返回值,还带来了几个工程上的优势:
- 灵活的多返回值:Go 没有在语言规范中硬性限制返回值数量,实际上限取决于编译器和调用约定
- 适配 defer:defer 函数可以在外围函数返回时直接修改命名返回值,因为返回值在函数栈帧中有明确的地址(栈传递场景下)或通过约定的寄存器/栈位置可访问
func divide(a, b int) (int, error) {
if b == 0 {
return 0, errors.New("division by zero")
}
return a / b, nil
}
func main() {
result, err := divide(10, 3)
if err != nil {
fmt.Println("error:", err)
return
}
fmt.Println("result:", result) // result: 3
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 指针的作用是什么?什么时候该用指针,什么时候不该用?
指针本质上是一个保存变量地址的类型,在C/C++里,它常用来把较大的对象传进函数,避免值拷贝的开销。
我们重点看它在Go里的使用场景和注意事项:轻量、且函数内无需修改的临时变量,直接值传递即可,而较大、或需要在函数内修改其状态的结构体,才用指针传递——因为只有拿到地址,函数内的修改才能作用到外部的同一个对象:
type Person struct {
name string
}
// 入参是指针,函数内的修改会作用到外部同一个对象
func rename(p *Person) {
p.name = "Jerry"
}
func main() {
p := Person{name: "Tom"}
rename(&p)
fmt.Println(p.name) // Jerry:外部的 p 被改到了
}
2
3
4
5
6
7
8
9
10
11
12
13
14
例如笔者好友 sharkchili 的 mini-redis,就借鉴了C的做法,把代表单条连接的重量级 redisClient 结构体,通过指针传给各个命令处理函数:
func pingCommand(c *redisClient) {
addReply(c, shared.pong)
}
2
3
因为逃逸分析优化的存在,Go 语言对于内存的自动化管理做得非常出色,结合这道问题,因为对象在没有发生函数逃逸的时候会直接在栈空间分配,所以对于小对象,我们建议直接通过值进行传递,让对象在栈间传递,避免堆内存GC的开销,提升程序性能:
func main() {
p := Person{name: "C"}
byValue(p) // 值传递,直接栈上拷贝,不存在逃逸
}
func byValue(p Person) {
fmt.Println(p.name)
}
2
3
4
5
6
7
8
9
# 切片传参是引用传参吗?使用上有什么需要注意的
这道题堪称面试杀招,它一举考察两样东西:一是你对底层数据结构和值传递的审查功底,二是对性能边界的敏感度,基础不扎实的人很容易栽。先看一段最常见的写法,大部分Java开发者初见会以为这里传的是切片引用,所以能改切片内部的元素:
// resetFirst 将切片第一个元素改为0
func resetFirst(nums []int) {
if len(nums) == 0 {
return
}
nums[0] = 0
}
2
3
4
5
6
7
实际上,Go 语言中一切都是值传递,切片传参时传入的是SliceHeader的值拷贝。只不过SliceHeader中的Data字段是一个指针,拷贝后的新SliceHeader与原切片指向同一个底层数组,所以通过Data指针修改数组元素会影响原切片:
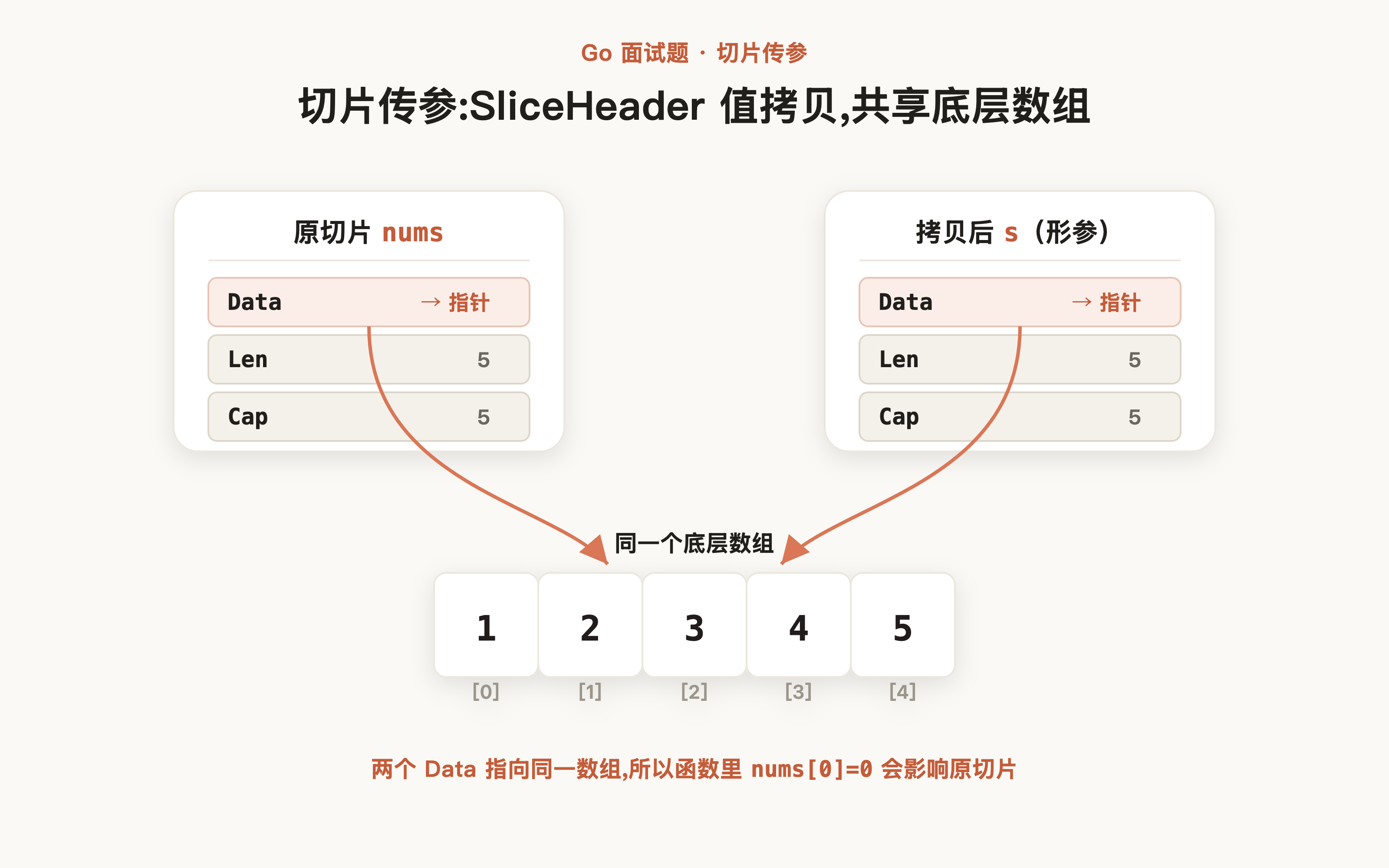
所以上述的函数我们完全可以理解为这样:
func resetFirst(s SliceHeader) {
// s 是 SliceHeader 的值拷贝,但 s.Data 与原切片指向同一底层数组
*(*int)(unsafe.Pointer(s.Data)) = 0
}
2
3
4
所以,切片元素的修改本质上仍是值拷贝(拷贝的是 SliceHeader),但编译器在底层会把元素访问转换为对共享底层数组的指针操作,因此函数内的修改会直接影响外部切片:
func main() {
arr := []int{1, 2, 3, 4, 5}
modify(arr)
fmt.Println(arr[0]) // 100
}
func modify(arr []int) {
arr[0] = 100
}
2
3
4
5
6
7
8
9
10
在 AI 高速发展的情况下,面试官非常喜欢考察候选人对技术的理解深度,确保候选人在高效使用 AI 的同时,还能及时纠正一些潜藏较深的问题。所以谈及切片的使用注意事项,我们可以从切片值传递和动态扩容两种情况来说明。
先说情况 1:切片值传递。切片在函数内做元素追加(append)时,因为 len 是值拷贝,函数内修改的只是副本的 len,所以仅函数内部正确追加了元素,而外部切片的 len 还是 3,导致无法通过正常下标访问到新元素:
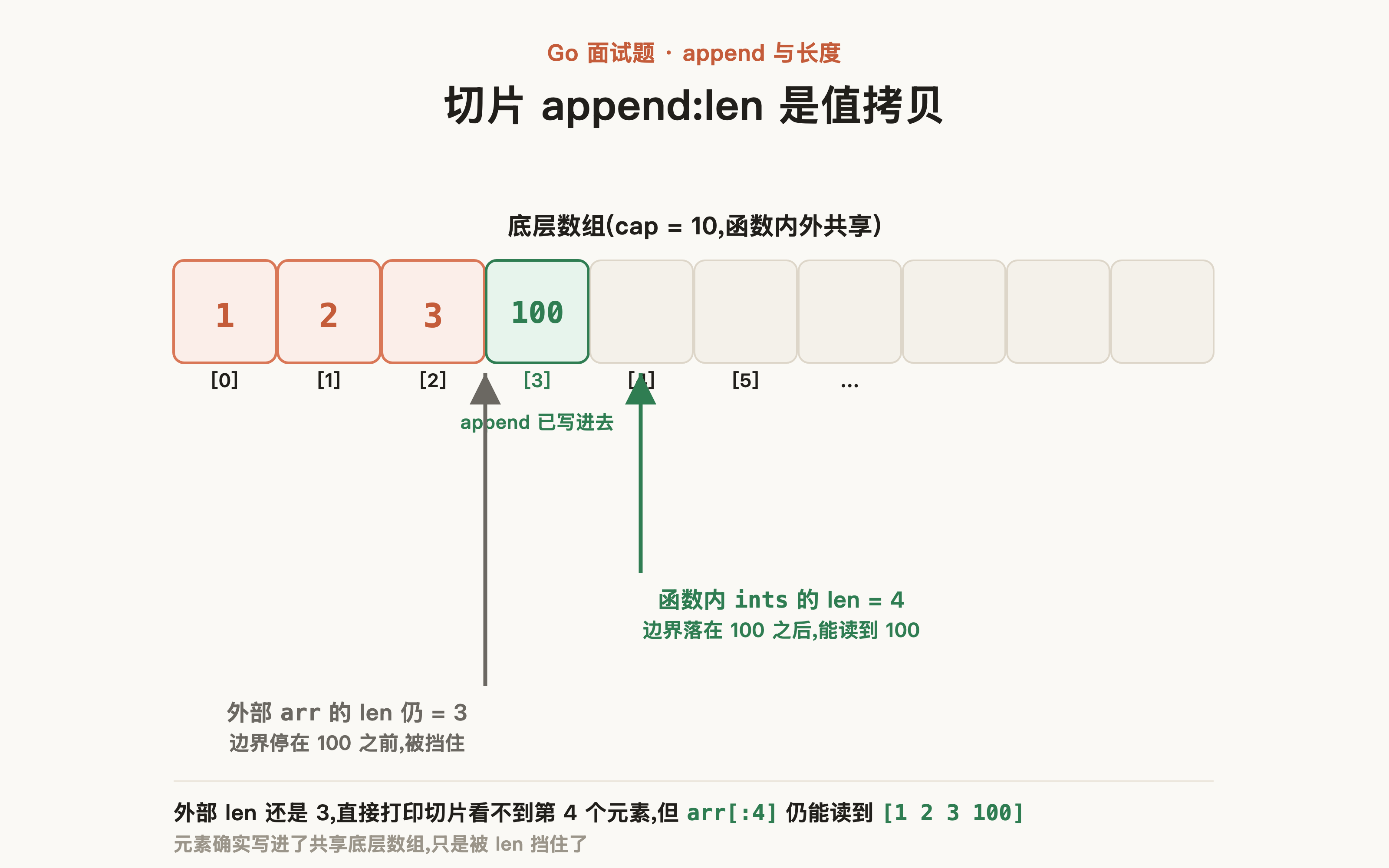
如下代码,函数内追加了 100,因为 len 是值拷贝,外部 len 还是 3,未能正常打印出第 4 个元素,但通过 arr[:4] 仍能访问到它——说明这个元素确实被写进了共享的底层数组,只是被外部的 len 挡住了。
func main() {
arr := make([]int, 3, 10)
arr[0] = 1
arr[1] = 2
arr[2] = 3
appendVal(arr)
fmt.Println("arr len:", len(arr), "elements:", arr) //arr len: 3 elements: [1 2 3]
fmt.Println(arr[:4]) //[1 2 3 100]
}
func appendVal(arr []int) {
ints := append(arr, 100)
fmt.Println("ints len:", len(ints), "elements:", ints) // ints len: 4 elements: [1 2 3 100]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
另一个潜藏问题是动态扩容:当函数内 append 触发扩容时,函数内的切片会指向一个全新的底层数组来装填元素。由于切片是值传递,外部切片仍指向旧数组,完全感知不到这次扩容——此时函数内正确追加并输出,外部既看不到新元素,强制用 arr[:4] 访问还会因越界直接 panic:
func main() {
//显式指定容量和长度为3
arr := make([]int, 3, 3)
arr[0] = 1
arr[1] = 2
arr[2] = 3
appendVal(arr)
fmt.Println("arr len:", len(arr), "elements:", arr) //arr len: 3 elements: [1 2 3]
fmt.Println(arr[:4]) //panic: runtime error: slice bounds out of range [:4] with capacity 3
}
func appendVal(arr []int) {
ints := append(arr, 100)
fmt.Println("ints len:", len(ints), "elements:", ints) // ints len: 4 elements: [1 2 3 100]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 能不能给我简单介绍一下defer关键字?defer执行顺序给我讲讲
defer关键字会在所在函数返回时执行,所以它最适合用来做资源释放这类事后清理,官方文档原话:
A defer statement pushes a function call onto a list. The list of saved calls is executed after the surrounding function returns. Defer is commonly used to simplify functions that perform various clean-up actions.
先看Java的做法:从Java 7开始,try-with-resources能自动关闭实现了AutoCloseable的资源,这是Java里资源清理的标准实践:
public class IODemo {
public static void copyFile(String src, String dest) {
// 多个资源用分号分隔,按声明的逆序关闭
try (
InputStream in = new FileInputStream(src);
OutputStream out = new FileOutputStream(dest)
) {
byte[] buffer = new byte[1024];
int len;
while ((len = in.read(buffer)) != -1) {
out.write(buffer, 0, len);
}
} catch (IOException e) {
e.printStackTrace();
}
// in 和 out 都会自动关闭,先关 out,再关 in(逆序)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Go没有走try-with-resources那条路,而是更直接:用defer关键字做"事后清理",
官方建议把defer紧跟在资源创建之后写,而不是堆在函数末尾,这样不容易漏掉:
func CopyFile(dstName, srcName string) (written int64, err error) {
src, err := os.Open(srcName)
if err != nil {
return
}
defer src.Close() // 最佳实践:资源获取后立即 defer 释放,避免遗漏
dst, err := os.Create(dstName)
if err != nil {
return // 即使这里错误返回,src.Close() 也会被执行
}
defer dst.Close()
return io.Copy(dst, src) // 函数返回前,自动执行 dst.Close() 和 src.Close()
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
这也是比较经典的实践,日常用AI编码时,可以把"资源获取后立即defer释放"写进rules来约束AI的输出,减少后续排错成本,
# 多个 defer 的执行顺序是怎样的?
执行顺序上,defer遵循LIFO,也就是后进先出、像栈一样,官方在defer-panic-and-recover一文里也明确说明了:
Deferred function calls are executed in Last In First Out order after the surrounding function returns
所以我们在一段循环中,利用defer+闭包捕获i延迟输出数字i时,对应的执行过程为:
- 依次遍历数字0、1、2、3压入栈中
- 函数返回
- 不断从栈顶抛出并输出3、2、1、0
for i := 0; i < 4; i++ {
//闭包写法,按引用捕获i的值
defer func() {
fmt.Print(i) // defer is LIFO => 3210
}()
}
2
3
4
5
6
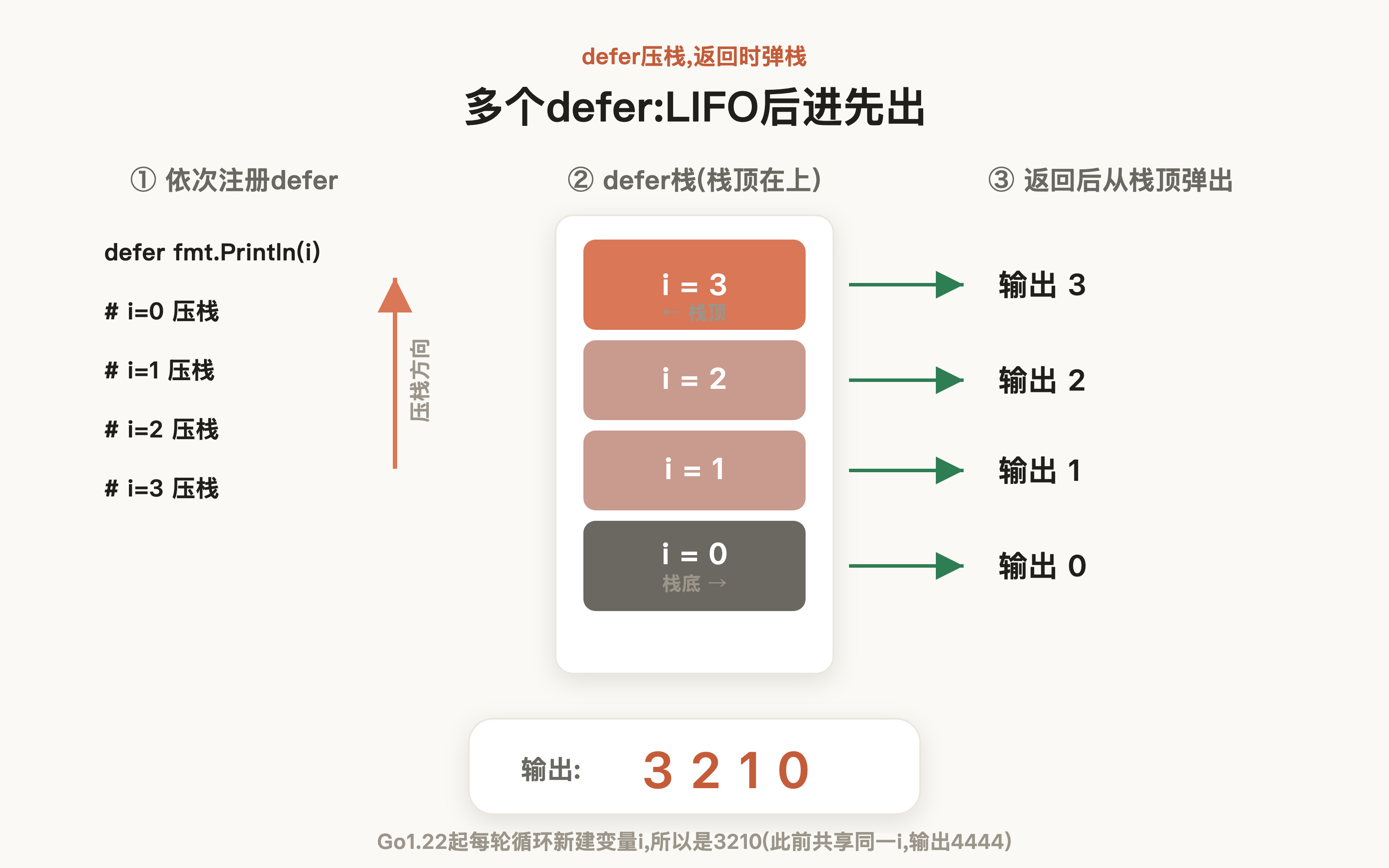
需要补充说明的是,上述行为仅针对 Go 1.22 及之后的版本,在此之前,Go 在整个循环中只创建一个变量 i,所有闭包按引用捕获的都是同一个 i,循环结束时 i 已自增到 4,因此最终输出是 4、4、4、4。
# defer 在什么时机会修改返回值?
defer能不能改返回值,关键在于理解return不是一步完成的,它分三步:先赋值返回值,再执行defer,最后才真正返回,正因为defer插在赋值之后、返回之前,所以它有机会改写命名返回值:
func foo() (result int) {
defer func() { result++ }()
return 1
}
func main() {
fmt.Println(foo()) // 输出 2,而非 1
}
2
3
4
5
6
7
8
执行过程是这样的:return 1 先把result赋成1,接着defer把result自增到2,最后函数才真正返回2。
还要注意,defer只能改命名返回值(named return value),如果返回值没有命名,defer根本访问不到、也改不了它:
func bar() int {
result := 1
defer func() { result++ }()
return result // 返回 1,defer 修改的是局部变量 result,不影响返回值
}
2
3
4
5
# Go 有异常类型吗?为什么?
Go 中没有"异常(Exception)"的概念,只有"错误(Error)"。Go 本着简单的原则,对于错误的处理一贯通过判断逻辑来处理,从而避免 Java 那种try-catch-finally不同类型捕获的繁琐逻辑:
func main() {
err := foo()
if err != nil {
fmt.Println(err)
}
}
func foo() error {
return nil
}
2
3
4
5
6
7
8
9
10
当然,Go 语言也支持自定义错误类型,对应步骤为:
- 声明错误结构体
- 实现error接口的
Error() string方法
// 自定义错误类型,只需实现 Error() string 方法即可
type MyError struct {
Code int
Msg string
}
func (e *MyError) Error() string {
return fmt.Sprintf("[错误码:%d] %s", e.Code, e.Msg)
}
2
3
4
5
6
7
8
9
使用时,直接创建返回即可。例如这段年龄判断的逻辑,若小于0要返回自定义错误,则直接通过 &MyError 创建错误对象并返回指针:
func checkAge(age int) error {
if age < 0 {
return &MyError{Code: 400, Msg: "年龄不能为负数"}
}
return nil
}
2
3
4
5
6
后续的错误处理逻辑,我们可以在if逻辑中通过类型断言判断错误类型,进行个性化处理:
func main() {
err := checkAge(-1)
if err != nil {
fmt.Println(err) // [错误码:400] 年龄不能为负数
// 类型断言获取自定义字段
if e, ok := err.(*MyError); ok {
fmt.Println("code:", e.Code, "msg:", e.Msg)
}
}
// 简单错误:errors.New 和 fmt.Errorf
fmt.Println(errors.New("简单错误"))
fmt.Println(fmt.Errorf("用户 %s 不存在", "张三"))
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
注意:Go 1.13引入了 errors.Is 和 errors.As,这是目前官方推荐的错误判断方式。当错误被 %w 包装后(如 fmt.Errorf("xxx: %w", err)),传统的 == 比较和类型断言会失效,必须使用这两个函数才能正确匹配。
// errors.Is:判断错误链中是否包含某个特定的错误值
var ErrNotFound = errors.New("not found")
func query() error {
return fmt.Errorf("query failed: %w", ErrNotFound)
}
err := query()
if errors.Is(err, ErrNotFound) {
fmt.Println("找到了") // 支持错误链解包
}
// errors.As:从错误链中提取特定类型的错误
var myErr *MyError
err = checkAge(-1)
if errors.As(err, &myErr) {
fmt.Println("code:", myErr.Code) // 支持错误链解包
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
简单说,判断错误值用errors.Is、判断错误类型用errors.As,它们替代了旧的err == target和err.(*MyError),而且都能顺着%w包装的错误链一层层解包,这是老写法做不到的

# Go 在哪些场景会出现 panic?
panic是Go的内置函数,用来终止运行时的异常流程,调用panic后,当前函数后续流程中断(但defer照常执行),然后一层层往外抛,直到整个goroutine返回、程序崩溃,
Panic is a built-in function that stops the ordinary flow of control and begins panicking. When the function F calls panic, execution of F stops, any deferred functions in F are executed normally, and then F returns to its caller. To the caller, F then behaves like a call to panic. The process continues up the stack until all functions in the current goroutine have returned, at which point the program crashes. Panics can be initiated by invoking panic directly. They can also be caused by runtime errors, such as out-of-bounds array accesses.
panic有点像Java的RuntimeException,区别在于:Java的能被catch后继续运行,而Go的panic一旦没被recover接住,整个程序直接崩:
最常见的就是空指针:
type Person struct {
name string
}
func main() {
var p *Person
fmt.Println(p.name) //panic: runtime error: invalid memory address or nil pointer dereference
}
2
3
4
5
6
7
8
然后是非法的算术,注意这里的写法:故意先用变量存0再相除,而不是直接写100/0。因为Go对常量除0做了校验,编译期看到除数字面量是0会直接编译失败,这样就演示不了运行时的panic:
num := 100
divisor := 0
fmt.Println(num / divisor) // panic: runtime error: integer divide by zero
2
3
还有些标准库函数参数不合法时也会panic,比如rand.Intn入参<=0:
fmt.Println(rand.Intn(0)) //panic: invalid argument to Intn
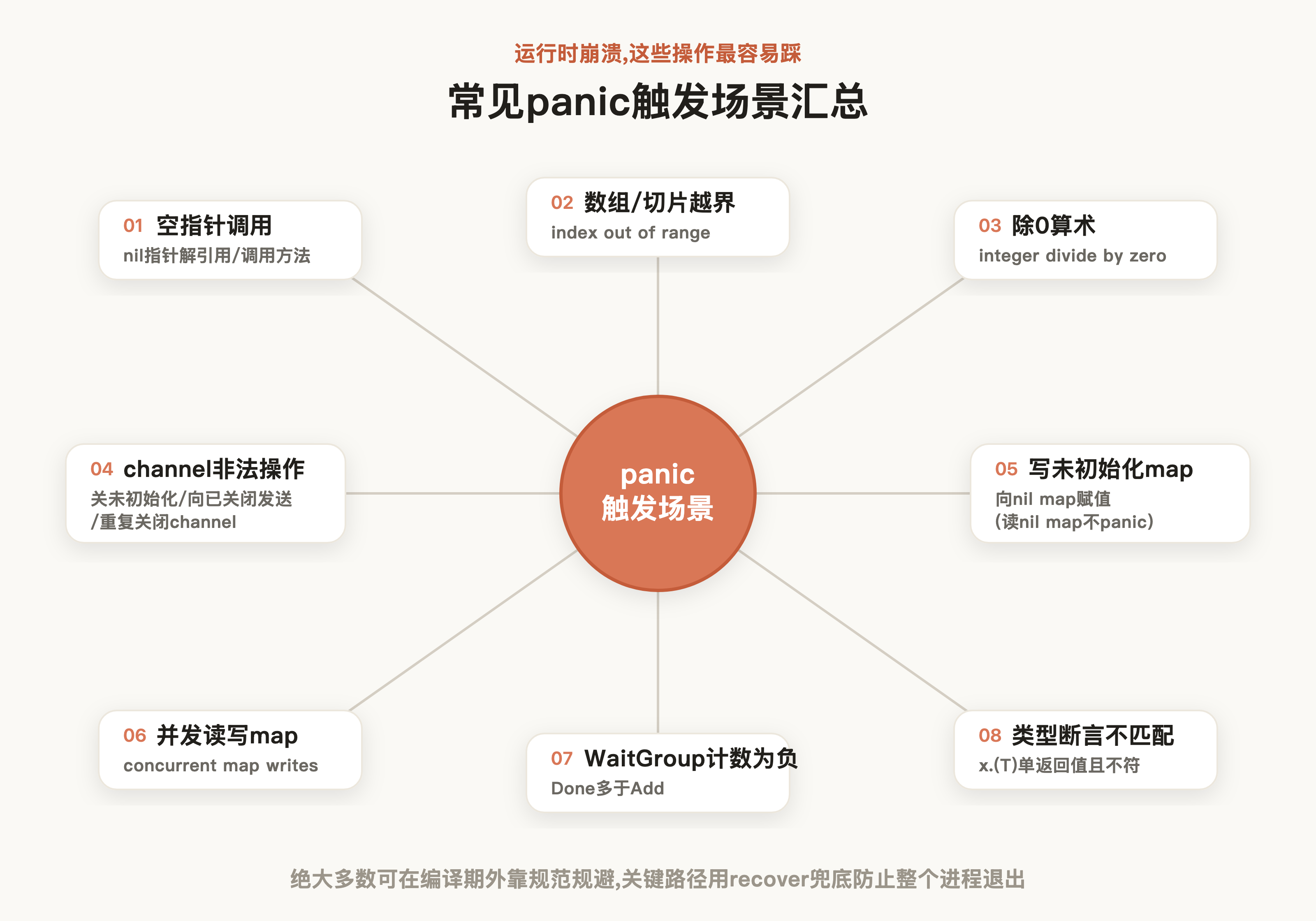
总的来说,Go的运行时异常大多通过panic触发,常见场景有:
- 空指针调用
- 数组/切片越界
- 除 0 算术异常
- 未能在正确的状态访问资源,最经典就是channel的处理:关闭未初始化的 channel、向已经关闭的 channel 发送数据、重复关闭 channel
- 写未初始化的map:读nil map是安全的、返回值类型的零值(比如map[string]string读出来是空串),但往里写会panic,因为底层哈希表还没分配:
var m map[string]string
fmt.Println("key", m["key"])
m["key"] = "value" //panic: assignment to entry in nil map
2
3
- 并发读写 map(Go 的map不是并发安全的,需要加锁或使用sync.Map)
- sync 计数为负数,即sync.WaitGroup重复执行done导致计数逻辑异常
var wg sync.WaitGroup
wg.Add(1)
wg.Done()
wg.Done() // panic: sync: negative WaitGroup counter
2
3
4
5
- 类型断言不匹配,即将接口指向的类型转为其他类型并使用,建议使用
s, ok := i.(int)进行前置检查:
var i interface{} = "hello"
// 不安全:直接断言,类型不匹配会panic
s := i.(int) // panic: interface conversion: interface {} is string, not int
// 安全:使用 comma-ok 模式进行前置检查
s, ok := i.(int) // ok 为 false,不会panic
if !ok {
fmt.Println("类型断言失败")
}
2
3
4
5
6
7
8
9
10
关于defer和panic更多知识点,可以看到官网的文档:https://go.dev/blog/defer-panic-and-recover (opens new window)
# Go是面向对象语言吗?什么时候用函数,什么时候用方法
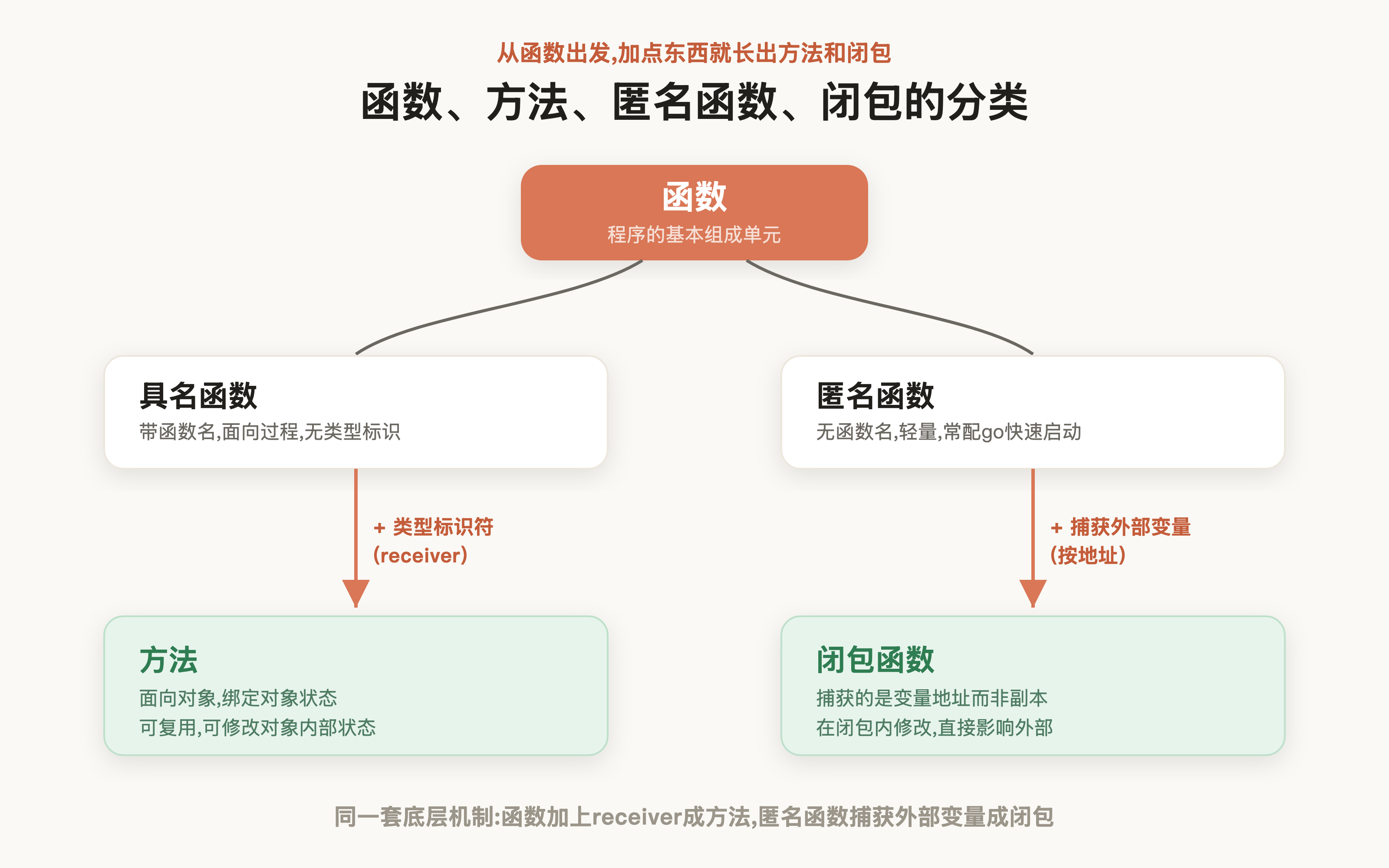
Go不是传统意义上的纯面向对象语言:它没有类、没有继承,但它保留了OO最核心的东西——用结构体封装数据、用方法给类型挂行为、用接口表达抽象,换句话说,Go砍掉了继承这套复杂体系,把OO做轻了,
所以这道题真正想考的,是你在面向过程和面向对象之间的取舍:什么时候该用函数(无接收者),什么时候该用方法(挂在类型上)? 大方向是——逻辑只依赖入参、不读写任何对象状态,就写成函数,依赖少、好测试、AI也更容易生成正确且可复用的版本,逻辑要读写某个类型的状态,就写成这个类型的方法,行为和状态绑在一起,
在AI时代这一点尤其值得审:让AI写代码时,它常犯两个错——一是把本该是纯工具函数的逻辑硬塞进某个struct方法(平白造出无意义的状态依赖),二是反过来,把需要操作对象状态的事写成了无状态函数(结果状态改不动)。review时能不能一眼看出这种"函数/方法的归属划错了",就是判断设计功底的地方
下面先把函数、方法、匿名函数、闭包的基本形态理清,再看怎么选,
# 具名函数
函数可理解为一组操作序列,是程序基本组成部分,又可分为具名函数和匿名函数,具名函数即带有参数、返回值和函数名,如下所示:
/*
*
入参:a b
函数名:swap
返回值:int int
*/
func swap(a, b int) (int, int) {
return b, a
}
2
3
4
5
6
7
8
9
具名函数基础之上,结合面向对象的概念又衍生了方法的概念,与函数唯一的区别就是方法在函数名前面带有类型标识,即将方法依托于类型上,通过静态编译完成绑定。
例如:我们上文的交换函数,若希望该方法被封装为对象的一个行为,则需要在方法名前面声明类型:
type NumUtil struct {
}
func (nu *NumUtil) swap(a, b int) (int, int) {
return b, a
}
2
3
4
5
6
7
使用示例如下所示:
nu := NumUtil{}
a, b := nu.swap(1, 2) //2 1
fmt.Println(a, b)
2
3
# 匿名函数
匿名函数即没有函数名的函数,常用于启动一个轻量、简单的并发任务,只需一个go关键字+匿名函数即可快速启动:
go func() {
fmt.Println("在后台运行的任务")
}()
2
3
需要注意的是,当匿名函数引用了外部变量而非以IIFE(Immediately Invoked Function Expression,立即调用函数表达式)传递时,它捕获的是该变量的地址而非值拷贝,所有对变量的修改都会直接影响外部,这种函数我们称为闭包函数:
wg := sync.WaitGroup{}
wg.Add(1)
//声明一个变量num
num := 1
//执行一个闭包函数,修改num的值
go func() {
num *= 10
wg.Done()
}()
wg.Wait()
fmt.Println("num:", num)//num: 10
2
3
4
5
6
7
8
9
10
11
12
13
14
15
对应IIFE表达式传参示例如下,读者务必仔细阅读理解二者区别:
num := 1
func(num int) {
num++
fmt.Println("num=", num) //num= 2
}(num)
fmt.Println("num=", num) //num= 1
2
3
4
5
6
7
8
# 二者区别
来简单小结一下二者的区别,通过是否带有类型标识符我们可以拆解出函数和方法,函数作为面向过程的编程范式,不带有任何类型标识符,可直接声明使用。而方法则是面向对象思想下的产物,为保证以对象维度复用和修改内部状态,方法名前带有类型标识符。
匿名函数则是函数的最简形式,它本着轻量、简单的理念,常用于协程的快速启动,根据是否捕获外部变量进而衍生出闭包函数的概念:
# Go为什么把方法接收者放在方法名前面?能从设计上解释吗
这道题问的是Go最显眼的语法设计:Java是receiver.method(),C++是Class::method(),而Go偏偏把接收者写在方法名前面——func (r Type) method(),为什么?
答案藏在Go和C的渊源里。C没有面向对象的语法,但fopen、fclose这种函数,都把要操作的对象(FILE*)当作第一个参数传进去,这其实已经是"方法绑在对象上"的雏形:
FILE *fopen( const char *filename, const char *mode );
int fclose( FILE *stream );
2
3
4
Go沿用了这个思路,只是把那个"第一个参数"提到了括号里、起了个正式的名字叫receiver(receiver前置、和参数列表分开,一眼就能看出方法绑在哪个类型上、用的是值接收者还是指针接收者),这也是Go"显式优于隐式"的体现:值接收者(r Type)和指针接收者(r *Type)的区别直接写在签名最前面,不藏着掖着,
func (f *File) Close() error {
if f == nil {
return ErrInvalid
}
return f.file.close()
}
// read reads up to len(b) bytes from the File.
// It returns the number of bytes read and an error, if any.
func (f *File) read(b []byte) (n int, err error) {
n, err = f.pfd.Read(b)
runtime.KeepAlive(f)
return n, err
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# GOROOT 和 GOPATH 有什么用?
无论是初学者还是有编程经验的开发者,每次提及这个问题的时候还是会有所疑惑。当然,你也可以认为这是一道无用的八股文,但笔者想借这道题强调的,是它背后真正考察的东西——对技术本质刨根问底的理解能力。
结合二者的语义,GOROOT强调的是"根"的理念,即 Go 语言一切的根源,所以GOROOT代表 Go 的安装路径,包含了标准库和工具链。我们可以通过命令来验证:
$ go env GOROOT
/usr/lib/go-1.22
$ ls /usr/lib/go-1.22
VERSION api bin go.env misc pkg src test
2
3
4
5
其中 bin/ 存放工具链(go、gofmt)等:
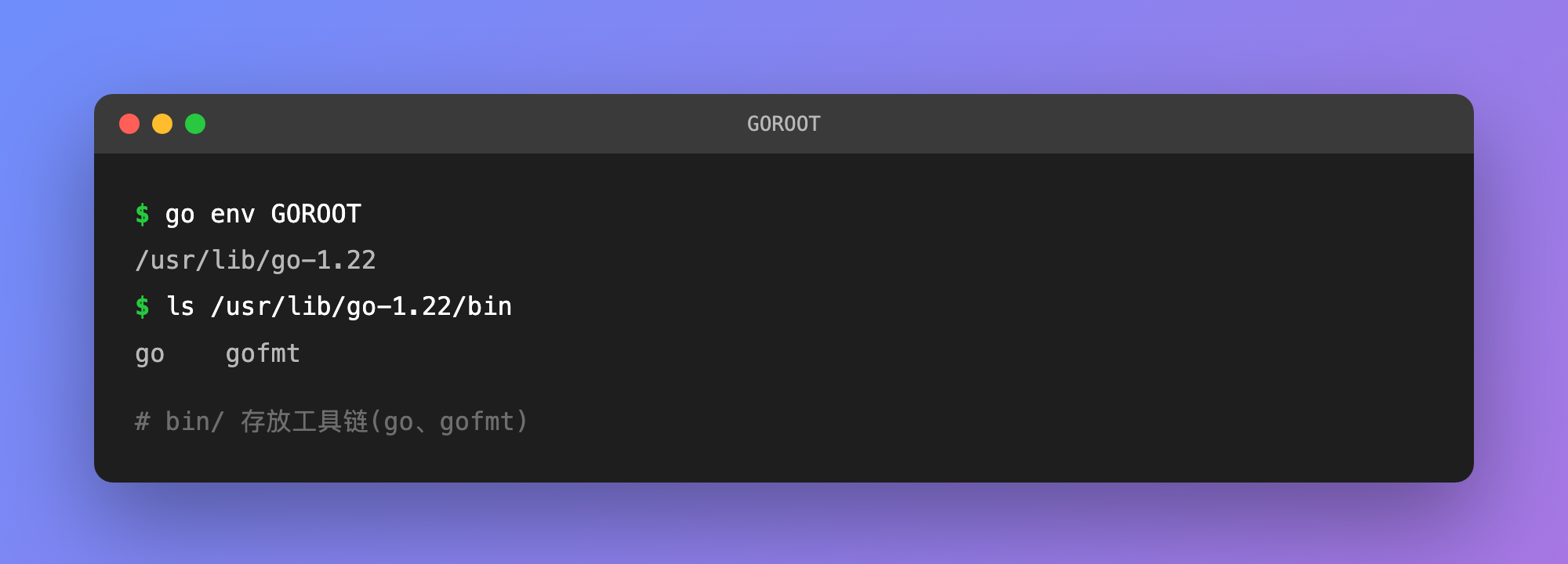
src/ 存放标准库源码(fmt、net/http、os等),这也印证了GOROOT确实是 Go 语言一切的"根":
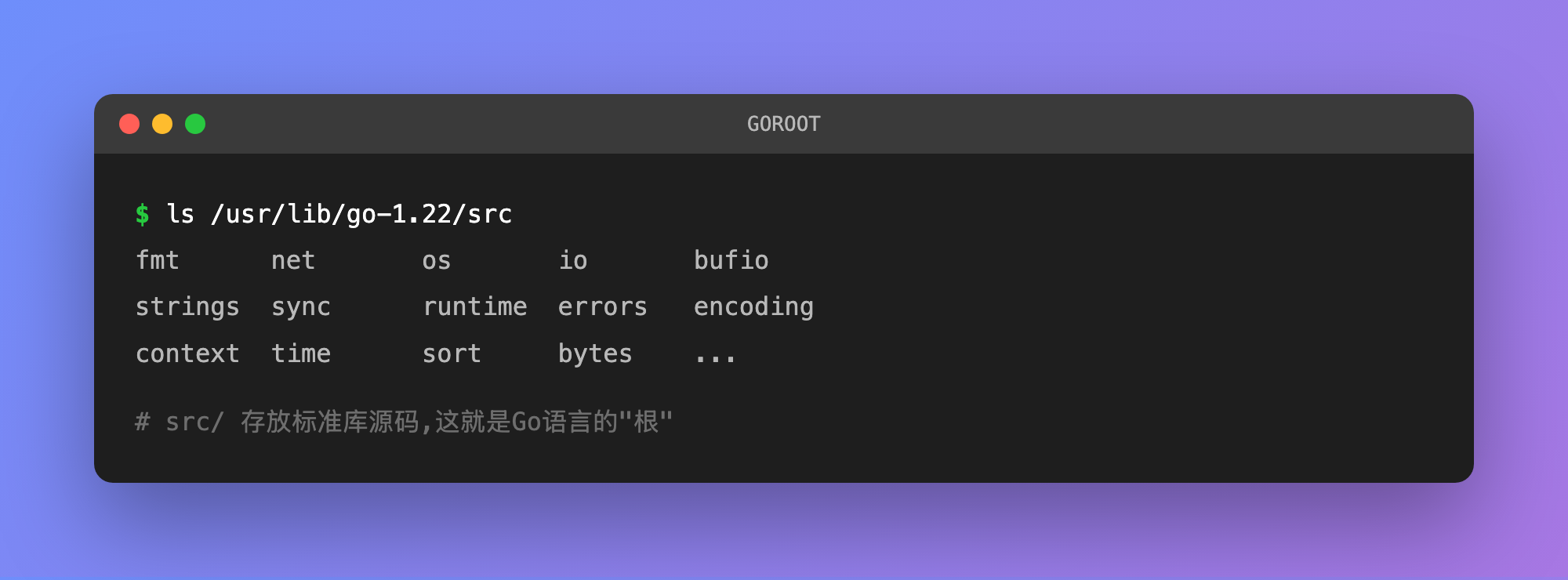
同理,GOPATH强调的是"路径"的概念,它是一个工作空间(workspace),用于管理项目源码和第三方依赖。GOPATH可以设置多个目录,按照 Go 官方的要求,GOPATH下需要包含三个文件夹:
- src:存放源代码文件
- pkg:存放编译后的库文件
- bin:存放可执行文件
注意:自 Go 1.16默认启用 Go Modules后,项目不再强制要求放在GOPATH/src下,开发者可以在任意目录管理项目。GOPATH目前主要用于go install安装工具的默认存放位置和模块缓存路径。简单来说,GOROOT告诉 Go 去哪里找标准库,GOPATH告诉 Go 去哪里找你的代码和第三方依赖。
从设计演进的角度看,GOPATH → vendor → Go Modules 的变迁,本质上是一个从"全局共享"到"项目隔离"的依赖管理演进过程。GOPATH 时代所有项目共享同一个依赖目录,无法实现项目级别的版本隔离,vendor 机制通过在项目中拷贝依赖实现了隔离,但引入了重复存储和更新困难的问题,Go Modules 通过 go.mod 文件声明依赖版本,配合最小版本选择(MVS)算法,最终在隔离性和可维护性之间找到了平衡。
# Go 单元测试有哪些规范?
Go把测试工具直接内置进了工具链,所有Go项目的测试写法完全一致,没有JUnit还是TestNG那种选型纠结,
AI时代有个很实际的变化:大部分业务代码交给AI生成,我们写的更多是测试——靠TDD用测试把需求描述清楚、驱动AI把实现写对,所以这道题的重点不在怎么写测试,而在怎么review:能不能看懂AI产出的测试、判断它是否覆盖了边界、断言是否到位,要做到这些,先得熟悉Go测试的基本规范:
- 文件名必须以
_test.go结尾 - 测试函数必须以
Test开头,参数为t *testing.T - 测试文件与被测文件在同一个包(同一目录下,package声明相同)
例如:我们的main包下有个calc.go的计算工具类:
package main
// Add 两数相加
func Add(a, b int) int {
return a + b
}
// IsPositive 判断是否为正数
func IsPositive(n int) bool {
return n > 0
}
2
3
4
5
6
7
8
9
10
11
12
对应的编写步骤为:
- 声明
calc_test.go文件 - 测试加法的函数为
TestAdd,入参为t *testing.T - 测试文件与被测文件在同一目录
对应代码示例如下:
import "testing"
func TestAdd(t *testing.T) {
result := Add(1, 2)
expected := 3
if result != expected {
// t.Errorf 报告失败但继续执行后续测试
t.Errorf("Add(1, 2) = %d, want %d", result, expected)
}
}
func TestIsPositive(t *testing.T) {
if !IsPositive(1) {
t.Errorf("IsPositive(1) = false, want true")
}
// t.Fatalf 报告失败并立即停止当前测试函数
if IsPositive(-1) {
t.Fatalf("IsPositive(-1) = true, want false")
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
运行测试:
$ go test -v ./...
=== RUN TestAdd
--- PASS: TestAdd (0.00s)
=== RUN TestIsPositive
--- PASS: TestIsPositive (0.00s)
PASS
2
3
4
5
6
# 基本数据类型
# uint8 类型为什么会溢出?
基本类型问题主要是考察候选人,特定场景对不同业务数据精度的把控能力,是一种针对性能和准确性能力的综合体现。
针对uint的溢出问题,我们还是要从其底层存储的视角出发。
与 Java 不同,对于整数类型,Go 将其分为不同的精度,其中uint8即无符号8位整数,范围为0~255。当值达到255时,其二进制表示为 11111111,此时若再加1,结果为 100000000(9位),但uint8只有8位,最高位被截断,剩下 00000000 = 0,这就是溢出:
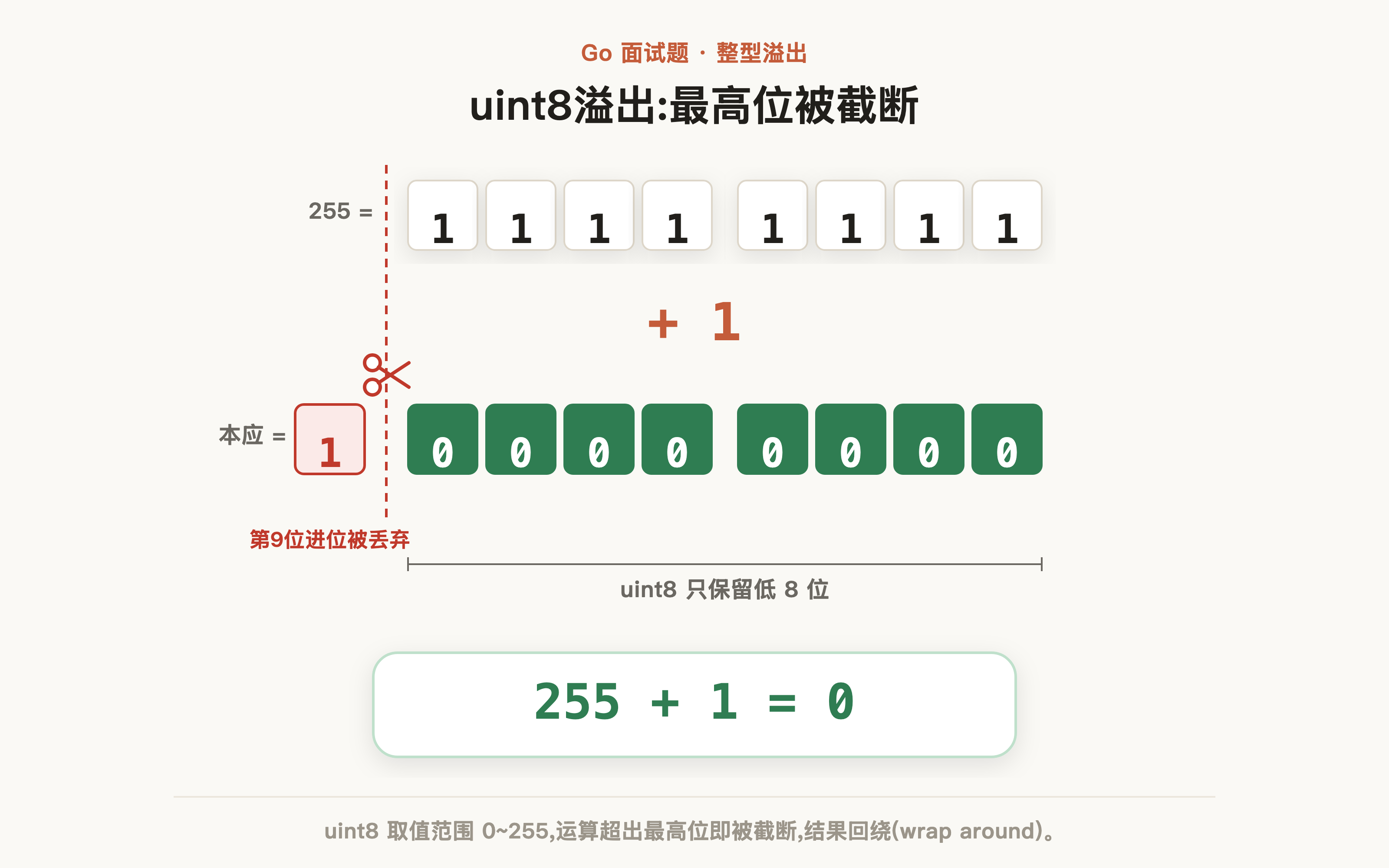
对应我们也给出代码示例印证:
var num uint8
num = 255
fmt.Println(num + 1)//0
2
3
# 能介绍下 rune 类型吗?
针对rune类型的考察,是查看候选人对于 Go 语言源码的掌握程度,以及对于不同编码和字符串管理的理念,按照现有主流的编码范围:
- ascii:仅占用7bit,共128个码位,涵盖英文字母、数字、标点和控制字符
- unicode:则是ascii的超集,包含世界上各种书写系统的所有字符
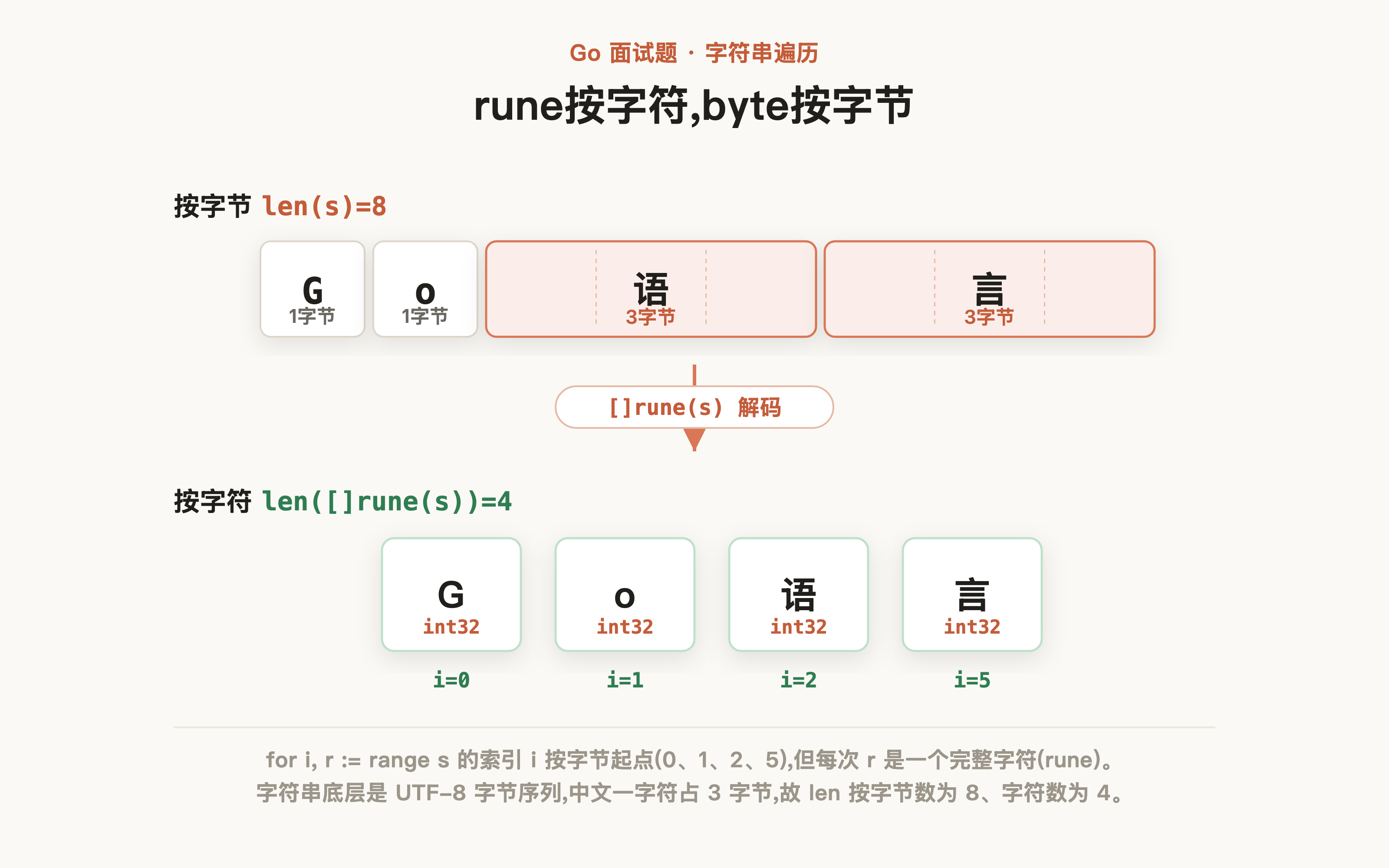
- utf8:变长编码(1~4 字节),中文字符通常占 3 个字节
在 Go 语言中默认编码为UTF-8,为更好地表示Unicode范围内的所有字符,故采用int32来表示,同时为了语义化字符串的4字节字符类型,设计者将这种类型称之为rune,对应也可以在源代码builtin.go中印证这一点:
// rune is an alias for int32 and is equivalent to int32 in all ways. It is
// used, by convention, to distinguish character values from integer values.
type rune = int32
2
3
将字符串转为 []rune 后,每个中文字符会被解码为一个独立的 int32 值,由此保证字符串索引以字符为一个原子,确保语义化遍历的高效性:
s := "Go语言"
fmt.Println(len([]rune(s))) // 4:按字符计数,G + o + 语 + 言
// 按字符遍历
for i, r := range s {
fmt.Printf("索引%d: %c (Unicode: U+%04X)\n", i, r, r)
}
2
3
4
5
6
7
输出结果如下,可以看到按照rune准确的将字符串按照字符进行划分,同时遍历时也是严格按照字符进行逐个遍历:
4
索引0: G (Unicode: U+0047)
索引1: o (Unicode: U+006F)
索引2: 语 (Unicode: U+8BED)
索引5: 言 (Unicode: U+8A00)
2
3
4
5
同时,为了印证 Go 语言字符默认采用UTF-8编码也这一说法,我们也可以通过len函数印证:
fmt.Println(len(s)) //8:按字节计数,G(1) + o(1) + 语(3) + 言(3)
2
3
# Go 里面的 int 和 int32 是同一个概念吗?
可能很多人认为int和int32都是4字节,实际上这题考察的是候选人对于操作系统的理解。Go 语言中的int是一种平台相关的类型,其大小取决于底层系统的位数:
- 32位系统:int = 4字节,与int32相同
- 64位系统:int = 8字节,与int64相同
而int32是固定4字节的,与系统位数无关。所以在64位系统上,int和int32并不是同一个概念,int能表示的数值范围比int32更大。在需要明确整数大小的场景(如网络协议、文件格式等),建议使用int32/int64等固定大小的类型,而非int。

对应我们也给出 int 在 64 位系统下字节数的印证代码:
var x int = 1
fmt.Println(unsafe.Sizeof(x)) // 输出 8
2
# Go 语言中如何表示枚举值(enums),有什么需要注意的?
一般情况下对于简单的枚举都是通过const+()来做到连续标识,默认从0开始,后续的所有枚举都跟随该枚举递增:
const (
zero = iota
one = iota
)
func main() {
fmt.Println(zero, one)// 0 1
}
2
3
4
5
6
7
8
9
10
不过实际开发里 iota 还有几个更常用、面试也爱追问的点。
iota 在每个 const 块里从0开始,换一个 const 块就重置,而且同一行的表达式可以省略不写,会自动沿用上一行:
const (
A = iota // 0
B // 1:省略后自动沿用 iota 表达式
C // 2
)
const ( // 新的 const 块,iota 重新从0计
X = iota // 0
)
2
3
4
5
6
7
8
9
用 _ 可以跳过不需要的值,常见于丢弃0或跳过保留位,配合 1 << iota 还能一行表达出 KB/MB/GB 这种按位递增的量级:
const (
_ = iota // 丢弃 0
KB = 1 << (10 * iota) // 1 << 10
MB // 1 << 20
GB // 1 << 30
)
2
3
4
5
6
最后一个工程上更值得注意的点:上面这些枚举底层都是 int,缺乏类型安全——任意 int 都能传进去。要做类型安全枚举,可以定义独立类型,再配一个 String() 方法让它自解释:
type Weekday int
const (
Sunday Weekday = iota
Monday
Tuesday
)
func (d Weekday) String() string {
return []string{"周日", "周一", "周二"}[d]
}
func main() {
var d Weekday = Monday
fmt.Println(d) // 周一:实现 String() 后,打印自动走该方法
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
这样 Weekday 在类型系统里就和普通 int 区分开了,函数入参写 Weekday 就拒绝了任意整数,既防错又自带可读输出。
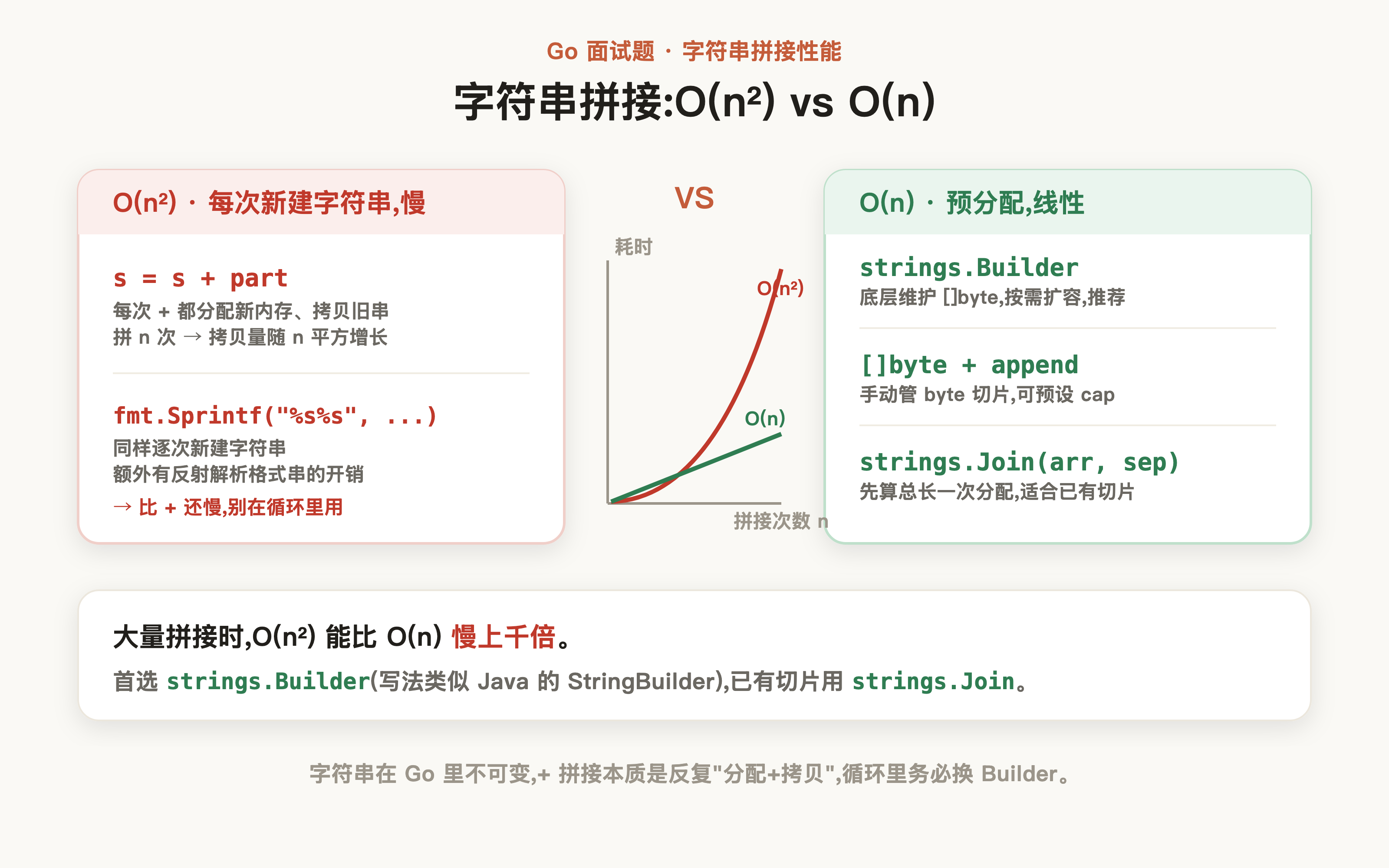
# 如何高效地拼接字符串?
考察候选人对于字符串底层实现理解,无论是 Java 还是 Go,字符串底层的存储都是采用字节数组管理,一般情况下字符串拼接有如下几种方式:
- 符号"+":每次
+都创建一个全新字符串,将左右两侧内容拷贝进去。N次拼接的内存分配和拷贝次数为 O(n²),大量拼接时性能最差 fmt.Sprintf:通过占位符界定模板,入参经过interface{}装箱后利用反射解析类型,再完成格式化拼接。除了和+一样的 O(n²) 拷贝开销,还额外承担了反射解析的开销。strings.Builder:底层维护一个[]byte切片,通过Grow()预分配足够的容量,拼接时直接 append 到切片末尾,几乎不需要扩容。最终转字符串时直接基于底层 byte 数组构造,零拷贝[]byte拼接:手动管理 byte 切片,预分配足够容量后直接 append。本质上strings.Builder就是对[]byte的封装,因此裸[]byte的性能是理论天花板strings.Join:底层同样通过 byte 切片拼接,适合将一个字符串切片一次性合并为单个字符串。内部会先计算总长度再预分配,避免了多次扩容
对应我们也给出测试的源代码:
func main() {
const n = 10000 // 拼接次数
parts := make([]string, n)
for i := range parts {
parts[i] = fmt.Sprintf("str%d", i)
}
// 1. + 拼接:每次都创建新字符串,O(n²)内存分配和拷贝,大量拼接性能最差
start := time.Now()
var s1 string
for _, p := range parts {
s1 += p
}
fmt.Printf("+ 拼接: %v\n", time.Since(start))
// 2. fmt.Sprintf:通过占位符拼接,参数经interface{}装箱+反射解析,与+同属O(n²)量级
start = time.Now()
var s2 string
for _, p := range parts {
s2 = fmt.Sprintf("%s%s", s2, p)
}
fmt.Printf("fmt.Sprintf: %v\n", time.Since(start))
// 3. strings.Builder:底层[]byte切片预分配,O(n)拼接,零拷贝转字符串
start = time.Now()
var builder strings.Builder
builder.Grow(n * 10) // 预分配容量,减少扩容次数
for _, p := range parts {
builder.WriteString(p)
}
_ = builder.String()
fmt.Printf("strings.Builder: %v\n", time.Since(start))
// 4. []byte 拼接:strings.Builder的底层实现,预分配后直接append,理论最快
start = time.Now()
buf := make([]byte, 0, n*8)
for _, p := range parts {
buf = append(buf, p...)
}
_ = string(buf)
fmt.Printf("[]byte 拼接: %v\n", time.Since(start))
// 5. strings.Join:底层也是[]byte切片预分配拼接,适合将字符串切片一次性合并
start = time.Now()
_ = strings.Join(parts, "")
fmt.Printf("strings.Join: %v\n", time.Since(start))
// 防止编译器优化掉未使用的变量
_ = s1
_ = s2
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
来简单小结一下,[]byte、strings.Builder、strings.Join 这三种底层都是byte切片预分配、O(n)线性增长,性能最好,差距只在封装开销,而fmt.Sprintf和+每次拼接都新建字符串、是O(n²),大量拼接时能慢上千倍,所以对性能有较高要求、又希望团队协作阅读成本低,优先考虑strings.Builder,它对Java开发也比较友好,写法和StringBuilder几乎一样
# Go 编译相关的命令详解
# Go 编译常见指令有哪些?
就像计算机专业必修的编译原理课程一样,本题主要考察候选人对于 Go 语言底层机制的理解深度。掌握编译过程和相关指令,有助于从更底层的视角处理和优化日常研发工作,例如理解逃逸分析对性能的影响、读懂编译器给出的优化提示等。
总的来说,Go 语言有3个比较常见的指令分别是:
- go build:编译包及其依赖,对main包生成可执行文件,对非main包只检查编译是否通过
- go install:编译并安装包及其依赖,将生成的可执行文件放到
$GOPATH/bin(或$GOBIN),将编译后的包文件放到缓存中 - go run:编译并直接运行 Go 源文件,适用于开发调试阶段,不会在当前目录留下可执行文件
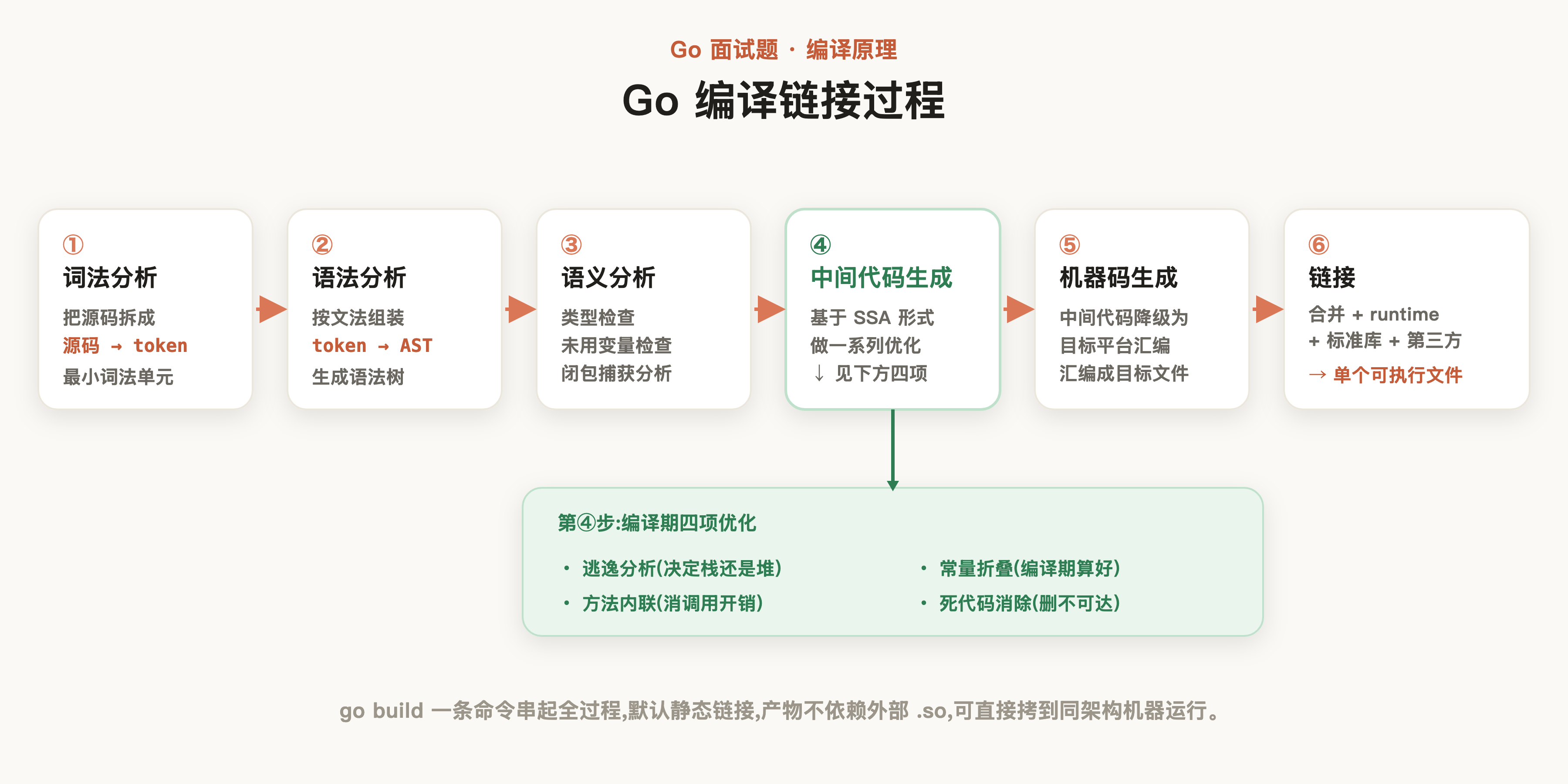
# Go 的编译链接过程是怎样的?
大部分使用 Go 语言的开发者一般只会在八股文中学习了解这一点,实际上,掌握一个语言的编译和链接步骤,会让你以更底层的视角处理和优化日常研发工作。
对于 Go 语言的编译链接过程,我们从一个开发好的代码说起,假设我们现在存在如下加法代码段:
x := 1 + 2
首先是进行词法分析,词法分析会将一条代码段拆分为数个token:
IDENT("x"), ASSIGN(":="), INT("1"), ADD("+"), INT("2"), SEMICOLON(";")
2
然后是语法分析,将上述的token尝试构建为一棵AST语法树,确保语法是否正确:
:= (赋值)
/ \
x + (加法)
/ \
1 2
2
3
4
5
6
7
接下来是语义分析(type checking):
- 类型检查:是否存在不同类型的错误运算,例如:int+String
- 未使用变量导入检查
- 闭包变量捕获分析
然后是中间代码生成,该步骤会在正式执行代码之前,进行一些可控的优化工作,例如:
- 逃逸分析:确定对象分配是位于堆还是位于栈
- 方法内联:将简单的函数调用直接替换为函数体本身,避免函数调用的跳转开销
- 常量折叠:将编译期可计算的常量表达式直接计算出结果,避免运行时重复计算
- 死代码消除:移除永远不会被执行到的代码分支,减小最终二进制文件的体积
明确完成上述所有校验和优化工作之后,最后就是生成可执行的机器码。然后将编译产物与标准库(runtime、OS相关包等)和第三方依赖全部链接起来,生成最终的可执行程序。
总结一下,Go 语言编译过程为:
- 词法分析
- 语法分析
- 语义分析
- 中间代码生成
- 机器码生成
- 链接并生成可执行文件
# 参考
GOALNG_INTERVIEW_COLLECTION: https://github.com/mao888/golang-guide/blob/main/golang/go-Interview/GOALNG_INTERVIEW_COLLECTION.md interview-go: https://github.com/lifei6671/interview-go Go 语言的多返回值是如何实现的?: https://blog.csdn.net/2301_78841354/article/details/156361479 Go 出现panic的场景: https://www.cnblogs.com/paulwhw/p/15585467.html Go 中 while 和 do..while 的实现: https://blog.csdn.net/chengqiuming/article/details/115573947 golang常见面试题: https://blog.csdn.net/qq_67503717/article/details/136386099 Why did you create a new language? - Go FAQ: https://go.dev/doc/faq#creating_a_new_language 《Go 语言高级编程(第2版)》
